[Fluent python] Chapter 2. An array of sequences
Trước khi tạo ra Python, Guido là một người đóng góp cho ngôn ngữ ABC—một dự án nghiên cứu kéo dài 10 năm nhằm thiết kế một môi trường lập trình cho người mới bắt đầu. ABC đã giới thiệu nhiều ý tưởng mà bây giờ chúng ta coi là “Pythonic”: các thao tác chung trên các loại chuỗi khác nhau, các kiểu tuple và mapping tích hợp sẵn, cấu trúc bằng cách thụt lề, kiểu gõ mạnh mà không cần khai báo biến, và nhiều hơn nữa. Không phải ngẫu nhiên mà Python lại thân thiện với người dùng đến vậy.
Python được kế thừa từ ABC cách xử lý thống nhất các chuỗi. Chuỗi ký tự, danh sách, chuỗi byte, mảng, phần tử XML và kết quả cơ sở dữ liệu chia sẻ một tập hợp phong phú các thao tác chung, bao gồm lặp, cắt lát, sắp xếp và nối.
Hiểu được sự đa dạng của các chuỗi có sẵn trong Python giúp chúng ta không phải “tái tạo lại bánh xe”, và giao diện chung của chúng truyền cảm hứng cho chúng ta tạo ra các API hỗ trợ và tận dụng đúng cách các kiểu chuỗi hiện có và trong tương lai.
Hầu hết các cuộc thảo luận trong chương này áp dụng cho các chuỗi nói chung, từ danh sách quen thuộc đến các kiểu str và bytes được thêm vào trong Python 3. Các chủ đề cụ thể về danh sách, tuple, mảng và hàng đợi cũng được đề cập ở đây, nhưng các chi tiết cụ thể của chuỗi Unicode và chuỗi byte xuất hiện trong Chương 4. Ngoài ra, ý tưởng ở đây là đề cập đến các kiểu chuỗi đã sẵn sàng để sử dụng. Việc tạo các kiểu chuỗi của riêng bạn là chủ đề của Chương 12.
Table of content
- Overview of Built-In Sequences
- List Comprehensions and Generator Expressions
- Tuples Are Not Just Immutable Lists
- Unpacking Sequences and Iterables
- Pattern Matching with Sequences
- Slicing
- Using + and * with Sequences
- list.sort Versus the sorted Built-In
- When a List Is Not the Answer
- 9.1. Array
- 9.2. Memory View
- 9.3. NumPy
- 9.4. Deques và các hàng đợi khác
1. Overview of Built-In Sequences
Thư viện chuẩn của Python cung cấp một tập hợp đa dạng các kiểu dữ liệu dạng chuỗi (sequence types) được triển khai bằng ngôn ngữ C:
1. Chuỗi chứa (Container sequences):
- Có thể chứa các phần tử thuộc nhiều kiểu dữ liệu khác nhau, bao gồm cả các chuỗi lồng nhau.
- Ví dụ:
list,tuple, vàcollections.deque.
2. Chuỗi phẳng (Flat sequences):
- Chỉ chứa các phần tử thuộc cùng một kiểu dữ liệu đơn giản.
- Ví dụ:
str,bytes, vàarray.array.
Một chuỗi chứa lưu trữ các tham chiếu đến các đối tượng mà nó chứa, các đối tượng này có thể thuộc bất kỳ kiểu dữ liệu nào. Trong khi đó, một chuỗi phẳng lưu trữ giá trị của nội dung trực tiếp trong không gian bộ nhớ của chính nó, không phải dưới dạng các đối tượng Python riêng biệt.
Do đó, chuỗi phẳng thường nhỏ gọn hơn, nhưng chúng bị giới hạn trong việc lưu trữ các giá trị nguyên thủy của máy tính như byte, số nguyên và số thực.
Mỗi đối tượng Python trong bộ nhớ đều có một phần header chứa siêu dữ liệu. Đối tượng Python đơn giản nhất, một số thực, có một trường giá trị và hai trường siêu dữ liệu:
ob_refcnt: số lượng tham chiếu đến đối tượng.ob_type: con trỏ trỏ đến kiểu dữ liệu của đối tượng.ob_fval: một kiểu dữ liệudoublecủa C lưu trữ giá trị của số thực. Trên một bản dựng Python 64-bit, mỗi trường này chiếm 8 byte. Đó là lý do tại sao một mảng các số thực nhỏ gọn hơn nhiều so với một tuple các số thực: mảng là một đối tượng duy nhất lưu trữ các giá trị thô của các số thực, trong khi tuple bao gồm nhiều đối tượng - bản thân tuple và mỗi đối tượng số thực chứa trong đó.
Một cách khác để phân loại các kiểu dữ liệu dạng chuỗi là dựa trên tính khả biến (mutability):
1. Chuỗi khả biến (Mutable sequences):
- Có thể thay đổi nội dung sau khi được tạo.
- Ví dụ:
list,bytearray,array.array, vàcollections.deque.
2. Chuỗi bất biến (Immutable sequences):
- Không thể thay đổi nội dung sau khi được tạo.
- Ví dụ:
tuple,str, vàbytes.
Hình 2-2 giúp hình dung cách các chuỗi khả biến kế thừa tất cả các phương thức từ các chuỗi bất biến và triển khai thêm một số phương thức bổ sung. Các kiểu chuỗi cụ thể tích hợp sẵn không thực sự kế thừa từ các lớp cơ sở trừu tượng (ABC) Sequence và MutableSequence, nhưng chúng là các lớp con ảo được đăng ký với các ABC đó - như chúng ta sẽ thấy trong Chương 13. Là các lớp con ảo, tuple và list vượt qua các kiểm tra này:
>>> from collections import abc
>>> issubclass(tuple, abc.Sequence)
True
>>> issubclass(list, abc.MutableSequence)
True
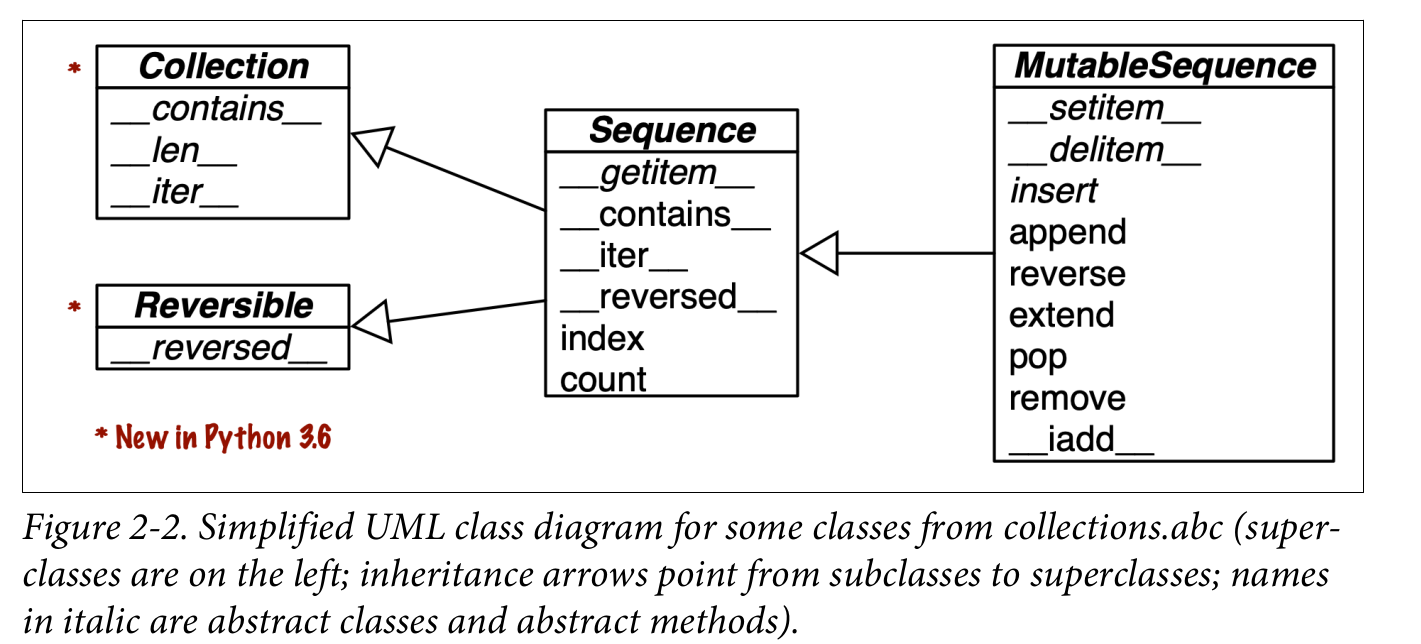
Hãy ghi nhớ những đặc điểm chung này: khả biến so với bất biến; chứa so với phẳng. Chúng hữu ích để suy rộng những gì bạn biết về một kiểu chuỗi sang các kiểu khác.
