[Fluent python] Chapter 3. Dictionaries and Sets
Chúng ta sử dụng dictionaries trong tất cả các chương trình Python. Nếu không trực tiếp trong code, thì gián tiếp bởi vì kiểu dict là một phần cơ bản trong cách triển khai của Python. Các thuộc tính của Class và instance, namespaces của module, và các keyword arguments của hàm là một số cấu trúc cốt lõi của Python được biểu diễn bằng dictionaries trong bộ nhớ. __builtins__.__dict__ lưu trữ tất cả các kiểu, đối tượng và hàm tích hợp sẵn.
Do vai trò quan trọng của chúng, các dicts trong Python được tối ưu hóa cao — và tiếp tục được cải thiện. Hash tables là động cơ đằng sau hiệu suất cao của dicts trong Python. Các kiểu dữ liệu tích hợp sẵn khác dựa trên hash tables là set và frozenset. Chúng cung cấp các API và toán tử phong phú hơn so với các sets mà bạn có thể đã gặp trong các ngôn ngữ phổ biến khác. Đặc biệt, các sets trong Python triển khai tất cả các phép toán cơ bản từ lý thuyết tập hợp, như hợp, giao, kiểm tra tập con, v.v. Với chúng, chúng ta có thể thể hiện các thuật toán theo cách khai báo hơn, tránh nhiều vòng lặp lồng nhau và câu lệnh điều kiện.
Table of content
- Modern dict Syntax
- 1.1. dict Comprehensions
- 1.2. Unpacking Mappings
- 1.3. Merging Mappings with |
- Pattern Matching with Mappings
- Standard API of Mapping Types
- API chuẩn của các kiểu ánh xạ (Mapping Types)
- Automatic Handling of Missing Keys
- Các biến thể của dict
- 6.1. collections.OrderedDict
- 6.2. collections.ChainMap
- 6.3. collections.Counter
- 6.4. shelve.Shelf
- 6.5. Subclassing UserDict Instead of dict
- Immutable Mappings
- Dictionary Views
- Practical Consequences of How dict Works
- Set Theory
- 10.1. Set Literals
- 10.2. Set Comprehensions
- Practical Consequences of How Sets Work
- 11.1. Set Operations
- Set Operations on dict Views
1. Modern dict Syntax
1.1. dict Comprehensions
Kể từ Python 2.7, cú pháp của listcomps và genexps đã được điều chỉnh cho dict comprehensions (và cả set comprehensions, mà chúng ta sẽ sớm tìm hiểu). Một dictcomp (dict comprehension) xây dựng một instance dict bằng cách lấy các cặp key:value từ bất kỳ iterable nào.
Ví dụ 3-1 cho thấy cách sử dụng dict comprehensions để xây dựng hai dictionaries từ cùng một danh sách các tuples.
Ví dụ 3-1. Ví dụ về dict comprehensions
>>> dial_codes = [
...(880, 'Bangladesh'),
...(55, 'Brazil'),
...(86, 'China'),
...(91, 'India'),
...(62, 'Indonesia'),
...(81, 'Japan'),
...(234, 'Nigeria'),
...(92, 'Pakistan'),
...(7,'Russia'),
...(1,'United States'),]
>>> country_dial = {country: code for code, country in dial_codes}
>>> country_dial
{'Bangladesh': 880, 'Brazil': 55, 'China': 86, 'India': 91, 'Indonesia': 62,
'Japan': 81, 'Nigeria': 234, 'Pakistan': 92, 'Russia': 7, 'United States': 1}
>>> {code: country.upper()
...
for country, code in sorted(country_dial.items())
...
if code < 70}
{55: 'BRAZIL', 62: 'INDONESIA', 7: 'RUSSIA', 1: 'UNITED STATES'}
Một iterable gồm các cặp key-value như dial_codes có thể được truyền trực tiếp đến constructor của dict, nhưng…
…ở đây chúng ta hoán đổi các cặp: country là key, và code là value.
Sắp xếp country_dial theo tên, đảo ngược các cặp một lần nữa, viết hoa các values, và lọc các mục có code < 70.
Nếu bạn đã quen với listcomps, dictcomps là một bước tiếp theo tự nhiên. Nếu bạn chưa quen, thì việc mở rộng cú pháp comprehension có nghĩa là bây giờ việc thành thạo nó sẽ có lợi hơn bao giờ hết.
1.2. Unpacking Mappings
PEP 448—Additional Unpacking Generalizations đã tăng cường hỗ trợ cho việc unpacking mappings theo hai cách, kể từ Python 3.5.
Đầu tiên, chúng ta có thể áp dụng ** cho nhiều hơn một đối số trong một lệnh gọi hàm. Điều này hoạt động khi tất cả các keys đều là chuỗi và duy nhất trên tất cả các đối số (vì các keyword arguments trùng lặp bị cấm):
>>> def dump(**kwargs):
...
return kwargs
...
>>> dump(**{'x': 1}, y=2, **{'z': 3})
{'x': 1, 'y': 2, 'z': 3}
Thứ hai, ** có thể được sử dụng bên trong một dict literal — cũng nhiều lần:
>>> {'a': 0, **{'x': 1}, 'y': 2, **{'z': 3, 'x': 4}}
{'a': 0, 'x': 4, 'y': 2, 'z': 3}
Trong trường hợp này, các keys trùng lặp được phép. Các lần xuất hiện sau sẽ ghi đè lên các lần xuất hiện trước đó — hãy xem giá trị được ánh xạ tới x trong ví dụ.
Cú pháp này cũng có thể được sử dụng để hợp nhất các mappings, nhưng có những cách khác. Vui lòng đọc tiếp.
1.3. Merging Mappings with |
Python 3.9 hỗ trợ sử dụng | và |= để hợp nhất các mappings. Điều này hợp lý, vì đây cũng là các toán tử hợp của set.
Toán tử | tạo ra một mapping mới:
>>> d1 = {'a': 1, 'b': 3}
>>> d2 = {'a': 2, 'b': 4, 'c': 6}
>>> d1 | d2
{'a': 2, 'b': 4, 'c': 6}
Thông thường, kiểu của mapping mới sẽ giống với kiểu của toán hạng bên trái —d1 trong ví dụ — nhưng nó có thể là kiểu của toán hạng thứ hai nếu các kiểu do người dùng định nghĩa có liên quan, theo các quy tắc quá tải toán tử mà chúng ta sẽ khám phá trong Chương 16.
Để cập nhật một mapping hiện có tại chỗ, hãy sử dụng |=. Tiếp tục từ ví dụ trước, d1 đã không bị thay đổi, nhưng bây giờ nó sẽ là:
>>> d1
{'a': 1, 'b': 3}
>>> d1 |= d2
>>> d1
{'a': 2, 'b': 4, 'c': 6}
2. Pattern Matching with Mappings
Câu lệnh match/case hỗ trợ các đối tượng là mapping. Các mẫu cho mapping trông giống như khai báo dict, nhưng chúng có thể khớp với các instance của bất kỳ lớp con thực tế hoặc ảo nào của collections.abc.Mapping.
Trong Chương 2, chúng ta chỉ tập trung vào các mẫu chuỗi, nhưng các loại mẫu khác nhau có thể được kết hợp và lồng vào nhau. Nhờ vào việc giải cấu trúc, so khớp mẫu là một công cụ mạnh mẽ để xử lý các bản ghi được cấu trúc giống như các mapping và chuỗi lồng nhau, mà chúng ta thường cần đọc từ các API JSON và cơ sở dữ liệu với lược đồ bán cấu trúc, như MongoDB, EdgeDB hoặc PostgreSQL. Ví dụ 3-2 minh họa điều đó. Các gợi ý kiểu đơn giản trong get_creators cho thấy rõ ràng rằng nó nhận một dict và trả về một list.
Ví dụ 3-2. creator.py: get_creators() trích xuất tên của người tạo từ các bản ghi phương tiện
def get_creators(record: dict) -> list:
match record:
case {'type': 'book', 'api': 2, 'authors': [*names]}:
return names
case {'type': 'book', 'api': 1, 'author': name}:
return [name]
case {'type': 'book'}:
raise ValueError(f"Invalid 'book' record: {record!r}")
case {'type': 'movie', 'director': name}:
return [name]
case _:
raise ValueError(f'Invalid record: {record!r}')
# Khớp với bất kỳ mapping nào có 'type': 'book', 'api': 2 và key 'authors'
# được ánh xạ tới một chuỗi. Trả về các mục trong chuỗi, dưới dạng một list mới.
# Khớp với bất kỳ mapping nào có 'type': 'book', 'api': 1 và key 'author'
# được ánh xạ tới bất kỳ đối tượng nào. Trả về đối tượng bên trong một list.
# Bất kỳ mapping nào khác có 'type': 'book' là không hợp lệ, raise ValueError.
# Khớp với bất kỳ mapping nào có 'type': 'movie' và key 'director' được ánh xạ tới
# một đối tượng duy nhất. Trả về đối tượng bên trong một list.
# Bất kỳ đối tượng nào khác là không hợp lệ, raise ValueError.
Ví dụ 3-2 cho thấy một số cách thực hành hữu ích để xử lý dữ liệu bán cấu trúc như các bản ghi JSON:
- Bao gồm một trường mô tả loại bản ghi (ví dụ:
'type': 'movie') - Bao gồm một trường xác định phiên bản lược đồ (ví dụ:
'api': 2) để cho phép sự phát triển trong tương lai của các API công khai - Có các mệnh đề
caseđể xử lý các bản ghi không hợp lệ của một loại cụ thể (ví dụ:'book'), cũng như một mệnh đề bắt tất cả
Bây giờ, hãy xem cách get_creators xử lý một số doctest cụ thể:
>>> b1 = dict(api=1, author='Douglas Hofstadter',
... type='book', title='Gödel, Escher, Bach')
>>> get_creators(b1)
['Douglas Hofstadter']
>>> from collections import OrderedDict
>>> b2 = OrderedDict(api=2, type='book',
... title='Python in a Nutshell',
... authors='Martelli Ravenscroft Holden'.split())
>>> get_creators(b2)
['Martelli', 'Ravenscroft', 'Holden']
>>> get_creators({'type': 'book', 'pages': 770})
Traceback (most recent call last):
...
ValueError: Invalid 'book' record: {'type': 'book', 'pages': 770}
>>> get_creators('Spam, spam, spam')
Traceback (most recent call last):
...
ValueError: Invalid record: 'Spam, spam, spam'
Lưu ý rằng thứ tự của các key trong các mẫu là không liên quan, ngay cả khi đối tượng là một OrderedDict như b2.
Trái ngược với các mẫu chuỗi, các mẫu mapping thành công trên các kết quả khớp một phần. Trong các doctest, các đối tượng b1 và b2 bao gồm key 'title' không xuất hiện trong bất kỳ mẫu 'book' nào, nhưng chúng vẫn khớp.
Không cần sử dụng **extra để khớp với các cặp key-value bổ sung, nhưng nếu bạn muốn nắm bắt chúng dưới dạng dict, bạn có thể thêm tiền tố ** vào một biến. Nó phải là biến cuối cùng trong mẫu và **_ bị cấm vì nó sẽ là dư thừa. Một ví dụ đơn giản:
>>> food = dict(category='ice cream', flavor='vanilla', cost=199)
>>> match food:
... case {'category': 'ice cream', **details}:
... print(f'Ice cream details: {details}')
...
Ice cream details: {'flavor': 'vanilla', 'cost': 199}
Trong phần “Xử lý tự động các key bị thiếu” trên trang 90, chúng ta sẽ nghiên cứu defaultdict và các mapping khác trong đó tra cứu key thông qua __getitem__ (tức là d[key]) thành công vì các mục bị thiếu được tạo ra một cách nhanh chóng. Trong ngữ cảnh so khớp mẫu, một kết quả khớp chỉ thành công nếu đối tượng đã có các key bắt buộc ở đầu câu lệnh match.
3. Standard API of Mapping Types
4. API chuẩn của các kiểu ánh xạ (Mapping Types)
Module collections.abc cung cấp các lớp trừu tượng (ABCs) Mapping và MutableMapping mô tả các giao diện của dict và các kiểu tương tự. Xem Hình 3-1.
Giá trị chính của các ABC này là ghi lại và chính thức hóa các giao diện chuẩn cho các ánh xạ, đồng thời đóng vai trò làm tiêu chí cho các kiểm tra isinstance trong code cần hỗ trợ ánh xạ theo nghĩa rộng:
>>> my_dict = {}
>>> isinstance(my_dict, abc.Mapping)
True
>>> isinstance(my_dict, abc.MutableMapping)
True
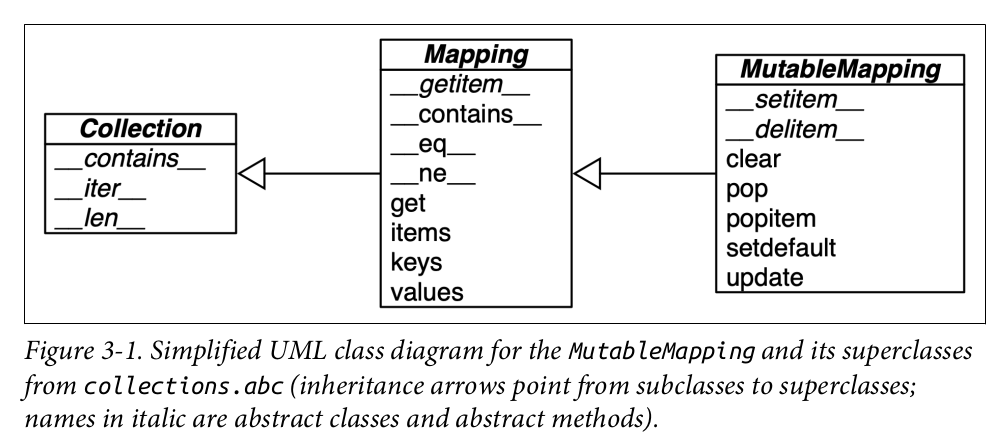
Để triển khai một ánh xạ tùy chỉnh, dễ dàng hơn nên mở rộng collections.UserDict, hoặc bao bọc một dict bằng cách ghép (composition), thay vì tạo lớp con từ các ABC này. Lớp collections.UserDict và tất cả các lớp ánh xạ cụ thể trong thư viện chuẩn đều đóng gói dict cơ bản trong triển khai của chúng, từ đó được xây dựng trên một bảng băm (hash table).
Do đó, tất cả chúng đều có chung hạn chế là các key phải là hashable (các value không cần phải hashable, chỉ các key). Nếu bạn cần ôn lại, phần tiếp theo sẽ giải thích.
4.1. What Is Hashable
- Hashable là gì?: Là các đối tượng có mã băm không đổi và có thể so sánh với nhau. Mã băm giống như “dấu vân tay” của đối tượng, dùng để tra cứu nhanh.
- Tại sao cần hashable?: Để làm khóa (key) trong
dict,setvì các kiểu dữ liệu này dùng mã băm để tổ chức và truy cập dữ liệu hiệu quả. - Kiểu dữ liệu nào là hashable?:
- Kiểu số (int, float…)
- Chuỗi (
str) - Tuple (nếu tất cả phần tử trong tuple đều là hashable)
frozenset
- Kiểu dữ liệu nào không hashable?:
- List (
list) - Set (
set) - Dictionary (
dict) - Các kiểu dữ liệu có thể thay đổi nội dung sau khi tạo.
- List (
Ví dụ:
Bạn có thể dùng số, chuỗi, tuple làm khóa trong từ điển, nhưng không thể dùng list.
# Hợp lệ
my_dict = {1: "một", "hai": 2, (1, 2): "cặp"}
# Không hợp lệ - TypeError: unhashable type: 'list'
my_dict = {[1, 2]: "danh sách"}
4.2. Overview of Common Mapping Methods
API cơ bản cho các kiểu ánh xạ (mapping) khá phong phú. Bảng 3-1 hiển thị các phương thức được triển khai bởi dict và hai biến thể phổ biến: defaultdict và OrderedDict, cả hai đều được định nghĩa trong module collections.
Cách d.update(m) xử lý đối số đầu tiên m là một ví dụ điển hình của duck typing: nó đầu tiên kiểm tra xem m có phương thức keys hay không, và nếu có, nó giả định rằng m là một kiểu ánh xạ. Nếu không, update() sẽ lặp qua m, giả định các mục của nó là các cặp (key, value). Hàm tạo cho hầu hết các kiểu ánh xạ Python sử dụng logic của update() trong nội bộ, có nghĩa là chúng có thể được khởi tạo từ các kiểu ánh xạ khác hoặc từ bất kỳ đối tượng iterable nào tạo ra các cặp (key, value).
Một phương thức ánh xạ tinh tế là setdefault(). Nó tránh việc tra cứu key dư thừa khi chúng ta cần cập nhật giá trị của một mục tại chỗ. Phần tiếp theo sẽ chỉ ra cách sử dụng nó.


4.3. Inserting or Updating Mutable Values
Phù hợp với triết lý “fail-fast” của Python, truy cập dict với d[k] sẽ tạo ra lỗi khi k không phải là key hiện có. Các Pythonista đều biết rằng d.get(k, default) là một lựa chọn thay thế cho d[k] bất cứ khi nào giá trị mặc định thuận tiện hơn việc xử lý KeyError. Tuy nhiên, khi bạn lấy một giá trị mutable và muốn cập nhật nó, có một cách tốt hơn.
Hãy xem xét một script để lập chỉ mục văn bản, tạo ra một ánh xạ trong đó mỗi key là một từ và value là một danh sách các vị trí xuất hiện của từ đó, như trong Ví dụ 3-3.