Kiểu chuỗi cơ bản nhất là list: một chuỗi chứa khả biến. Tôi hy vọng bạn đã rất quen thuộc với list, vì vậy chúng ta sẽ đi thẳng vào list comprehension, một cách mạnh mẽ để xây dựng danh sách mà đôi khi không được sử dụng đầy đủ vì cú pháp có thể trông lạ lùng lúc đầu. Nắm vững list comprehension sẽ mở ra cánh cửa cho generator expression, thứ mà - trong số các mục đích sử dụng khác - có thể tạo ra các phần tử để lấp đầy các chuỗi thuộc bất kỳ loại nào. Cả hai là chủ đề của phần tiếp theo.
2. List Comprehensions and Generator Expressions
Một cách nhanh chóng để xây dựng một chuỗi là sử dụng list comprehension (nếu mục tiêu là một list) hoặc generator expression (cho các loại chuỗi khác). Nếu bạn không sử dụng các dạng cú pháp này hàng ngày, tôi cá là bạn đang bỏ lỡ cơ hội để viết mã dễ đọc hơn và thường nhanh hơn cùng một lúc.
Nếu bạn nghi ngờ tuyên bố của tôi rằng các cấu trúc này “dễ đọc hơn”, hãy đọc tiếp. Tôi sẽ cố gắng thuyết phục bạn.
- List comprehension: Một cách viết ngắn gọn để tạo danh sách mới từ một danh sách hiện có, bằng cách áp dụng một biểu thức cho từng phần tử và lọc các phần tử theo điều kiện.
- Generator expression: Tương tự như list comprehension nhưng tạo ra một generator, một đối tượng lười biếng chỉ tạo ra các phần tử khi được yêu cầu.
2.1. List Comprehensions and Readability
Example 2-1. Build a list of Unicode code points from a string
>>> symbols = '$¢£¥€¤'
>>> codes = []
>>> for symbol in symbols:
...
codes.append(ord(symbol))
...
>>> codes
[36, 162, 163, 165, 8364, 164]
Example 2-2. Build a list of Unicode code points from a string, using a listcomp
>>> symbols = '$¢£¥€¤'
>>> codes = [ord(symbol) for symbol in symbols]
>>> codes
[36, 162, 163, 165, 8364, 164]
Bất kỳ ai biết chút ít về Python đều có thể đọc Ví dụ 2-1. Tuy nhiên, sau khi học về listcomps (danh sách rút gọn), tôi thấy Ví dụ 2-2 dễ đọc hơn vì ý định của nó rõ ràng hơn.
Vòng lặp for có thể được sử dụng để làm rất nhiều việc khác nhau: quét một chuỗi để đếm hoặc chọn các mục, tính toán các giá trị tổng hợp (tổng, trung bình) hoặc bất kỳ nhiệm vụ nào khác. Mã trong Ví dụ 2-1 đang xây dựng một danh sách. Ngược lại, listcomp rõ ràng hơn. Mục tiêu của nó luôn là xây dựng một danh sách mới.
Tất nhiên, có thể lạm dụng listcomp để viết mã thực sự khó hiểu. Tôi đã thấy mã Python với listcomp được sử dụng chỉ để lặp lại một khối mã cho các tác dụng phụ của nó. Nếu bạn không làm gì với danh sách được tạo ra, bạn không nên sử dụng cú pháp đó. Ngoài ra, hãy cố gắng giữ cho nó ngắn gọn. Nếu listcomp kéo dài hơn hai dòng, tốt nhất là nên tách nó ra hoặc viết lại nó dưới dạng vòng lặp for thông thường. Hãy sử dụng khả năng phán đoán tốt nhất của bạn: đối với Python, cũng như đối với tiếng Anh, không có quy tắc cứng nhắc nào cho việc viết rõ ràng.
Trong mã Python, các ngắt dòng bị bỏ qua bên trong các cặp [], {}, hoặc (). Vì vậy, bạn có thể xây dựng danh sách nhiều dòng, listcomp, tuple, từ điển, v.v., mà không cần sử dụng ký tự thoát tiếp tục dòng \, ký tự này sẽ không hoạt động nếu bạn vô tình nhập dấu cách sau nó. Ngoài ra, khi các cặp dấu phân cách đó được sử dụng để xác định một giá trị với một loạt các mục được phân tách bằng dấu phẩy, dấu phẩy ở cuối sẽ bị bỏ qua. Vì vậy, ví dụ, khi viết một giá trị danh sách nhiều dòng, nên đặt dấu phẩy sau mục cuối cùng, giúp cho người viết mã tiếp theo dễ dàng thêm một mục khác vào danh sách đó hơn một chút và giảm nhiễu khi đọc diffs.
Phạm vi cục bộ trong các biểu thức rút gọn và biểu thức tạo
Trong Python 3, listcomp, biểu thức tạo và các anh chị em của chúng là setcomp và dictcomp, có một phạm vi cục bộ để chứa các biến được gán trong mệnh đề for.
Tuy nhiên, các biến được gán bằng “toán tử Walrus” := vẫn có thể truy cập được sau khi các biểu thức rút gọn hoặc biểu thức đó trả về — không giống như các biến cục bộ trong một hàm. PEP 572 — Biểu thức gán xác định phạm vi của mục tiêu của := là hàm bao quanh, trừ khi có khai báo global hoặc nonlocal cho mục tiêu đó.
>>> x = 'ABC'
>>> codes = [ord(x) for x in x]
>>> x
'ABC'
>>> codes
[65, 66, 67]
>>> codes = [last := ord(c) for c in x]
>>> last
67
>>> c
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
NameError: name 'c' is not defined
Listcomp xây dựng danh sách từ các chuỗi hoặc bất kỳ loại có thể lặp lại nào khác bằng cách lọc và chuyển đổi các mục. Các hàm dựng sẵn filter và map có thể được kết hợp để làm điều tương tự, nhưng khả năng đọc bị ảnh hưởng, như chúng ta sẽ thấy tiếp theo.
2.2. Listcomps Versus map and filter
Listcomps (list comprehensions) trong Python có thể thực hiện tất cả những gì mà hàm map và filter làm được, mà không cần phải sử dụng lambda - vốn bị hạn chế về mặt chức năng trong Python. Ví dụ như trong Example 2-3:
Example 2-3: Cùng một list được tạo bởi listcomp và kết hợp map/filter
>>> symbols = '$¢£¥€¤'
>>> beyond_ascii = [ord(s) for s in symbols if ord(s) > 127]
>>> beyond_ascii
[162, 163, 165, 8364, 164]
>>> beyond_ascii = list(filter(lambda c: c > 127, map(ord, symbols)))
>>> beyond_ascii
[162, 163, 165, 8364, 164]
Trước đây tôi từng nghĩ rằng map và filter nhanh hơn so với listcomps tương đương, nhưng Alex Martelli đã chỉ ra rằng điều đó không đúng - ít nhất là không phải trong các ví dụ trước. Script 02-array-seq/listcomp_speed.py trong Fluent Python code repository là một bài kiểm tra tốc độ đơn giản so sánh listcomp với filter/map.
Tôi sẽ nói thêm về map và filter trong Chapter 7. Bây giờ chúng ta chuyển sang việc sử dụng listcomps để tính toán tích Descartes (Cartesian products): một list chứa các tuple được xây dựng từ tất cả các item từ hai hoặc nhiều list.
2.3. Tích Descartes (Cartesian Products)
Listcomps (list comprehensions) có thể xây dựng các list từ tích Descartes của hai hoặc nhiều iterables. Các item tạo nên tích Descartes là các tuple được tạo từ các item của mỗi iterable đầu vào. List kết quả có độ dài bằng tích của độ dài các iterable đầu vào.
Ví dụ, giả sử bạn cần tạo ra một list các áo phông có sẵn trong hai màu và ba kích cỡ. Example 2-4 cho thấy cách tạo ra list đó bằng cách sử dụng listcomp. Kết quả có sáu item.
Example 2-4: Tích Descartes (Cartesian product) sử dụng list comprehension
>>> colors = ['black', 'white']
>>> sizes = ['S', 'M', 'L']
>>> tshirts = [(color, size) for color in colors for size in sizes]
>>> tshirts
[('black', 'S'), ('black', 'M'), ('black', 'L'), ('white', 'S'),
('white', 'M'), ('white', 'L')]
>>> for color in colors:
... for size in sizes:
... print((color, size))
...
('black', 'S')
('black', 'M')
('black', 'L')
('white', 'S')
('white', 'M')
('white', 'L')
>>> tshirts = [(color, size) for size in sizes
... for color in colors]
>>> tshirts
[('black', 'S'), ('white', 'S'), ('black', 'M'), ('white', 'M'),
('black', 'L'), ('white', 'L')]
Listcomps chỉ có một chức năng duy nhất: chúng xây dựng các list. Để tạo dữ liệu cho các kiểu sequence khác, genexp (generator expression) là cách nên làm. Phần tiếp theo là một cái nhìn ngắn gọn về genexps trong bối cảnh xây dựng các sequence không phải là list.
2.4. Generator Expressions
Để khởi tạo các tuple, array và các kiểu sequence khác, bạn cũng có thể bắt đầu từ một listcomp, nhưng genexp (generator expression) tiết kiệm bộ nhớ hơn vì nó sinh ra các item một cách lần lượt bằng cách sử dụng iterator protocol thay vì xây dựng toàn bộ list chỉ để đưa vào một constructor khác.
Genexps sử dụng cú pháp tương tự như listcomps, nhưng được đặt trong dấu ngoặc đơn thay vì dấu ngoặc vuông.
Example 2-5: Khởi tạo tuple và array từ generator expression
>>> symbols = '$¢£¥€¤'
>>> tuple(ord(symbol) for symbol in symbols)
(36, 162, 163, 165, 8364, 164)
>>> import array
>>> array.array('I', (ord(symbol) for symbol in symbols))
array('I', [36, 162, 163, 165, 8364, 164])
Example 2-6: sử dụng genexp với tích Descartes (Cartesian product) để in ra danh sách các áo phông có hai màu và ba kích cỡ. Trái ngược với Example 2-4, ở đây list sáu item của áo phông không bao giờ được xây dựng trong bộ nhớ: generator expression cung cấp cho vòng lặp for, tạo ra từng item một. Nếu hai list được sử dụng trong tích Descartes có một nghìn item mỗi list, thì việc sử dụng generator expression sẽ tiết kiệm chi phí xây dựng một list với một triệu item chỉ để cung cấp cho vòng lặp for.
Example 2-6: Tích Descartes (Cartesian product) trong generator expression
>>> colors = ['black', 'white']
>>> sizes = ['S', 'M', 'L']
>>> for tshirt in (f'{c} {s}' for c in colors for s in sizes):
... print(tshirt)
...
black S
black M
black L
white S
white M
white L
3. Tuples Are Not Just Immutable Lists
Một số tài liệu hướng dẫn về Python giới thiệu tuples như là “immutable lists” (danh sách không thể thay đổi), nhưng điều đó chưa đánh giá hết được vai trò của chúng. Tuples thực hiện hai nhiệm vụ: chúng có thể được sử dụng như những immutable lists và cũng như những records (bản ghi) không có tên trường. Cách sử dụng này đôi khi bị bỏ qua, vì vậy chúng ta sẽ bắt đầu với nó.
3.1. Tuples như bản ghi (Records)
Tuples lưu giữ các bản ghi: mỗi phần tử trong tuple chứa dữ liệu cho một trường, và vị trí của phần tử đó mang ý nghĩa của nó.
Nếu bạn coi tuple chỉ như một list bất biến (immutable), số lượng và thứ tự của các phần tử có thể quan trọng hoặc không, tùy thuộc vào ngữ cảnh. Nhưng khi sử dụng tuple như một tập hợp các trường, số lượng phần tử thường cố định và thứ tự của chúng luôn quan trọng.
Ví dụ 2-7 cho thấy các tuple được sử dụng làm bản ghi. Lưu ý rằng trong mỗi biểu thức, việc sắp xếp tuple sẽ phá hủy thông tin vì ý nghĩa của mỗi trường được xác định bởi vị trí của nó trong tuple.
Ví dụ 2-7. Tuples được sử dụng làm bản ghi
>>> lax_coordinates = (33.9425, -118.408056)
>>> city, year, pop, chg, area = ('Tokyo', 2003, 32_450, 0.66, 8014)
>>> traveler_ids = [('USA', '31195855'), ('BRA', 'CE342567'),
...
('ESP', 'XDA205856')]
>>> for passport in sorted(traveler_ids):
...
print('%s/%s' % passport)
...
BRA/CE342567
ESP/XDA205856
USA/31195855
>>> for country, _ in traveler_ids:
...
print(country)
...
USA
BRA
ESP
Nhìn chung, sử dụng
_làm biến giả chỉ là một quy ước. Nó chỉ là một tên biến lạ nhưng hợp lệ. Tuy nhiên, trong câu lệnhmatch/case,_là một ký tự đại diện khớp với bất kỳ giá trị nào nhưng không bị ràng buộc với một giá trị. Xem “Pattern Matching with Sequences” trên trang 38. Và trong bảng điều khiển Python, kết quả của lệnh trước đó được gán cho_—trừ khi kết quả làNone.
Chúng ta thường nghĩ về bản ghi như các cấu trúc dữ liệu với các trường được đặt tên. Chương 5 trình bày hai cách tạo tuple với các trường được đặt tên.
Nhưng thông thường, không cần phải tạo một class chỉ để đặt tên cho các trường, đặc biệt nếu bạn tận dụng unpacking và tránh sử dụng chỉ mục để truy cập các trường. Trong Ví dụ 2-7, chúng ta đã gán ('Tokyo', 2003, 32_450, 0.66, 8014) cho city, year, pop, chg, area trong một câu lệnh duy nhất. Sau đó, toán tử % đã gán mỗi phần tử trong tuple passport vào vị trí tương ứng trong chuỗi định dạng trong đối số print. Đó là hai ví dụ về tuple unpacking.
Thuật ngữ tuple unpacking được sử dụng rộng rãi bởi các Pythonista, nhưng iterable unpacking đang dần phổ biến, như trong tiêu đề của PEP 3132 — Extended Iterable Unpacking. “Unpacking Sequences and Iterables” trên trang 35 trình bày nhiều hơn về việc unpacking không chỉ tuple mà còn cả sequences và iterables nói chung.
3.2. Tuples như List bất biến (Immutable Lists)
Trình thông dịch Python và thư viện chuẩn sử dụng rộng rãi tuple như list bất biến, và bạn cũng nên làm như vậy. Điều này mang lại hai lợi ích chính:
Clarity (Rõ ràng)
Khi bạn thấy một tuple trong code, bạn biết rằng độ dài của nó sẽ không bao giờ thay đổi.
Performance (Hiệu suất)
Một tuple sử dụng ít bộ nhớ hơn một list có cùng độ dài và nó cho phép Python thực hiện một số tối ưu hóa.
Tuy nhiên, lưu ý rằng tính bất biến của tuple chỉ áp dụng cho các tham chiếu (references) chứa trong đó. Các tham chiếu trong một tuple không thể bị xóa hoặc thay thế. Nhưng nếu một trong những tham chiếu đó trỏ đến một đối tượng có thể thay đổi (mutable object), và đối tượng đó bị thay đổi, thì giá trị của tuple cũng thay đổi. Đoạn mã sau minh họa điểm này bằng cách tạo hai tuple—a và b—ban đầu bằng nhau. Hình 2-4 biểu diễn bố cục ban đầu của tuple b trong bộ nhớ.