Ví dụ 3-3. Đầu ra một phần từ Ví dụ 3-4 xử lý “Zen of Python”; mỗi dòng hiển thị một từ và danh sách các lần xuất hiện được mã hóa dưới dạng cặp: (line_number, column_number)
$ python3 index0.py zen.txt
a [(19, 48), (20, 53)]
Although [(11, 1), (16, 1), (18, 1)]
ambiguity [(14, 16)]
and [(15, 23)]
are [(21, 12)]
aren [(10, 15)]
at [(16, 38)]
bad [(19, 50)]
be [(15, 14), (16, 27), (20, 50)]
beats [(11, 23)]
Beautiful [(3, 1)]
better [(3, 14), (4, 13), (5, 11), (6, 12), (7, 9), (8, 11), (17, 8), (18, 25)]
...
Ví dụ 3-4 là một script không tối ưu được viết để hiển thị một trường hợp mà dict.get không phải là cách tốt nhất để xử lý key bị thiếu. Tôi đã điều chỉnh nó từ một ví dụ của Alex Martelli.4
Ví dụ 3-4. index0.py sử dụng dict.get để lấy và cập nhật danh sách các lần xuất hiện của từ từ index (một giải pháp tốt hơn có trong Ví dụ 3-5)
"""Build an index mapping word -> list of occurrences"""
import re
import sys
WORD_RE = re.compile(r'\w+')
index = {}
with open(sys.argv[1], encoding='utf-8') as fp:
for line_no, line in enumerate(fp, 1):
for match in WORD_RE.finditer(line):
word = match.group()
column_no = match.start() + 1
location = (line_no, column_no)
# this is ugly; coded like this to make a point
occurrences = index.get(word, []) # Lấy danh sách occurrences cho từ, hoặc [] nếu không tìm thấy.
occurrences.append(location) # Thêm vị trí mới vào occurrences.
index[word] = occurrences # Đặt occurrences đã thay đổi vào dict index; điều này dẫn đến việc tìm kiếm lần thứ hai thông qua index.
# display in alphabetical order
for word in sorted(index, key=str.upper):
print(word, index[word])
Trong đối số key= của sorted, tôi không gọi str.upper, chỉ truyền một tham chiếu đến phương thức đó để hàm sorted có thể sử dụng nó để chuẩn hóa các từ để sắp xếp.5
Ba dòng xử lý occurrences trong Ví dụ 3-4 có thể được thay thế bằng một dòng duy nhất bằng cách sử dụng dict.setdefault. Ví dụ 3-5 gần với mã của Alex Martelli hơn.
Ví dụ 3-5. index.py sử dụng dict.setdefault để lấy và cập nhật danh sách các lần xuất hiện của từ từ index trong một dòng duy nhất; so sánh với Ví dụ 3-4
"""Build an index mapping word -> list of occurrences"""
import re
import sys
WORD_RE = re.compile(r'\w+')
index = {}
with open(sys.argv[1], encoding='utf-8') as fp:
for line_no, line in enumerate(fp, 1):
for match in WORD_RE.finditer(line):
word = match.group()
column_no = match.start() + 1
location = (line_no, column_no)
index.setdefault(word, []).append(location) # Lấy danh sách occurrences cho từ, hoặc đặt nó thành [] nếu không tìm thấy; setdefault trả về giá trị, vì vậy nó có thể được cập nhật mà không cần tìm kiếm lần thứ hai.
# display in alphabetical order
for word in sorted(index, key=str.upper):
print(word, index[word])
Nói cách khác, kết quả cuối cùng của dòng này…
my_dict.setdefault(key, []).append(new_value)
…giống như chạy…
if key not in my_dict:
my_dict[key] = []
my_dict[key].append(new_value)
…ngoại trừ việc đoạn mã sau thực hiện ít nhất hai lần tìm kiếm cho key — ba lần nếu không tìm thấy — trong khi setdefault thực hiện tất cả chỉ với một lần tra cứu.
Một vấn đề liên quan, xử lý các key bị thiếu trên bất kỳ tra cứu nào (và không chỉ khi chèn), là chủ đề của phần tiếp theo.
Important note
setdefault(key, default) là một phương thức hữu ích trong Python dictionaries cho phép bạn lấy giá trị của một key nếu nó tồn tại, hoặc nếu không, chèn key đó với một giá trị mặc định và trả về giá trị đó.
Cách thức hoạt động:
- Kiểm tra key: Phương thức
setdefault()đầu tiên kiểm tra xemkeyđã tồn tại trong dictionary hay chưa. - Trả về giá trị: Nếu
keyđã tồn tại, phương thức sẽ trả về giá trị tương ứng vớikeyđó. - Chèn và trả về giá trị mặc định: Nếu
keykhông tồn tại, phương thức sẽ chènkeyvào dictionary vớidefaultlà giá trị tương ứng, và sau đó trả vềdefault.
Lợi ích:
- Ngắn gọn:
setdefault()cho phép bạn kết hợp việc kiểm tra key, gán giá trị mặc định và lấy giá trị trong một thao tác duy nhất, giúp code gọn gàng hơn. - Hiệu quả: Thay vì phải thực hiện nhiều lần tra cứu để kiểm tra key và gán giá trị,
setdefault()chỉ cần một lần tra cứu duy nhất. - Tránh lỗi:
setdefault()giúp bạn tránh gặp phải lỗiKeyErrorkhi cố gắng truy cập một key không tồn tại trong dictionary.
Ví dụ:
data = {'a': 1, 'b': 2}
# Key 'a' tồn tại, trả về giá trị 1
value = data.setdefault('a', 5)
print(value) # Output: 1
print(data) # Output: {'a': 1, 'b': 2}
# Key 'c' không tồn tại, chèn key 'c' với giá trị 3 và trả về 3
value = data.setdefault('c', 3)
print(value) # Output: 3
print(data) # Output: {'a': 1, 'b': 2, 'c': 3}
Ứng dụng:
setdefault() thường được sử dụng trong các trường hợp sau:
- Đếm số lần xuất hiện: Bạn có thể sử dụng
setdefault()để đếm số lần xuất hiện của các phần tử trong một list hoặc string,
def count_characters(text):
"""
Hàm này đếm số lần xuất hiện của mỗi ký tự trong một chuỗi.
"""
counts = {}
for char in text:
counts.setdefault(char, 0)
counts[char] += 1
return counts
text = "hello world"
char_counts = count_characters(text)
print(char_counts) # Output: {'h': 1, 'e': 1, 'l': 3, 'o': 2, ' ': 1, 'w': 1, 'r': 1, 'd': 1}
- Tạo dictionary lồng nhau:
setdefault()giúp bạn dễ dàng tạo các dictionary lồng nhau mà không cần phải kiểm tra sự tồn tại của các key ở mỗi cấp độ.
def create_student_data(students):
"""
Hàm này tạo một dictionary lồng nhau để lưu trữ thông tin sinh viên.
"""
data = {}
for student in students:
name, age, grade = student
data.setdefault(name, {}).setdefault('age', age)
data[name]['grade'] = grade
return data
students = [
("Alice", 20, "A"),
("Bob", 22, "B"),
("Alice", 20, "B"), # Alice có thêm một môn học
]
student_data = create_student_data(students)
print(student_data)
# Output: {'Alice': {'age': 20, 'grade': 'B'}, 'Bob': {'age': 22, 'grade': 'B'}}
- Xây dựng cấu trúc dữ liệu phức tạp:
setdefault()có thể được sử dụng để xây dựng các cấu trúc dữ liệu phức tạp, chẳng hạn như cây hoặc đồ thị.
def build_graph(edges):
"""
Hàm này xây dựng một đồ thị từ danh sách cạnh.
"""
graph = {}
for u, v in edges:
graph.setdefault(u, []).append(v)
graph.setdefault(v, []).append(u) # Đồ thị vô hướng
return graph
edges = [
(0, 1), (0, 2), (1, 2), (2, 0), (2, 3), (3, 3)
]
graph = build_graph(edges)
print(graph) # Output: {0: [1, 2, 2], 1: [0, 2], 2: [0, 1, 0, 3], 3: [2, 3]}
Tóm lại, setdefault() là một công cụ mạnh mẽ trong Python dictionaries giúp bạn viết code hiệu quả và dễ đọc hơn.
5. Automatic Handling of Missing Keys
Đôi khi, sẽ rất tiện lợi khi có các mappings trả về một giá trị “bịa ra” khi tìm kiếm một key bị thiếu (missing key). Có hai cách tiếp cận chính cho việc này: một là sử dụng defaultdict thay vì dict thông thường. Cách còn lại là tạo subclass của dict hoặc bất kỳ mapping type nào khác và thêm phương thức __missing__.