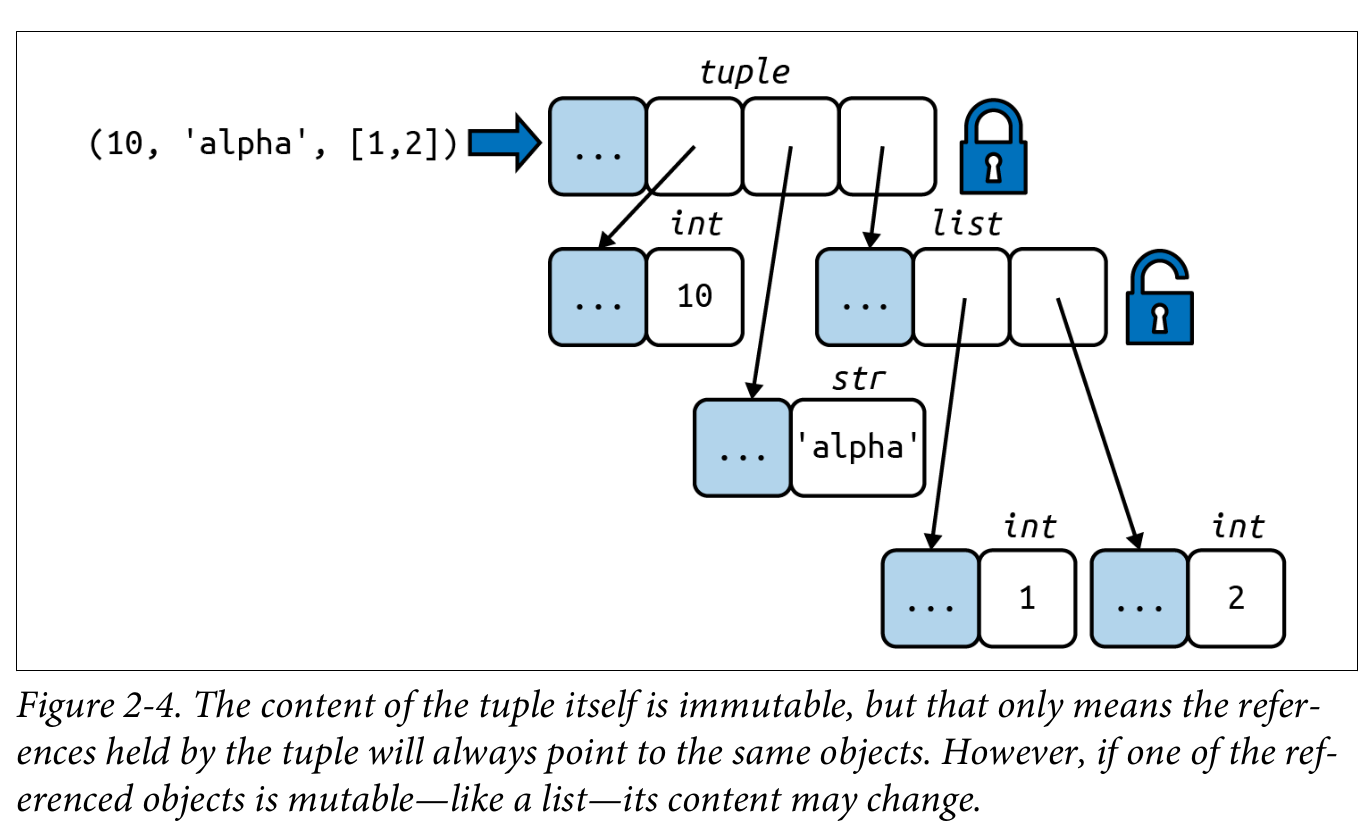
Khi phần tử cuối cùng trong b bị thay đổi, b và a trở nên khác nhau:
>>> a = (10, 'alpha', [1, 2])
>>> b = (10, 'alpha', [1, 2])
>>> a == b
True
>>> b[-1].append(99)
>>> a == b
False
>>> b
(10, 'alpha', [1, 2, 99])
Tuple với các phần tử có thể thay đổi có thể là nguồn gốc của lỗi. Như chúng ta sẽ thấy trong “What Is Hashable” trên trang 84, một đối tượng chỉ có thể băm (hashable) nếu giá trị của nó không bao giờ thay đổi. Một tuple không thể băm không thể được chèn làm khóa dict hoặc phần tử set.
Nếu bạn muốn xác định rõ ràng liệu một tuple (hoặc bất kỳ đối tượng nào) có giá trị cố định hay không, bạn có thể sử dụng hàm hash tích hợp sẵn để tạo một hàm fixed như sau:
>>> def fixed(o):
... try:
... hash(o)
... except TypeError:
... return False
... return True
...
>>> tf = (10, 'alpha', (1, 2))
>>> tm = (10, 'alpha', [1, 2])
>>> fixed(tf)
True
>>> fixed(tm)
False
Chúng ta sẽ khám phá vấn đề này sâu hơn trong “The Relative Immutability of Tuples” trên trang 207.
Mặc dù có lưu ý này, tuple vẫn được sử dụng rộng rãi như list bất biến. Chúng cung cấp một số lợi thế về hiệu suất được giải thích bởi nhà phát triển lõi Python Raymond Hettinger trong một câu trả lời trên StackOverflow cho câu hỏi: “Are tuples more efficient than lists in Python?”. Tóm lại, Hettinger đã viết:
- Để đánh giá một tuple literal, trình biên dịch Python tạo ra bytecode cho một hằng số tuple trong một thao tác; nhưng đối với một list literal, bytecode được tạo ra sẽ đẩy từng phần tử như một hằng số riêng biệt vào ngăn xếp dữ liệu (data stack) và sau đó xây dựng list.
- Với một tuple
t,tuple(t)chỉ đơn giản là trả về một tham chiếu đến cùng mộtt. Không cần phải sao chép. Ngược lại, với một listl, hàm tạolist(l)phải tạo một bản sao mới củal. - Do độ dài cố định, một instance tuple được cấp phát chính xác không gian bộ nhớ mà nó cần. Mặt khác, các instance của list được cấp phát với dung lượng dự phòng để khấu hao chi phí cho các lần thêm phần tử (append) trong tương lai.
- Các tham chiếu đến các phần tử trong một tuple được lưu trữ trong một mảng trong cấu trúc tuple, trong khi một list chứa một con trỏ đến một mảng các tham chiếu được lưu trữ ở nơi khác. Việc gián tiếp là cần thiết vì khi một list phát triển vượt quá không gian hiện được cấp phát, Python cần phải cấp phát lại mảng các tham chiếu để tạo thêm dung lượng. Việc gián tiếp thêm này làm cho bộ nhớ đệm CPU kém hiệu quả hơn.
3.3. So sánh các phương thức của Tuple và List
Khi sử dụng tuple như một biến thể bất biến của list, điều quan trọng là phải biết API của chúng giống nhau như thế nào. Như bạn có thể thấy trong Bảng 2-1, tuple hỗ trợ tất cả các phương thức list mà không liên quan đến việc thêm hoặc xóa phần tử, ngoại trừ một trường hợp—tuple thiếu phương thức __reversed__. Tuy nhiên, đó chỉ là để tối ưu hóa; reversed(my_tuple) vẫn hoạt động mà không cần nó.


4. Unpacking Sequences and Iterables
Giải nén (Unpacking) là một kỹ thuật quan trọng trong Python giúp tránh việc sử dụng chỉ mục (index) để trích xuất các phần tử từ chuỗi, vốn không cần thiết và dễ gây ra lỗi. Hơn nữa, giải nén hoạt động với bất kỳ đối tượng lặp (iterable) nào làm nguồn dữ liệu - bao gồm cả iterator, những đối tượng không hỗ trợ ký hiệu chỉ mục ([]). Yêu cầu duy nhất là đối tượng lặp phải tạo ra chính xác một mục cho mỗi biến ở đầu nhận, trừ khi bạn sử dụng dấu sao (*) để thu thập các mục dư thừa, như được giải thích trong phần “Sử dụng * để lấy các mục dư thừa” trên trang 36.
Hình thức rõ ràng nhất của giải nén là gán song song (parallel assignment); nghĩa là, gán các mục từ một đối tượng lặp cho một tuple các biến, như bạn có thể thấy trong ví dụ này:
>>> lax_coordinates = (33.9425, -118.408056)
>>> latitude, longitude = lax_coordinates # unpacking
>>> latitude
33.9425
>>> longitude
-118.408056
Một ứng dụng thú vị của giải nén là hoán đổi giá trị của các biến mà không cần sử dụng biến tạm thời:
>>> b, a = a, b
Một ví dụ khác về giải nén là thêm tiền tố * vào một đối số khi gọi hàm:
>>> divmod(20, 8)
(2, 4)
>>> t = (20, 8)
>>> divmod(*t)
(2, 4)
>>> quotient, remainder = divmod(*t)
>>> quotient, remainder
(2, 4)
Đoạn mã trên cho thấy một cách sử dụng khác của giải nén: cho phép các hàm trả về nhiều giá trị một cách thuận tiện cho người gọi. Ví dụ, hàm os.path.split() tạo ra một tuple (path, last_part) từ một đường dẫn hệ thống tệp:
>>> import os
>>> _, filename = os.path.split('/home/luciano/.ssh/id_rsa.pub')
>>> filename
'id_rsa.pub'
Một cách khác để chỉ sử dụng một số mục khi giải nén là sử dụng cú pháp *, như chúng ta sẽ thấy ngay sau đây.