5.1. defaultdict: Another Take on Missing Keys
Một instance collections.defaultdict tạo ra các item với một giá trị mặc định theo yêu cầu bất cứ khi nào một missing key được tìm kiếm bằng cú pháp d[k]. Ví dụ 3-6 sử dụng defaultdict để cung cấp một giải pháp gọn gàng khác cho bài toán lập chỉ mục từ trong Ví dụ 3-5.
Cách hoạt động như sau: khi khởi tạo một defaultdict, bạn cung cấp một callable để tạo ra một giá trị mặc định bất cứ khi nào __getitem__ được truyền một đối số key không tồn tại. Ví dụ, với một defaultdict được tạo như dd = defaultdict(list), nếu 'new-key' không có trong dd, biểu thức dd['new-key'] sẽ thực hiện các bước sau:
- Gọi
list()để tạo mộtlistmới. - Chèn
listvàoddsử dụng'new-key'làmkey. - Trả về một tham chiếu đến
listđó.
Callable tạo ra các giá trị mặc định được lưu giữ trong một thuộc tính instance có tên default_factory.
Ví dụ 3-6. index_default.py: sử dụng defaultdict thay vì phương thức setdefault
"""Build an index mapping word -> list of occurrences"""
import collections
import re
import sys
WORD_RE = re.compile(r'\w+')
index = collections.defaultdict(list) # Tạo một defaultdict với list constructor làm default_factory.
with open(sys.argv[1], encoding='utf-8') as fp:
for line_no, line in enumerate(fp, 1):
for match in WORD_RE.finditer(line):
word = match.group()
column_no = match.start() + 1
location = (line_no, column_no)
index[word].append(location) # Nếu word không có trong index, default_factory được gọi để tạo ra giá trị bị thiếu, trong trường hợp này là một list rỗng sau đó được gán cho index[word] và trả về, do đó thao tác .append(location) luôn thành công.
# display in alphabetical order
for word in sorted(index, key=str.upper):
print(word, index[word])
Nếu không cung cấp default_factory, KeyError thông thường sẽ được raise cho các missing keys.
5.2. The missing Method
Nằm bên dưới cách các mappings xử lý missing keys là phương thức được đặt tên rất phù hợp __missing__. Phương thức này không được định nghĩa trong base class dict, nhưng dict nhận biết nó: nếu bạn tạo subclass của dict và cung cấp phương thức __missing__, dict.__getitem__ tiêu chuẩn sẽ gọi nó bất cứ khi nào không tìm thấy key, thay vì raise KeyError.
Giả sử bạn muốn một mapping trong đó key được chuyển đổi thành str khi tra cứu. Một trường hợp sử dụng cụ thể là thư viện thiết bị cho IoT,6 trong đó một board lập trình với các chân I/O đa năng (ví dụ: Raspberry Pi hoặc Arduino) được biểu diễn bằng class Board với thuộc tính my_board.pins, là một mapping của các pin identifier vật lý tới các pin object phần mềm. Pin identifier vật lý có thể chỉ là một số hoặc một chuỗi như “A0” hoặc “P9_12”. Để đảm bảo tính nhất quán, mong muốn rằng tất cả các key trong board.pins là chuỗi, nhưng cũng thuận tiện khi tra cứu một pin theo số, như trong my_arduino.pin[13], để những người mới bắt đầu không bị vấp ngã khi họ muốn nhấp nháy đèn LED trên pin 13 của Arduino. Ví dụ 3-7 cho thấy cách thức hoạt động của mapping như vậy.
Ví dụ 3-7. Khi tìm kiếm một key không phải chuỗi, StrKeyDict0 chuyển đổi nó thành str khi không tìm thấy
# Kiểm tra lấy item sử dụng `d[key]` notation::
>>> d = StrKeyDict0([('2', 'two'), ('4', 'four')])
>>> d['2']
'two'
>>> d[4]
'four'
>>> d[1]
Traceback (most recent call last):
...
KeyError: '1'
# Kiểm tra lấy item sử dụng `d.get(key)` notation::
>>> d.get('2')
'two'
>>> d.get(4)
'four'
>>> d.get(1, 'N/A')
'N/A'
# Kiểm tra toán tử `in`::
>>> 2 in d
True
>>> 1 in d
False
Ví dụ 3-8. StrKeyDict0 chuyển đổi các key không phải chuỗi thành str khi tra cứu (xem các bài kiểm tra trong Ví dụ 3-7)
class StrKeyDict0(dict): # StrKeyDict0 kế thừa từ dict.
def __missing__(self, key):
if isinstance(key, str): # Kiểm tra xem key đã là str chưa. Nếu đúng, và nó bị thiếu, raise KeyError.
raise KeyError(key)
return self[str(key)] # Xây dựng str từ key và tra cứu nó.
def get(self, key, default=None):
try:
return self[key] # Phương thức get ủy quyền cho __getitem__ bằng cách sử dụng self[key] notation; điều đó cho phép __missing__ của chúng ta hoạt động.
except KeyError:
return default # Nếu KeyError được raise, __missing__ đã thất bại, vì vậy chúng ta trả về default.
def __contains__(self, key):
return key in self.keys() or str(key) in self.keys() # Tìm kiếm key chưa sửa đổi (instance có thể chứa các key không phải str), sau đó tìm kiếm str được xây dựng từ key.
Hãy dành chút thời gian để xem xét lý do tại sao cần kiểm tra isinstance(key, str) trong triển khai __missing__.
Nếu không có kiểm tra đó, phương thức __missing__ của chúng ta sẽ hoạt động tốt cho bất kỳ key k nào — str hoặc không phải str — bất cứ khi nào str(k) tạo ra một key hiện có. Nhưng nếu str(k) không phải là key hiện có, chúng ta sẽ gặp phải đệ quy vô hạn. Trong dòng cuối cùng của __missing__, self[str(key)] sẽ gọi __getitem__, truyền key str đó, đến lượt nó sẽ gọi lại __missing__.
Phương thức __contains__ cũng cần thiết để đảm bảo tính nhất quán trong ví dụ này, bởi vì thao tác k in d gọi nó, nhưng phương thức được kế thừa từ dict không chuyển sang gọi __missing__. Có một chi tiết tinh tế trong triển khai __contains__ của chúng ta: chúng ta không kiểm tra key theo cách Pythonic thông thường — k in my_dict — bởi vì str(key) in self sẽ gọi đệ quy __contains__. Chúng ta tránh điều này bằng cách tra cứu rõ ràng key trong self.keys().
Tra cứu như k in my_dict.keys() hiệu quả trong Python 3 ngay cả đối với các mappings rất lớn vì dict.keys() trả về một view, tương tự như một set, như chúng ta sẽ thấy trong “Set Operations on dict Views” trên trang 110. Tuy nhiên, hãy nhớ rằng k in my_dict cũng thực hiện công việc tương tự và nhanh hơn vì nó tránh tra cứu thuộc tính để tìm phương thức .keys.
Tôi có một lý do cụ thể để sử dụng self.keys() trong phương thức __contains__ trong Ví dụ 3-8. Việc kiểm tra key chưa sửa đổi — key in self.keys() — là cần thiết để đảm bảo tính chính xác vì StrKeyDict0 không bắt buộc tất cả các key trong dictionary phải thuộc kiểu str. Mục tiêu duy nhất của chúng ta với ví dụ đơn giản này là làm cho việc tìm kiếm “thân thiện” hơn và không ép buộc kiểu.
5.3. Sử dụng không nhất quán __missing__ trong Standard Library
Hãy xem xét các trường hợp sau và cách các tra cứu missing key bị ảnh hưởng:
- Subclass của
dict- Một subclass của
dictchỉ implement__missing__và không có phương thức nào khác. Trong trường hợp này,__missing__chỉ có thể được gọi trênd[k], sẽ sử dụng__getitem__được kế thừa từdict.
- Một subclass của
- Subclass của
collections.UserDict- Tương tự, một subclass của
UserDictchỉ implement__missing__và không có phương thức nào khác. Phương thứcgetđược kế thừa từUserDictgọi__getitem__. Điều này có nghĩa là__missing__có thể được gọi để xử lý tra cứu vớid[k]vàd.get(k).
- Tương tự, một subclass của
- Subclass của
abc.Mappingvới__getitem__đơn giản nhất có thể- Một subclass tối thiểu của
abc.Mappingimplement__missing__và các phương thức abstract bắt buộc, bao gồm một triển khai của__getitem__không gọi__missing__. Phương thức__missing__không bao giờ được kích hoạt trong class này.
- Một subclass tối thiểu của
- Subclass của
abc.Mappingvới__getitem__gọi__missing__- Một subclass tối thiểu của
abc.Mappingimplement__missing__và các phương thức abstract bắt buộc, bao gồm một triển khai của__getitem__gọi__missing__. Phương thức__missing__được kích hoạt trong class này cho các tra cứumissing keyđược thực hiện vớid[k],d.get(k)vàk in d.
- Một subclass tối thiểu của
Xem missing.py trong kho lưu trữ mã ví dụ để biết các minh họa về các trường hợp được mô tả ở đây.