4.1. Sử dụng * để lấy các mục dư thừa (Using * to Grab Excess Items)
Việc định nghĩa các tham số hàm với *args để lấy các đối số dư thừa tùy ý là một tính năng cổ điển của Python.
Trong Python 3, ý tưởng này đã được mở rộng để áp dụng cho phép gán song song (parallel assignment):
>>> a, b, *rest = range(5)
>>> a, b, rest
(0, 1, [2, 3, 4])
>>> a, b, *rest = range(3)
>>> a, b, rest
(0, 1, [2])
>>> a, b, *rest = range(2)
>>> a, b, rest
(0, 1, [])
Trong ngữ cảnh của phép gán song song, tiền tố * chỉ có thể được áp dụng cho đúng một biến, nhưng nó có thể xuất hiện ở bất kỳ vị trí nào:
>>> a, *body, c, d = range(5)
>>> a, body, c, d
(0, [1, 2], 3, 4)
>>> *head, b, c, d = range(5)
>>> head, b, c, d
([0, 1], 2, 3, 4)
4.2. Giải nén với * trong lời gọi hàm và các literal chuỗi (Unpacking with * in Function Calls and Sequence Literals)
Tính năng này cho phép bạn sử dụng toán tử * để giải nén các iterable (như list, tuple, range) khi gọi hàm hoặc tạo các literal chuỗi (list, tuple, set). Điều này mang lại sự linh hoạt và ngắn gọn trong việc xử lý các chuỗi dữ liệu.
1. Trong lời gọi hàm (Function Calls):
- Trước đây, khi truyền đối số cho hàm, bạn phải truyền từng phần tử riêng lẻ. Với
*, bạn có thể giải nén một iterable và truyền tất cả các phần tử của nó như các đối số riêng biệt. - Đặc biệt, PEP 448 cho phép sử dụng
*nhiều lần trong cùng một lời gọi hàm, giúp kết hợp các iterable và các giá trị riêng lẻ một cách linh hoạt.
Ví dụ:
def fun(a, b, c, d, *rest):
return a, b, c, d, rest
fun(*[1, 2], 3, *range(4, 7)) # Output: (1, 2, 3, 4, (5, 6))
Trong ví dụ này:
*[1, 2]giải nén list[1, 2]thành hai đối số riêng biệt là1và2.*range(4, 7)giải nénrange(4, 7)thành ba đối số4,5,6.- Kết quả là hàm
funđược gọi với 5 đối số, trong đórestnhận tuple(5, 6)chứa các giá trị dư thừa.
2. Trong các literal chuỗi (Sequence Literals):
*cho phép bạn giải nén một iterable trực tiếp bên trong định nghĩa của list, tuple, hoặc set.- Điều này giúp tạo ra các chuỗi mới bằng cách kết hợp các iterable hiện có với các giá trị khác.
Ví dụ:
>>> *range(4), 4 # Output: (0, 1, 2, 3, 4)
>>> [*range(4), 4] # Output: [0, 1, 2, 3, 4]
>>> {*range(4), 4, *(5, 6, 7)} # Output: {0, 1, 2, 3, 4, 5, 6, 7}
Trong ví dụ này:
*range(4)giải nénrange(4)thành các phần tử 0, 1, 2, 3 và thêm chúng vào tuple/list/set.*(5, 6, 7)giải nén tuple(5, 6, 7)và thêm các phần tử vào set.
Tóm lại:
Việc sử dụng * để giải nén iterable trong lời gọi hàm và literal chuỗi mang lại những lợi ích sau:
- Tăng tính linh hoạt: Cho phép kết hợp các iterable và giá trị riêng lẻ một cách dễ dàng.
- Cải thiện khả năng đọc: Code ngắn gọn và dễ hiểu hơn.
- Giảm thiểu lỗi: Tránh việc phải viết code dài dòng và dễ nhầm lẫn khi xử lý nhiều phần tử.
Lưu ý rằng PEP 448 cũng giới thiệu cú pháp tương tự cho ** để giải nén các mapping (như dictionary), chúng ta sẽ tìm hiểu kỹ hơn trong phần “Giải nén ánh xạ”.
4.3. Giải nén lồng nhau (Nested Unpacking)
Mục tiêu của một phép giải nén có thể sử dụng cấu trúc lồng nhau, ví dụ: (a, b, (c, d)). Python sẽ xử lý đúng nếu giá trị có cùng cấu trúc lồng nhau. Ví dụ 2-8 cho thấy giải nén lồng nhau trong thực tế.
Ví dụ 2-8. Giải nén tuple lồng nhau để truy cập kinh độ
metro_areas = [
('Tokyo', 'JP', 36.933, (35.689722, 139.691667)),
('Delhi NCR', 'IN', 21.935, (28.613889, 77.208889)),
('Mexico City', 'MX', 20.142, (19.433333, -99.133333)),
('New York-Newark', 'US', 20.104, (40.808611, -74.020386)),
('São Paulo', 'BR', 19.649, (-23.547778, -46.635833)),
]
def main():
print(f'{"":15} | {"latitude":>9} | {"longitude":>9}')
for name, _, _, (lat, lon) in metro_areas:
if lon <= 0:
print(f'{name:15} | {lat:9.4f} | {lon:9.4f}')
if __name__ == '__main__':
main()
Mỗi tuple chứa một bản ghi với bốn trường, trường cuối cùng là một cặp tọa độ. Bằng cách gán trường cuối cùng cho một tuple lồng nhau, chúng ta giải nén các tọa độ.
Kiểm tra lon <= 0: chỉ chọn các thành phố ở bán cầu Tây.
Đầu ra của Ví dụ 2-8 là:
| latitude | longitude
Mexico City | 19.4333 | -99.1333
New York-Newark | 40.8086 | -74.0204
São Paulo | -23.5478 | -46.6358
Mục tiêu của phép gán giải nén cũng có thể là một list, nhưng các trường hợp sử dụng tốt là rất hiếm. Đây là trường hợp duy nhất tôi biết: nếu bạn có một truy vấn cơ sở dữ liệu trả về một bản ghi duy nhất (ví dụ: mã SQL có mệnh đề LIMIT 1), thì bạn có thể giải nén và đồng thời đảm bảo chỉ có một kết quả với đoạn mã này:
>>> [record] = query_returning_single_row()
Nếu bản ghi chỉ có một trường, bạn có thể lấy trực tiếp, như thế này:
>>> [[field]] = query_returning_single_row_with_single_field()
Cả hai điều này đều có thể được viết bằng tuple, nhưng đừng quên đặc điểm cú pháp là tuple một mục phải được viết với dấu phẩy ở cuối. Vì vậy, mục tiêu đầu tiên sẽ là (record,) và mục tiêu thứ hai là ((field,),). Trong cả hai trường hợp, bạn sẽ gặp lỗi im lặng nếu quên dấu phẩy.
Bây giờ chúng ta hãy nghiên cứu pattern matching, hỗ trợ các cách mạnh mẽ hơn để giải nén chuỗi.
5. Pattern Matching with Sequences
Tính năng mới nổi bật nhất trong Python 3.10 là so khớp mẫu với câu lệnh match/case được đề xuất trong PEP 634—Structural Pattern Matching: Specification.
Dưới đây là ví dụ đầu tiên về match/case xử lý chuỗi. Hãy tưởng tượng bạn đang thiết kế một robot chấp nhận các lệnh được gửi dưới dạng chuỗi các từ và số, như BEEPER 440 3. Sau khi chia thành các phần và phân tích cú pháp các số, bạn sẽ có một thông báo như ['BEEPER', 440, 3]. Bạn có thể sử dụng một phương thức như thế này để xử lý các thông báo đó:
Ví dụ 2-9. Phương thức từ lớp Robot tưởng tượng
def handle_command(self, message):
match message:
case ['BEEPER', frequency, times]:
self.beep(times, frequency)
case ['NECK', angle]:
self.rotate_neck(angle)
case ['LED', ident, intensity]:
self.leds[ident].set_brightness(ident, intensity)
case ['LED', ident, red, green, blue]:
self.leds[ident].set_color(ident, red, green, blue)
case _:
raise InvalidCommand(message)
Biểu thức sau từ khóa match là chủ thể (subject). Chủ thể là dữ liệu mà Python sẽ cố gắng so khớp với các mẫu trong mỗi mệnh đề case.
- Mẫu này khớp với bất kỳ chủ thể nào là một chuỗi có ba mục. Mục đầu tiên phải là chuỗi
'BEEPER'. Mục thứ hai và thứ ba có thể là bất cứ thứ gì và chúng sẽ được liên kết với các biếnfrequencyvàtimes, theo thứ tự đó. - Điều này khớp với bất kỳ chủ thể nào có hai mục, mục đầu tiên là
'NECK'. - Điều này sẽ khớp với một chủ thể có ba mục bắt đầu bằng
'LED'. Nếu số lượng mục không khớp, Python sẽ chuyển sangcasetiếp theo. - Một mẫu chuỗi khác bắt đầu bằng
'LED', bây giờ có năm mục — bao gồm hằng số'LED'. - Đây là trường hợp mặc định. Nó sẽ khớp với bất kỳ chủ thể nào không khớp với mẫu trước đó. Biến
_là đặc biệt, như chúng ta sẽ sớm thấy.
Về bề ngoài, match/case có thể trông giống như câu lệnh switch/case từ ngôn ngữ C — nhưng đó chỉ là một nửa câu chuyện. Một cải tiến quan trọng của match so với switch là phân rã (destructuring) — một dạng giải nén nâng cao hơn. Phân rã là một từ mới trong từ vựng Python, nhưng nó thường được sử dụng trong tài liệu của các ngôn ngữ hỗ trợ so khớp mẫu — như Scala và Elixir.
Ví dụ đầu tiên về phân rã, Ví dụ 2-10 cho thấy một phần của Ví dụ 2-8 được viết lại bằng match/case.
Ví dụ 2-10. Phân rã tuple lồng nhau — yêu cầu Python ≥ 3.10
metro_areas = [
('Tokyo', 'JP', 36.933, (35.689722, 139.691667)),
('Delhi NCR', 'IN', 21.935, (28.613889, 77.208889)),
('Mexico City', 'MX', 20.142, (19.433333, -99.133333)),
('New York-Newark', 'US', 20.104, (40.808611, -74.020386)),
('São Paulo', 'BR', 19.649, (-23.547778, -46.635833)),
]
def main():
print(f'{"":15} | {"latitude":>9} | {"longitude":>9}')
for record in metro_areas:
match record:
case [name, _, _, (lat, lon)] if lon <= 0:
print(f'{name:15} | {lat:9.4f} | {lon:9.4f}')
Chủ thể của match này là record — tức là, mỗi tuple trong metro_areas.
Một mệnh đề case có hai phần: một mẫu (pattern) và một vệ (guard) tùy chọn với từ khóa if.
Nói chung, một mẫu chuỗi khớp với chủ thể nếu:
- Chủ thể là một chuỗi và;
- Chủ thể và mẫu có cùng số lượng mục và;
- Mỗi mục tương ứng khớp, bao gồm cả các mục lồng nhau.
Ví dụ: mẫu [name, _, _, (lat, lon)] trong Ví dụ 2-10 khớp với một chuỗi có bốn mục và mục cuối cùng phải là chuỗi hai mục.
Các mẫu chuỗi có thể được viết dưới dạng tuple hoặc list hoặc bất kỳ tổ hợp nào của tuple và list lồng nhau, nhưng không có gì khác biệt về cú pháp bạn sử dụng: trong mẫu chuỗi, dấu ngoặc vuông và dấu ngoặc đơn có nghĩa giống nhau. Tôi đã viết mẫu dưới dạng list với 2-tuple lồng nhau chỉ để tránh lặp lại dấu ngoặc vuông hoặc dấu ngoặc đơn trong Ví dụ 2-10.
Mẫu chuỗi có thể khớp với các instance của hầu hết các lớp con thực tế hoặc ảo của collections.abc.Sequence, ngoại trừ str, bytes và bytearray.
Các instance của
str,bytesvàbytearraykhông được xử lý dưới dạng chuỗi trong ngữ cảnh củamatch/case. Một chủ thểmatchthuộc một trong các loại đó được coi là một giá trị “nguyên tử” — giống như số nguyên 987 được coi là một giá trị, không phải là một chuỗi các chữ số. Việc coi ba loại đó là chuỗi có thể gây ra lỗi do trùng khớp ngoài ý muốn. Nếu bạn muốn coi một đối tượng thuộc các loại đó là chủ thể chuỗi, hãy chuyển đổi nó trong mệnh đềmatch. Ví dụ: xemtuple(phone)trong phần sau:match tuple(phone): case ['1', *rest]: # Bắc Mỹ và Caribe ... case ['2', *rest]: # Châu Phi và một số vùng lãnh thổ ... case ['3' | '4', *rest]: # Châu Âu ...
Trong thư viện chuẩn, các loại này tương thích với mẫu chuỗi:
listtuplememoryviewrangearray.arraycollections.deque
Không giống như giải nén, các mẫu không phân rã các iterable không phải là chuỗi (chẳng hạn như iterator).
Ký hiệu _ là đặc biệt trong các mẫu: nó khớp với bất kỳ mục đơn lẻ nào ở vị trí đó, nhưng nó không bao giờ bị ràng buộc với giá trị của mục được khớp. Ngoài ra, _ là biến duy nhất có thể xuất hiện nhiều lần trong một mẫu.
Bạn có thể liên kết bất kỳ phần nào của mẫu với một biến bằng cách sử dụng từ khóa as:
case [name, _, _, (lat, lon) as coord]:
Với chủ thể ['Shanghai', 'CN', 24.9, (31.1, 121.3)], mẫu trước đó sẽ khớp và đặt các biến sau:
| Biến | Giá trị |
|---|---|
name |
'Shanghai' |
lat |
31.1 |
lon |
121.3 |
coord |
(31.1, 121.3) |
Chúng ta có thể làm cho các mẫu cụ thể hơn bằng cách thêm thông tin kiểu. Ví dụ: mẫu sau khớp với cùng cấu trúc chuỗi lồng nhau như ví dụ trước, nhưng mục đầu tiên phải là một instance của str và cả hai mục trong 2-tuple phải là instance của float:
case [str(name), _, _, (float(lat), float(lon))]:
Các biểu thức
str(name)vàfloat(lat)trông giống như các lệnh gọi hàm tạo, mà chúng ta sẽ sử dụng để chuyển đổinamevàlatthànhstrvàfloat. Nhưng trong ngữ cảnh của một mẫu, cú pháp đó thực hiện kiểm tra kiểu trong thời gian chạy: mẫu trước đó sẽ khớp với chuỗi bốn mục trong đó mục 0 phải làstrvà mục 3 phải là một cặpfloat. Ngoài ra,strtrong mục 0 sẽ được liên kết với biếnnamevà cácfloattrong mục 3 sẽ được liên kết vớilatvàlontương ứng. Vì vậy, mặc dùstr(name)mượn cú pháp của lệnh gọi hàm tạo, nhưng ngữ nghĩa hoàn toàn khác trong ngữ cảnh của một mẫu. Việc sử dụng các lớp tùy ý trong các mẫu được đề cập trong “So khớp mẫu với các instance lớp” trên trang 192.
Mặt khác, nếu chúng ta muốn khớp với bất kỳ chuỗi chủ thể nào bắt đầu bằng str và kết thúc bằng chuỗi lồng nhau gồm hai float, chúng ta có thể viết:
case [str(name), *_, (float(lat), float(lon))]:
*_ khớp với bất kỳ số lượng mục nào mà không liên kết chúng với một biến. Sử dụng *extra thay vì *_ sẽ liên kết các mục với extra dưới dạng list có từ 0 mục trở lên.
Mệnh đề guard tùy chọn bắt đầu bằng if chỉ được đánh giá nếu mẫu khớp và có thể tham chiếu các biến bị ràng buộc trong mẫu, như trong Ví dụ 2-10:
match record:
case [name, _, _, (lat, lon)] if lon <= 0:
print(f'{name:15} | {lat:9.4f} | {lon:9.4f}')
Khối lồng nhau với câu lệnh print chỉ chạy nếu mẫu khớp và biểu thức guard là đúng.
Phân rã với các mẫu rất biểu cảm đến mức đôi khi một
matchvới mộtcaseduy nhất có thể làm cho mã đơn giản hơn. Guido van Rossum có một bộ sưu tập các ví dụcase/match, bao gồm một ví dụ mà ông đặt tên là “So khớp iterable và kiểu rất sâu với trích xuất”.
Ví dụ 2-10 không phải là một cải tiến so với Ví dụ 2-8. Nó chỉ là một ví dụ để so sánh hai cách làm điều tương tự. Ví dụ tiếp theo cho thấy cách so khớp mẫu góp phần tạo ra mã rõ ràng, ngắn gọn và hiệu quả.