Bốn trường hợp vừa mô tả giả định các triển khai tối thiểu. Nếu subclass của bạn implement __getitem__, get và __contains__, thì bạn có thể làm cho các phương thức đó sử dụng __missing__ hoặc không, tùy thuộc vào nhu cầu của bạn. Mục đích của phần này là chỉ ra rằng bạn phải cẩn thận khi tạo subclass của các mappings trong standard library để sử dụng __missing__, bởi vì các base class hỗ trợ các hành vi khác nhau theo mặc định.
Đừng quên rằng hành vi của setdefault và update cũng bị ảnh hưởng bởi tra cứu key. Và cuối cùng, tùy thuộc vào logic của __missing__ của bạn, bạn có thể cần implement logic đặc biệt trong __setitem__, để tránh hành vi không nhất quán hoặc gây ngạc nhiên. Chúng ta sẽ thấy một ví dụ về điều này trong “Subclassing UserDict Instead of dict” trên trang 97.
Cho đến nay, chúng ta đã đề cập đến các mapping type dict và defaultdict, nhưng standard library đi kèm với các triển khai mapping khác, mà chúng ta sẽ thảo luận tiếp theo.
6. Các biến thể của dict
Phần này tổng quan về các kiểu ánh xạ (mapping types) có trong thư viện chuẩn, ngoài defaultdict, đã được đề cập trong “defaultdict: Another Take on Missing Keys” ở trang 90.
6.1. collections.OrderedDict
Vì dict tích hợp sẵn cũng đã giữ thứ tự các key kể từ Python 3.6, lý do phổ biến nhất để sử dụng OrderedDict là viết code tương thích ngược với các phiên bản Python cũ hơn. Tài liệu của Python liệt kê một số điểm khác biệt còn lại giữa dict và OrderedDict, tôi xin trích dẫn ở đây—chỉ sắp xếp lại thứ tự các mục cho phù hợp với việc sử dụng hàng ngày:
- Toán tử bằng (
equality operation) choOrderedDictkiểm tra cả thứ tự khớp. - Phương thức
popitem()củaOrderedDictcó signature khác. Nó chấp nhận một tham số tùy chọn để chỉ định item nào được lấy ra. OrderedDictcó phương thứcmove_to_end()để di chuyển một phần tử đến đầu hoặc cuối một cách hiệu quả.dictthông thường được thiết kế để thực hiện rất tốt các thao tác ánh xạ (mapping operations). Theo dõi thứ tự chèn là thứ yếu.OrderedDictđược thiết kế để thực hiện tốt các thao tác sắp xếp lại (reordering operations). Hiệu quả không gian, tốc độ lặp và hiệu suất của các thao tác cập nhật là thứ yếu.- Về mặt thuật toán,
OrderedDictcó thể xử lý các thao tác sắp xếp lại thường xuyên tốt hơndict. Điều này làm cho nó phù hợp để theo dõi các truy cập gần đây (ví dụ: trong bộ nhớ cache LRU).
6.2. collections.ChainMap
ChainMap trong module collections của Python là một loại cấu trúc dữ liệu đặc biệt cho phép bạn kết hợp nhiều dictionary (hoặc các đối tượng mapping khác) thành một dictionary duy nhất. Điểm đặc biệt của ChainMap là nó không tạo ra một bản sao mới của các dictionary, mà chỉ đơn giản là liên kết chúng lại với nhau. Điều này có nghĩa là bất kỳ thay đổi nào bạn thực hiện trên ChainMap sẽ ảnh hưởng đến dictionary gốc tương ứng.
Cách thức hoạt động:
Khi bạn tra cứu một key trong ChainMap, nó sẽ lần lượt tìm kiếm trong từng dictionary mà bạn đã cung cấp, theo thứ tự mà bạn đã chỉ định. Khi tìm thấy key trong một dictionary, nó sẽ trả về giá trị tương ứng và dừng việc tìm kiếm.
Ví dụ cơ bản:
from collections import ChainMap
dict1 = {'a': 1, 'b': 2}
dict2 = {'c': 3, 'd': 4}
chain = ChainMap(dict1, dict2)
print(chain['a']) # Output: 1 (tìm thấy trong dict1)
print(chain['c']) # Output: 3 (tìm thấy trong dict2)
Ứng dụng:
-
Mô phỏng phạm vi biến (scope): Trong lập trình, phạm vi biến xác định vùng mà một biến có thể được truy cập.
ChainMapcó thể được sử dụng để mô phỏng phạm vi biến lồng nhau, ví dụ như trong các ngôn ngữ lập trình có khái niệm “biến cục bộ” và “biến toàn cục”.from collections import ChainMap globals = {'x': 10} locals = {'x': 5, 'y': 2} scope = ChainMap(locals, globals) print(scope['x']) # Output: 5 (ưu tiên biến cục bộ) print(scope['y']) # Output: 2 (chỉ có trong biến cục bộ) -
Cập nhật cấu hình:
ChainMapcó thể được sử dụng để kết hợp các file cấu hình hoặc các nguồn cấu hình khác nhau, cho phép bạn ghi đè các giá trị mặc định bằng các giá trị cụ thể hơn. -
Truy cập dữ liệu từ nhiều nguồn: Nếu bạn có dữ liệu được lưu trữ trong nhiều dictionary khác nhau,
ChainMapcho phép bạn truy cập tất cả dữ liệu đó một cách dễ dàng mà không cần phải hợp nhất chúng thành một dictionary duy nhất.
Lưu ý:
- Khi bạn cập nhật hoặc thêm một key-value pair vào
ChainMap, thay đổi này sẽ chỉ ảnh hưởng đến dictionary đầu tiên trong chuỗi. ChainMapcung cấp các phương thức hữu ích khác nhưnew_child(),parentsvàmapsđể quản lý chuỗi các dictionary.
Tóm lại, ChainMap là một công cụ mạnh mẽ trong Python cho phép bạn làm việc với nhiều dictionary một cách linh hoạt và hiệu quả. Hy vọng những giải thích và ví dụ trên đã giúp bạn hiểu rõ hơn về cách sử dụng ChainMap.
6.3. collections.Counter
Một ánh xạ (mapping) lưu giữ số lượng (count) dưới dạng số nguyên cho mỗi key. Cập nhật một key hiện có sẽ cộng vào số lượng của nó. Điều này có thể được sử dụng để đếm các instance của các đối tượng hashable hoặc như một multiset (được thảo luận sau trong phần này). Counter triển khai các toán tử + và - để kết hợp các số lượng, và các phương thức hữu ích khác như most_common([n]), trả về một danh sách các tuple được sắp xếp với n mục phổ biến nhất và số lượng của chúng; xem tài liệu. Dưới đây là Counter được sử dụng để đếm các chữ cái trong từ:
>>> ct = collections.Counter('abracadabra')
>>> ct
Counter({'a': 5, 'b': 2, 'r': 2, 'c': 1, 'd': 1})
>>> ct.update('aaaaazzz')
>>> ct
Counter({'a': 10, 'z': 3, 'b': 2, 'r': 2, 'c': 1, 'd': 1})
>>> ct.most_common(3)
[('a', 10), ('z', 3), ('b', 2)]
Lưu ý rằng các key ‘b’ và ‘r’ được gắn ở vị trí thứ ba, nhưng ct.most_common(3) chỉ hiển thị ba số lượng.
Ví dụ thực tế về việc sử dụng collections.Counter
collections.Counter là một công cụ mạnh mẽ để đếm các phần tử trong một tập hợp. Dưới đây là một số ví dụ thực tế về cách sử dụng Counter trong Python:
1. Phân tích văn bản:
- Đếm tần suất từ:
from collections import Counter
text = "Đây là một ví dụ về việc sử dụng Counter để đếm tần suất từ trong một đoạn văn bản."
words = text.lower().split()
word_counts = Counter(words)
print(word_counts)
# Output: Counter({'trong': 1, 'để': 1, 'một': 2, 'ví': 1, 'dụ': 1, 'về': 1, 'việc': 1, 'sử': 1, 'dụng': 1, 'counter': 1, 'đếm': 1, 'tần': 1, 'suất': 1, 'từ': 1, 'đoạn': 1, 'văn': 1, 'bản': 1, 'là': 1, 'đây': 1})
print(word_counts.most_common(3))
# Output: [('một', 2), ('trong', 1), ('để', 1)]
- Tìm kiếm n-gram phổ biến:
from collections import Counter
def find_ngrams(text, n):
"""Tìm kiếm n-gram trong một đoạn văn bản."""
words = text.lower().split()
ngrams = [tuple(words[i:i+n]) for i in range(len(words)-n+1)]
return Counter(ngrams)
text = "Đây là một ví dụ về việc sử dụng Counter để đếm tần suất từ trong một đoạn văn bản."
ngrams = find_ngrams(text, 2)
print(ngrams.most_common(3))
# Output: [(('một', 'đoạn'), 1), (('đoạn', 'văn'), 1), (('văn', 'bản'), 1)]
2. Xử lý dữ liệu:
- Đếm số lần xuất hiện của các giá trị trong một list:
from collections import Counter
data = [1, 2, 2, 3, 3, 3, 4, 4, 4, 4]
counts = Counter(data)
print(counts)
# Output: Counter({4: 4, 3: 3, 2: 2, 1: 1})
- Tìm các phần tử trùng lặp:
from collections import Counter
data = [1, 2, 2, 3, 3, 3, 4, 4, 4, 4]
counts = Counter(data)
duplicates = [item for item, count in counts.items() if count > 1]
print(duplicates)
# Output: [2, 3, 4]
3. Ứng dụng khác:
- Phân tích log: Đếm số lần xuất hiện của các sự kiện trong log file.
- Xử lý dữ liệu mạng: Phân tích lưu lượng truy cập mạng, đếm số lượng request từ các IP khác nhau.
- Sinh học: Đếm tần suất xuất hiện của các nucleotide trong chuỗi DNA.
Như bạn thấy, collections.Counter là một công cụ linh hoạt và hữu ích trong nhiều tình huống. Với khả năng đếm và phân tích tần suất xuất hiện của các phần tử, Counter giúp bạn đơn giản hóa code và xử lý dữ liệu hiệu quả hơn.
6.4. shelve.Shelf
shelve.Shelf là một module trong Python cho phép bạn lưu trữ dữ liệu dưới dạng key-value, giống như dictionary, nhưng dữ liệu được lưu trữ bền vững trên ổ đĩa. Nói cách khác, shelve.Shelf cung cấp một cách đơn giản để lưu trữ các đối tượng Python vào file và truy xuất chúng sau này.
Cách thức hoạt động:
shelve.Shelfsử dụng moduledbmđể tạo ra một cơ sở dữ liệu key-value đơn giản.- Key phải là chuỗi, còn value có thể là bất kỳ đối tượng Python nào mà module
picklecó thể serialize (tuần tự hóa). - Khi bạn lưu trữ dữ liệu vào
shelve.Shelf, nó sẽ tự động serialize đối tượng và lưu vào file. - Khi bạn truy xuất dữ liệu, nó sẽ deserialize đối tượng từ file và trả về cho bạn.
Ví dụ cơ bản:
import shelve
# Tạo một shelf mới hoặc mở một shelf hiện có
with shelve.open('mydata') as d:
d['name'] = 'John Doe'
d['age'] = 30
d['occupation'] = 'Software Engineer'
# Mở shelf và đọc dữ liệu
with shelve.open('mydata') as d:
print(d['name']) # Output: John Doe
print(d['age']) # Output: 30
Ví dụ thực tế:
-
Lưu trữ cấu hình ứng dụng: Thay vì lưu trữ cấu hình trong file text hoặc JSON, bạn có thể sử dụng
shelve.Shelfđể lưu trữ các đối tượng cấu hình phức tạp hơn. -
Cache dữ liệu:
shelve.Shelfcó thể được sử dụng để cache dữ liệu từ web hoặc các nguồn khác, giúp tăng tốc độ truy cập dữ liệu. -
Lưu trữ dữ liệu người dùng: Trong các ứng dụng nhỏ, bạn có thể sử dụng
shelve.Shelfđể lưu trữ thông tin người dùng như tên, tuổi, địa chỉ, … -
Lưu trữ trạng thái trò chơi: Trong các trò chơi đơn giản, bạn có thể sử dụng
shelve.Shelfđể lưu trữ trạng thái trò chơi, cho phép người chơi tiếp tục trò chơi từ lần chơi trước.
Ưu điểm của shelve.Shelf:
- Đơn giản: Dễ sử dụng, cú pháp giống như dictionary.
- Bền vững: Dữ liệu được lưu trữ trên ổ đĩa, không bị mất khi chương trình kết thúc.
- Linh hoạt: Có thể lưu trữ nhiều loại đối tượng Python khác nhau.
Nhược điểm:
- Hiệu năng: Có thể chậm hơn so với các cơ sở dữ liệu khác, đặc biệt là khi xử lý dữ liệu lớn.
- Chỉ hỗ trợ key là chuỗi: Không thể sử dụng các kiểu dữ liệu khác làm key.
- Phụ thuộc vào pickle: Có thể gặp vấn đề bảo mật nếu dữ liệu được pickle từ các nguồn không tin cậy.
Tóm lại, shelve.Shelf là một lựa chọn đơn giản và hiệu quả cho việc lưu trữ dữ liệu bền vững trong Python khi bạn không cần đến các tính năng phức tạp của cơ sở dữ liệu chuyên dụng.
6.5. Subclassing UserDict Instead of dict
Trong Python, UserDict là một lớp trong module collections cung cấp một giao diện giống như dictionary. Tuy nhiên, thay vì trực tiếp kế thừa từ dict, bạn nên subclass UserDict. Dưới đây là một số lý do:
1. Dễ dàng tùy chỉnh:
UserDictđược thiết kế để dễ dàng tùy chỉnh hành vi của dictionary. Bạn có thể ghi đè các phương thức hiện có (như__setitem__,__getitem__,__delitem__) để thay đổi cách thức hoạt động của dictionary.- Ví dụ, bạn có thể tạo một dictionary tự động chuyển đổi tất cả các key thành chữ thường:
from collections import UserDict
class MyDict(UserDict):
def __setitem__(self, key, value):
key = key.lower()
super().__setitem__(key, value)
my_dict = MyDict()
my_dict["APPLE"] = 1
print(my_dict) # Output: {'apple': 1}
2. Tránh các vấn đề về kế thừa trực tiếp:
- Kế thừa trực tiếp từ
dictcó thể dẫn đến các vấn đề tiềm ẩn do cáchdictđược triển khai trong CPython. Một số phương thức củadictkhông được thiết kế để được ghi đè, và việc làm như vậy có thể dẫn đến hành vi không mong muốn. UserDictcung cấp một lớp bọc an toàn hơn chodict, giúp tránh các vấn đề này.
3. Tính linh hoạt:
UserDictcho phép bạn dễ dàng thêm các thuộc tính và phương thức mới vào dictionary của mình. Điều này giúp bạn tạo ra các cấu trúc dữ liệu chuyên biệt đáp ứng nhu cầu cụ thể của ứng dụng.
4. Khả năng tương thích:
UserDicttương thích với giao diện củadict, nghĩa là bạn có thể sử dụng nó trong bất kỳ mã nào mong đợi một đối tượngdict.
Tóm lại, subclassing UserDict thay vì dict mang lại nhiều lợi ích về tính dễ sử dụng, tùy chỉnh, an toàn và linh hoạt. Nó là một cách tiếp cận được khuyến nghị khi bạn cần tạo ra các dictionary với hành vi tùy chỉnh trong Python.
7. Immutable Mappings
Trong Python, hầu hết các kiểu ánh xạ (mapping types) như dict đều là mutable (khả biến), nghĩa là bạn có thể thay đổi nội dung của chúng sau khi tạo. Tuy nhiên, đôi khi bạn cần đảm bảo rằng một ánh xạ không bị thay đổi, ví dụ như khi làm việc với dữ liệu nhạy cảm hoặc khi cần đảm bảo tính nhất quán của dữ liệu. Đó là lúc immutable mappings (ánh xạ bất biến) trở nên hữu ích.
Cách tạo Immutable Mappings:
Python không cung cấp một kiểu dữ liệu immutable mapping riêng biệt. Tuy nhiên, bạn có thể sử dụng MappingProxyType từ module types để tạo ra một proxy chỉ đọc (read-only) cho một ánh xạ hiện có. Proxy này hoạt động như một “lớp vỏ bọc” cho ánh xạ gốc, cho phép bạn truy cập các phần tử nhưng không cho phép sửa đổi chúng.
Ví dụ:
from types import MappingProxyType
my_dict = {'a': 1, 'b': 2}
immutable_dict = MappingProxyType(my_dict)
print(immutable_dict['a']) # Output: 1 (truy cập bình thường)
try:
immutable_dict['a'] = 3 # Cố gắng thay đổi giá trị
except TypeError as e:
print(e) # Output: 'mappingproxy' object does not support item assignment
Đặc điểm của Immutable Mappings:
- Chỉ đọc: Bạn không thể thêm, xóa hoặc sửa đổi các phần tử trong
immutable mapping. - Động: Mọi thay đổi trên ánh xạ gốc sẽ được phản ánh trong
immutable mapping. - Hiệu quả:
MappingProxyTypekhông tạo ra một bản sao của ánh xạ gốc, nên rất hiệu quả về bộ nhớ.
Ứng dụng:
- Bảo vệ dữ liệu nhạy cảm: Ngăn chặn việc sửa đổi ngẫu nhiên hoặc trái phép dữ liệu quan trọng.