6. Slicing
Một tính năng phổ biến của list, tuple, str, và tất cả các kiểu dữ liệu sequence trong Python là hỗ trợ các thao tác cắt lát (slicing), mạnh mẽ hơn hầu hết mọi người nhận ra.
Trong phần này, chúng ta sẽ mô tả cách sử dụng các dạng cắt lát nâng cao này. Việc triển khai chúng trong một class do người dùng định nghĩa sẽ được đề cập trong Chương 12, phù hợp với triết lý của chúng tôi về việc bao quát các class sẵn sàng sử dụng trong phần này của cuốn sách và tạo các class mới trong Phần III.
6.1. Tại sao Slice và Range loại trừ phần tử cuối cùng?
Quy ước trong Python là loại trừ phần tử cuối cùng trong các slice và range. Điều này hoạt động tốt với cách đánh chỉ số (index) bắt đầu từ 0 được sử dụng trong Python, C và nhiều ngôn ngữ khác.
Một số lợi ích của quy ước này là:
- Dễ dàng nhận biết độ dài của một slice hoặc range khi chỉ có vị trí dừng (stop):
range(3)vàmy_list[:3]đều tạo ra ba phần tử. - Dễ dàng tính toán độ dài của một slice hoặc range khi biết vị trí bắt đầu (start) và dừng (stop): chỉ cần lấy
stop - start. - Dễ dàng chia một chuỗi thành hai phần tại bất kỳ chỉ số
xnào mà không bị chồng chéo: chỉ cần lấymy_list[:x]vàmy_list[x:]. Ví dụ:
>>> l = [10, 20, 30, 40, 50, 60]
>>> l[:2] # chia tại 2
[10, 20]
>>> l[2:]
[30, 40, 50, 60]
>>> l[:3] # chia tại 3
[10, 20, 30]
>>> l[3:]
[40, 50, 60]
Những lập luận tốt nhất cho quy ước này được viết bởi nhà khoa học máy tính người Hà Lan Edsger W. Dijkstra (xem tài liệu tham khảo cuối cùng trong phần “Đọc thêm” ở trang 71).
Bây giờ, hãy xem xét kỹ hơn cách Python diễn giải cú pháp slice.
6.2. Slice Object
Điều này không có gì bí mật, nhưng đáng để nhắc lại: s[a:b:c] có thể được sử dụng để chỉ định một bước nhảy c, khiến cho slice kết quả bỏ qua các phần tử. Bước nhảy cũng có thể là số âm, trả về các phần tử theo thứ tự ngược lại. Ba ví dụ sau đây sẽ làm rõ điều này:
>>> s = 'bicycle'
>>> s[::3]
'bye'
>>> s[::-1]
'elcycib'
>>> s[::-2]
'eccb'
Một ví dụ khác đã được trình bày trong Chương 1 khi chúng ta sử dụng deck[12::13] để lấy tất cả các quân Át trong bộ bài chưa được xáo trộn:
>>> deck[12::13]
[Card(rank='A', suit='spades'), Card(rank='A', suit='diamonds'),
Card(rank='A', suit='clubs'), Card(rank='A', suit='hearts')]
Ký hiệu a:b:c chỉ hợp lệ trong [] khi được sử dụng làm toán tử indexing hoặc subscript, và nó tạo ra một slice object: slice(a, b, c). Như chúng ta sẽ thấy trong phần “Cách thức hoạt động của Slicing” trên trang 404, để đánh giá biểu thức seq[start:stop:step], Python gọi seq.__getitem__(slice(start, stop, step)). Ngay cả khi bạn không tự triển khai các kiểu dữ liệu sequence của riêng mình, việc biết về slice object cũng rất hữu ích vì nó cho phép bạn gán tên cho các slice, giống như bảng tính cho phép đặt tên cho các vùng ô.
Giả sử bạn cần phân tích cú pháp dữ liệu tệp phẳng như hóa đơn được hiển thị trong Ví dụ 2-13. Thay vì điền vào mã của bạn với các slice được mã hóa cứng, bạn có thể đặt tên cho chúng. Hãy xem cách này làm cho vòng lặp for ở cuối ví dụ trở nên dễ đọc như thế nào.
Ví dụ 2-13. Các mục dòng từ hóa đơn tệp phẳng
>>> invoice = """
... 0.....6.................................40........52...55........
... 1909 Pimoroni PiBrella $17.50 3 $52.50
... 1489 6mm Tactile Switch x20 $4.95 2 $9.90
... 1510 Panavise Jr. - PV-201 $28.00 1 $28.00
... 1601 PiTFT Mini Kit 320x240 $34.95 1 $34.95
... """
>>> SKU = slice(0, 6)
>>> DESCRIPTION = slice(6, 40)
>>> UNIT_PRICE = slice(40, 52)
>>> QUANTITY = slice(52, 55)
>>> ITEM_TOTAL = slice(55, None)
>>> line_items = invoice.split('\n')[2:]
>>> for item in line_items:
... print(item[UNIT_PRICE], item[DESCRIPTION])
...
$17.50 Pimoroni PiBrella
$4.95 6mm Tactile Switch x20
$28.00 Panavise Jr. - PV-201
$34.95 PiTFT Mini Kit 320x240
Chúng ta sẽ quay lại với slice object khi thảo luận về việc tạo các bộ sưu tập của riêng bạn trong phần “Vector Take #2: A Sliceable Sequence” trên trang 403. Trong khi đó, từ góc độ người dùng, slicing bao gồm các tính năng bổ sung như slice đa chiều và ký hiệu ellipsis (...). Hãy đọc tiếp.
6.3. Cắt lát đa chiều và Ellipsis
Toán tử [] cũng có thể nhận nhiều chỉ mục hoặc slice được phân tách bằng dấu phẩy. Các phương thức đặc biệt __getitem__ và __setitem__ xử lý toán tử [] chỉ đơn giản là nhận các chỉ mục trong a[i, j] dưới dạng một tuple. Nói cách khác, để đánh giá a[i, j], Python gọi a.__getitem__((i, j)).
Ví dụ, điều này được sử dụng trong package NumPy bên ngoài, trong đó các phần tử của numpy.ndarray hai chiều có thể được truy xuất bằng cú pháp a[i, j] và một slice hai chiều thu được với biểu thức như a[m:n, k:l]. Ví dụ 2-22 ở phần sau của chương này cho thấy cách sử dụng ký hiệu này.
Ngoại trừ memoryview, các kiểu dữ liệu sequence tích hợp trong Python là một chiều, vì vậy chúng chỉ hỗ trợ một chỉ mục hoặc slice, chứ không phải một tuple của chúng.
Ellipsis—được viết bằng ba dấu chấm (...) chứ không phải … (Unicode U+2026)—được trình phân tích cú pháp Python nhận dạng là một token. Nó là một bí danh cho đối tượng Ellipsis, phiên bản duy nhất của lớp ellipsis. Như vậy, nó có thể được truyền dưới dạng một đối số cho các hàm và là một phần của đặc tả slice, như trong f(a, ..., z) hoặc a[i:...].
NumPy sử dụng ... làm lối tắt khi cắt lát các mảng nhiều chiều; ví dụ: nếu x là một mảng bốn chiều, x[i, ...] là lối tắt cho x[i, :, :, :,]. Xem “NumPy quickstart” để tìm hiểu thêm về điều này.
Tại thời điểm viết bài này, tôi không biết về việc sử dụng Ellipsis hoặc chỉ mục và slice đa chiều trong thư viện chuẩn Python. Nếu bạn phát hiện ra một cái, hãy cho tôi biết. Các tính năng cú pháp này tồn tại để hỗ trợ các kiểu do người dùng định nghĩa và các phần mở rộng như NumPy.
Slice không chỉ hữu ích để trích xuất thông tin từ các sequence; chúng cũng có thể được sử dụng để thay đổi các sequence có thể thay đổi tại chỗ—nghĩa là, mà không cần xây dựng lại chúng từ đầu.