- Truyền dữ liệu an toàn: Đảm bảo rằng dữ liệu được truyền giữa các hàm hoặc module không bị thay đổi.
- Tạo API ổn định: Cung cấp cho người dùng một giao diện ổn định mà không lo lắng về việc họ sửa đổi dữ liệu nội bộ.
Ví dụ thực tế:
Giả sử bạn đang xây dựng một ứng dụng quản lý thiết bị. Bạn có một dictionary chứa thông tin về các cổng kết nối của thiết bị:
pins = {
'pin1': {'mode': 'input', 'value': 0},
'pin2': {'mode': 'output', 'value': 1},
}
Bạn muốn cho phép người dùng đọc thông tin về các cổng kết nối, nhưng không cho phép họ thay đổi cấu hình. Bạn có thể sử dụng MappingProxyType để tạo ra một immutable mapping cho pins:
from types import MappingProxyType
pins_proxy = MappingProxyType(pins)
# Người dùng có thể đọc thông tin
print(pins_proxy['pin1']) # Output: {'mode': 'input', 'value': 0}
# Nhưng không thể thay đổi
try:
pins_proxy['pin1']['mode'] = 'output'
except TypeError as e:
print(e) # Output: 'mappingproxy' object does not support item assignment
Như vậy, MappingProxyType giúp bạn tạo ra các immutable mappings để bảo vệ dữ liệu và đảm bảo tính nhất quán trong ứng dụng của mình.
8. Dictionary Views
Dictionary Views là một tính năng mạnh mẽ trong Python, cho phép bạn truy cập vào các keys, values, và items của một dictionary một cách hiệu quả mà không cần tạo ra bản sao của dữ liệu.
Cách tạo Dictionary Views:
Bạn có thể tạo dictionary views bằng cách sử dụng các phương thức sau của đối tượng dict:
.keys(): Trả về một view object chứa tất cả các keys trong dictionary..values(): Trả về một view object chứa tất cả các values trong dictionary..items(): Trả về một view object chứa tất cả các cặp key-value trong dictionary dưới dạng tuple.
Đặc điểm của Dictionary Views:
- Dynamic: Views được liên kết trực tiếp với dictionary gốc. Bất kỳ thay đổi nào trên dictionary gốc sẽ được phản ánh ngay lập tức trong view.
- Read-only: Bạn không thể sửa đổi nội dung của dictionary thông qua view.
- Memory-efficient: Views không tạo ra bản sao của dữ liệu, giúp tiết kiệm bộ nhớ.
- Iterable: Bạn có thể duyệt qua các phần tử trong view bằng vòng lặp
for.
Ví dụ:
my_dict = {'a': 1, 'b': 2, 'c': 3}
# Tạo dictionary views
keys_view = my_dict.keys()
values_view = my_dict.values()
items_view = my_dict.items()
# In ra các views
print(keys_view) # Output: dict_keys(['a', 'b', 'c'])
print(values_view) # Output: dict_values([1, 2, 3])
print(items_view) # Output: dict_items([('a', 1), ('b', 2), ('c', 3)])
# Duyệt qua view bằng vòng lặp for
for key in keys_view:
print(key)
# Kiểm tra sự thay đổi dynamic
my_dict['d'] = 4
print(keys_view) # Output: dict_keys(['a', 'b', 'c', 'd'])
Ứng dụng:
- Iteration: Duyệt qua các keys, values, hoặc items của dictionary một cách hiệu quả.
- Membership testing: Kiểm tra xem một key hoặc value có tồn tại trong dictionary hay không.
- Set operations: Thực hiện các phép toán tập hợp trên keys hoặc items của dictionary (sẽ được giải thích kỹ hơn ở phần sau).
Set Operations on dict Views:
dict_keys và dict_items hỗ trợ một số phương thức của set như union, intersection, difference, … Điều này cho phép bạn thực hiện các phép toán tập hợp trên keys hoặc items của dictionary một cách dễ dàng.
Ví dụ:
dict1 = {'a': 1, 'b': 2}
dict2 = {'b': 3, 'c': 4}
# Tìm các key chung
common_keys = dict1.keys() & dict2.keys()
print(common_keys) # Output: {'b'}
# Tìm tất cả các key
all_keys = dict1.keys() | dict2.keys()
print(all_keys) # Output: {'a', 'c', 'b'}
Kết luận:
Dictionary Views là một tính năng hữu ích trong Python, giúp bạn làm việc với dictionary hiệu quả hơn. Bằng cách hiểu rõ về đặc điểm và ứng dụng của Dictionary Views, bạn có thể viết code Python rõ ràng, ngắn gọn và tối ưu hơn.
9. Practical Consequences of How dict Works
Hiểu rõ cách thức hoạt động của dict trong Python giúp bạn viết code hiệu quả hơn và tránh được những lỗi tiềm ẩn. Dưới đây là giải thích chi tiết kèm ví dụ cho từng hệ quả thực tế:
1. Keys must be hashable objects:
- Giải thích:
dictsử dụng bảng băm (hash table) để lưu trữ dữ liệu. Bảng băm yêu cầu key phải là hashable, nghĩa là key phải có giá trị hash code không đổi trong suốt vòng đời của nó và có thể so sánh bằng nhau với các key khác. Các kiểu dữ liệu hashable trong Python bao gồm số, chuỗi, tuple (chỉ khi chứa các phần tử hashable). Các kiểu dữ liệu mutable như list và dict không phải là hashable. - Ví dụ:
# Key là chuỗi (hashable)
my_dict = {"apple": 1, "banana": 2}
# Key là list (không hashable) -> lỗi
my_dict = {["apple"]: 1} # TypeError: unhashable type: 'list'
2. Item access by key is very fast:
- Giải thích: Bảng băm cho phép truy cập phần tử bằng key với tốc độ rất nhanh, gần như không phụ thuộc vào số lượng phần tử trong
dict. Khi bạn truy cậpmy_dict[key], Python sẽ tính toán hash code củakey, sử dụng nó để tìm vị trí của phần tử trong bảng băm. - Ví dụ:
my_dict = {i: i*2 for i in range(1000000)} # 1 triệu phần tử
print(my_dict[999999]) # Truy cập gần như tức thì
3. Key ordering is preserved:
- Giải thích: Từ Python 3.7,
dictchính thức bảo toàn thứ tự chèn của key. Điều này có nghĩa là khi bạn duyệt quadict, các key sẽ xuất hiện theo thứ tự mà chúng được thêm vào. - Ví dụ:
my_dict = {'c': 3, 'a': 1, 'b': 2}
for key in my_dict:
print(key) # Output: c a b
4. Dicts have a significant memory overhead:
- Giải thích: Để đạt được tốc độ truy cập nhanh,
dictcần sử dụng nhiều bộ nhớ hơn so với các cấu trúc dữ liệu khác như list. Bảng băm cần không gian trống để tránh xung đột (collision) và duy trì hiệu quả. - Ví dụ: Một
dictvới 1 triệu phần tử sẽ chiếm dụng nhiều bộ nhớ hơn đáng kể so với một list với 1 triệu phần tử.
5. Avoid creating instance attributes outside of __init__:
- Giải thích: Python sử dụng
__dict__(mộtdict) để lưu trữ thuộc tính của đối tượng. Tạo thuộc tính instance bên ngoài__init__có thể làm giảm hiệu quả tối ưu hóa bộ nhớ của Python, đặc biệt là khi bạn có nhiều đối tượng cùng class. - Ví dụ:
class MyClass:
def __init__(self, a):
self.a = a
def add_attribute(self, b):
self.b = b # Tạo thuộc tính bên ngoài __init__
# Tạo nhiều đối tượng
objects = [MyClass(i) for i in range(1000000)]
# Thêm thuộc tính cho mỗi đối tượng
for obj in objects:
obj.add_attribute(1) # Có thể gây tốn kém bộ nhớ
Tóm lại:
Hiểu rõ những hệ quả thực tế này giúp bạn sử dụng dict hiệu quả hơn, viết code Python tối ưu hơn về tốc độ và bộ nhớ.
10. Set Theory
Set trong Python là một kiểu dữ liệu cho phép lưu trữ một tập hợp các phần tử duy nhất và không có thứ tự. Nó tương tự như khái niệm tập hợp trong toán học, và cung cấp nhiều phép toán hữu ích để làm việc với dữ liệu.
1. Tạo Set:
- Sử dụng dấu ngoặc nhọn
{}:
my_set = {1, 2, 3}
- Sử dụng constructor
set():
my_set = set([1, 2, 3, 3]) # Loại bỏ trùng lặp: {1, 2, 3}
2. Các phép toán trên Set:
Python cung cấp các toán tử và phương thức để thực hiện các phép toán tập hợp:
- Hợp (Union):
|hoặcunion()- Tạo một set mới chứa tất cả các phần tử từ cả hai set.
set1 = {1, 2, 3}
set2 = {3, 4, 5}
union_set = set1 | set2 # {1, 2, 3, 4, 5}
- Giao (Intersection):
&hoặcintersection()- Tạo một set mới chứa các phần tử chung của cả hai set.
set1 = {1, 2, 3}
set2 = {3, 4, 5}
intersection_set = set1 & set2 # {3}
- Hiệu (Difference):
-hoặcdifference()- Tạo một set mới chứa các phần tử thuộc set thứ nhất nhưng không thuộc set thứ hai.
set1 = {1, 2, 3}
set2 = {3, 4, 5}
difference_set = set1 - set2 # {1, 2}
- Hiệu đối xứng (Symmetric Difference):
^hoặcsymmetric_difference()- Tạo một set mới chứa các phần tử thuộc một trong hai set, nhưng không thuộc cả hai.
set1 = {1, 2, 3}
set2 = {3, 4, 5}
symmetric_difference_set = set1 ^ set2 # {1, 2, 4, 5}
3. Ứng dụng:
- Loại bỏ trùng lặp:
my_list = [1, 2, 2, 3, 3, 3]
unique_elements = set(my_list) # {1, 2, 3}
- Kiểm tra phần tử:
my_set = {1, 2, 3}
if 2 in my_set:
print("2 có trong set")
-
Phân tích dữ liệu: Tìm kiếm các phần tử chung, phần tử khác biệt giữa các tập dữ liệu.
-
Xử lý văn bản: Loại bỏ các từ trùng lặp trong một văn bản.
4. frozenset:
frozenset là phiên bản bất biến (immutable) của set. Bạn không thể thay đổi nội dung của frozenset sau khi tạo. frozenset thường được sử dụng khi bạn cần một set làm key trong dictionary hoặc phần tử trong một set khác.
Ví dụ:
frozen_set = frozenset([1, 2, 3])
10.1. Set Literals
Set literals là cách biểu diễn tập hợp (set) một cách trực tiếp trong code Python, sử dụng dấu ngoặc nhọn {}. Chúng cung cấp một cách ngắn gọn và dễ đọc để tạo ra các set.
Cú pháp:
{phan_tu_1, phan_tu_2, ..., phan_tu_n}
Ví dụ:
my_set = {1, 2, 3, 4}
Lưu ý:
- Các phần tử trong set literal phải là hashable, nghĩa là chúng phải có giá trị hash code không đổi và có thể so sánh bằng nhau.
- Thứ tự các phần tử trong set literal không quan trọng, vì set không có thứ tự.
- Các phần tử trùng lặp sẽ tự động bị loại bỏ.
So sánh với constructor set():
Set literals thường được ưa chuộng hơn so với việc sử dụng constructor set() vì chúng ngắn gọn và dễ đọc hơn. Ngoài ra, set literals cũng có hiệu năng tốt hơn vì Python có thể tạo ra set trực tiếp mà không cần phải thực hiện các bước trung gian như tra cứu constructor và xây dựng list.
# Sử dụng set literal
my_set1 = {1, 2, 3}
# Sử dụng constructor set()
my_set2 = set([1, 2, 3])
Tập hợp rỗng:
Không có cú pháp literal cho tập hợp rỗng. Bạn phải sử dụng constructor set() để tạo ra một tập hợp rỗng.
empty_set = set()
frozenset literals:
Không có cú pháp literal cho frozenset. Bạn phải sử dụng constructor frozenset() để tạo ra frozenset.
frozen_set = frozenset([1, 2, 3])
Ví dụ ứng dụng:
- Loại bỏ trùng lặp:
my_list = [1, 2, 2, 3, 3, 3]
unique_elements = {*my_list} # {1, 2, 3}
- Kiểm tra phần tử:
my_set = {1, 2, 3}
if 2 in my_set:
print("2 có trong set")
Tóm lại:
Set literals là một cách tiện lợi và hiệu quả để tạo ra các set trong Python. Sử dụng set literals giúp code của bạn ngắn gọn, dễ đọc và có hiệu năng tốt hơn.
10.2. Set Comprehensions
Set comprehensions (setcomps) đã được thêm vào từ Python 2.7, cùng với dictcomps mà chúng ta đã thấy trong “dict Comprehensions” ở trang 79. Ví dụ 3-15 cho thấy cách thức.
Ví dụ 3-15. Xây dựng một set các ký tự Latin-1 có từ “SIGN” trong tên Unicode của chúng
>>> from unicodedata import name
>>> {chr(i) for i in range(32, 256) if 'SIGN' in name(chr(i),'')}
{'§', '=', '¢', '#', '¤', '<', '¥', 'µ', '×', '$', '¶', '£', '©',
'°', '+', '÷', '±', '>', '¬', '®', '%'}
- Import hàm
nametừunicodedatađể lấy tên ký tự. - Xây dựng set các ký tự có mã từ 32 đến 255 có từ ‘SIGN’ trong tên của chúng.
Thứ tự của đầu ra thay đổi cho mỗi process Python, vì salted hash được đề cập trong “What Is Hashable” ở trang 84.
11. Practical Consequences of How Sets Work
Các kiểu set và frozenset đều được triển khai bằng bảng băm (hash table). Điều này có những tác động sau:
- Các phần tử của set phải là các đối tượng hashable. Chúng phải triển khai các phương thức
__hash__và__eq__phù hợp như được mô tả trong “What Is Hashable” ở trang 84. - Kiểm tra thành viên (membership testing) rất hiệu quả. Một set có thể có hàng triệu phần tử, nhưng một phần tử có thể được định vị trực tiếp bằng cách tính mã băm (hash code) của nó và lấy offset chỉ mục, với chi phí có thể là một số lần thử nhỏ để tìm phần tử khớp hoặc kết thúc tìm kiếm.
- Set có chi phí bộ nhớ (memory overhead) đáng kể, so với mảng con trỏ cấp thấp tới các phần tử của nó—sẽ nhỏ gọn hơn nhưng cũng chậm hơn nhiều khi tìm kiếm ngoài một số ít phần tử.
- Thứ tự phần tử phụ thuộc vào thứ tự chèn, nhưng không theo cách hữu ích hoặc đáng tin cậy. Nếu hai phần tử khác nhau nhưng có cùng mã băm, vị trí của chúng phụ thuộc vào phần tử nào được thêm vào trước.
- Việc thêm phần tử vào set có thể thay đổi thứ tự của các phần tử hiện có. Đó là bởi vì thuật toán trở nên kém hiệu quả hơn nếu bảng băm đầy hơn hai phần ba, vì vậy Python có thể cần di chuyển và thay đổi kích thước bảng khi nó phát triển. Khi điều này xảy ra, các phần tử được chèn lại và thứ tự tương đối của chúng có thể thay đổi.
Xem “Internals of sets and dicts” tại fluentpython.com để biết chi tiết.
Bây giờ chúng ta hãy xem xét các loại hoạt động phong phú được cung cấp bởi set.
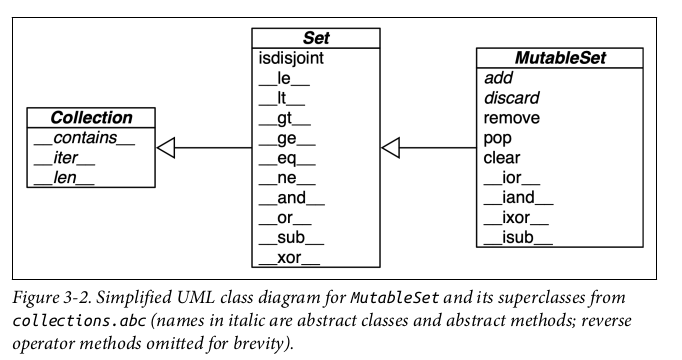
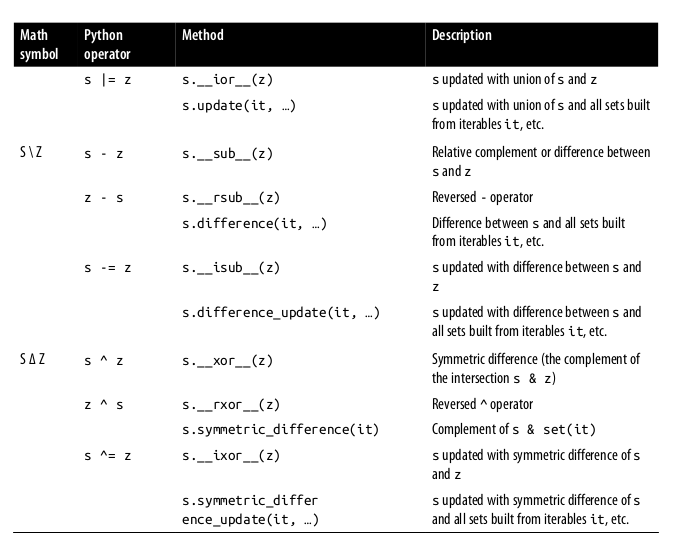
11.1. Set Operations



12. Set Operations on dict Views