6.4. Gán giá trị cho Slice
Các sequence có thể thay đổi (mutable sequences) có thể được ghép, cắt bỏ và sửa đổi tại chỗ bằng cách sử dụng ký hiệu slice ở phía bên trái của câu lệnh gán hoặc làm mục tiêu của câu lệnh del. Một vài ví dụ tiếp theo đưa ra ý tưởng về sức mạnh của ký hiệu này:
>>> l = list(range(10))
>>> l
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> l[2:5] = [20, 30] # Thay thế các phần tử từ chỉ mục 2 đến 4
>>> l
[0, 1, 20, 30, 5, 6, 7, 8, 9]
>>> del l[5:7] # Xóa các phần tử từ chỉ mục 5 đến 6
>>> l
[0, 1, 20, 30, 5, 8, 9]
>>> l[3::2] = [11, 22] # Gán giá trị cho các phần tử từ chỉ mục 3, bước nhảy 2
>>> l
[0, 1, 20, 11, 5, 22, 9]
>>> l[2:5] = 100 # Lỗi: không thể gán một giá trị đơn lẻ cho slice
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can only assign an iterable
>>> l[2:5] = [100] # Gán một list chứa một phần tử
>>> l
[0, 1, 100, 22, 9]
Khi mục tiêu của phép gán là một slice, phía bên phải phải là một iterable object, ngay cả khi nó chỉ có một phần tử.
Mọi lập trình viên đều biết rằng phép nối (concatenation) là một thao tác phổ biến với các sequence. Các hướng dẫn Python cơ bản giải thích việc sử dụng + và * cho mục đích đó, nhưng có một số chi tiết tinh tế về cách chúng hoạt động, mà chúng ta sẽ đề cập tiếp theo.
7. Using + and * with Sequences
Trong Python, các lập trình viên mong đợi rằng chuỗi hỗ trợ phép cộng (+) và phép nhân (*). Thông thường, cả hai toán hạng của phép cộng (+) phải cùng kiểu chuỗi, và không toán hạng nào bị thay đổi, mà một chuỗi mới cùng kiểu được tạo ra như là kết quả của phép nối chuỗi.
Để nối nhiều bản sao của cùng một chuỗi, hãy nhân nó với một số nguyên. Một lần nữa, một chuỗi mới được tạo ra:
>>> l = [1, 2, 3]
>>> l * 5
[1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3, 1, 2, 3]
>>> 5 * 'abcd'
'abcdabcdabcdabcdabcd'
Cả hai phép toán + và * luôn tạo ra một đối tượng mới và không bao giờ thay đổi toán hạng của chúng.
Lưu ý: các biểu thức như
a * nkhialà một chuỗi chứa các mục có thể thay đổi (mutable), bởi vì kết quả có thể khiến bạn ngạc nhiên. Ví dụ, cố gắng khởi tạo một danh sách các danh sách nhưmy_list = [[]] * 3sẽ dẫn đến một danh sách với ba tham chiếu đến cùng một danh sách bên trong, điều này có thể không phải là điều bạn muốn.
Phần tiếp theo sẽ đề cập đến các cạm bẫy khi cố gắng sử dụng * để khởi tạo một danh sách các danh sách.
7.1. Building Lists of Lists
Đôi khi chúng ta cần khởi tạo một danh sách với một số lượng danh sách lồng nhau nhất định - ví dụ, để phân phối học sinh vào một danh sách các nhóm hoặc để biểu diễn các ô vuông trên bàn cờ. Cách tốt nhất để làm điều đó là sử dụng list comprehension, như trong Ví dụ 2-14.
Ví dụ 2-14: Một danh sách với ba danh sách, mỗi danh sách có độ dài 3, có thể biểu diễn một bàn cờ tic-tac-toe.
>>> board = [['_'] * 3 for i in range(3)] # Tạo một danh sách gồm ba danh sách, mỗi danh sách có ba mục.
>>> board
[['_', '_', '_'], ['_', '_', '_'], ['_', '_', '_']]
>>> board[1][2] = 'X' # Đặt một dấu vào hàng 1, cột 2, và kiểm tra kết quả.
>>> board
[['_', '_', '_'], ['_', '_', 'X'], ['_', '_', '_']]
Một cách viết tắt hấp dẫn, nhưng sai, là làm như Ví dụ 2-15.
Ví dụ 2-15: Một danh sách với ba tham chiếu đến cùng một danh sách là vô ích.
>>> weird_board = [['_'] * 3] * 3
>>> weird_board
[['_', '_', '_'], ['_', '_', '_'], ['_', '_', '_']]
>>> weird_board[1][2] = 'O' # Đặt một dấu vào hàng 1, cột 2, cho thấy tất cả các hàng đều là các bí danh tham chiếu đến cùng một đối tượng.
>>> weird_board
[['_', '_', 'O'], ['_', '_', 'O'], ['_', '_', 'O']]
Vấn đề với Ví dụ 2-15 là, về bản chất, nó hoạt động giống như đoạn code này:
row = ['_'] * 3
board = []
for i in range(3):
board.append(row) # Cùng một hàng được thêm vào board ba lần.
Mặt khác, list comprehension từ Ví dụ 2-14 tương đương với đoạn code này:
>>> board = []
>>> for i in range(3):
... row = ['_'] * 3 # Mỗi lần lặp tạo một hàng mới và thêm nó vào board.
... board.append(row)
...
>>> board
[['_', '_', '_'], ['_', '_', '_'], ['_', '_', '_']]
>>> board[2][0] = 'X' # Chỉ hàng 2 được thay đổi, như mong đợi.
>>> board
[['_', '_', '_'], ['_', '_', '_'], ['X', '_', '_']]
Cho đến nay, chúng ta đã thảo luận về việc sử dụng các toán tử + và * đơn giản với chuỗi, nhưng cũng có các toán tử += và *=, tạo ra kết quả rất khác nhau, tùy thuộc vào tính chất mutable của chuỗi đích. Phần tiếp theo giải thích cách thức hoạt động của nó.
7.2. Augmented Assignment with Sequences
Các toán tử gán tăng cường += và *= hoạt động khá khác nhau, tùy thuộc vào toán hạng đầu tiên. Để đơn giản hóa cuộc thảo luận, chúng ta sẽ tập trung vào phép cộng tăng cường (+=) trước, nhưng các khái niệm này cũng áp dụng cho *= và các toán tử gán tăng cường khác.
Phương thức đặc biệt làm cho += hoạt động là __iadd__ (viết tắt của “in-place addition”). Tuy nhiên, nếu __iadd__ không được triển khai, Python sẽ chuyển sang gọi __add__. Hãy xem xét biểu thức đơn giản này:
>>> a += b
Nếu a triển khai __iadd__, phương thức đó sẽ được gọi. Trong trường hợp chuỗi có thể thay đổi (ví dụ: list, bytearray, array.array), a sẽ được thay đổi tại chỗ (tức là hiệu ứng sẽ tương tự như a.extend(b)). Tuy nhiên, khi a không triển khai __iadd__, biểu thức a += b có tác dụng giống như a = a + b: biểu thức a + b được đánh giá trước, tạo ra một đối tượng mới, sau đó được liên kết với a. Nói cách khác, identity của đối tượng được liên kết với a có thể thay đổi hoặc không, tùy thuộc vào sự khả dụng của __iadd__.
Nhìn chung, đối với các chuỗi có thể thay đổi (mutable sequences), có thể chắc chắn rằng __iadd__ được triển khai và += xảy ra tại chỗ. Đối với các chuỗi không thể thay đổi (immutable sequences), rõ ràng không có cách nào để điều đó xảy ra.
Những gì tôi vừa viết về += cũng áp dụng cho *=, được triển khai thông qua __imul__. Các phương thức đặc biệt __iadd__ và __imul__ được thảo luận trong Chương 16. Dưới đây là minh họa về *= với một chuỗi có thể thay đổi và sau đó là một chuỗi không thể thay đổi:
>>> l = [1, 2, 3]
>>> id(l) # ID của danh sách ban đầu
4311953800
>>> l *= 2
>>> l
[1, 2, 3, 1, 2, 3]
>>> id(l) # Sau khi nhân, danh sách vẫn là cùng một đối tượng, với các mục mới được nối thêm
4311953800
>>> t = (1, 2, 3)
>>> id(t) # ID của tuple ban đầu
4312681568
>>> t *= 2
>>> id(t) # Sau khi nhân, một tuple mới đã được tạo
4301348296
Việc nối chuỗi không thể thay đổi lặp đi lặp lại là không hiệu quả, bởi vì thay vì chỉ nối thêm các mục mới, trình thông dịch phải sao chép toàn bộ chuỗi đích để tạo một chuỗi mới với các mục mới được nối thêm.
Chúng ta đã thấy các trường hợp sử dụng phổ biến cho +=. Phần tiếp theo cho thấy một trường hợp đặc biệt thú vị làm nổi bật ý nghĩa thực sự của “immutable” trong ngữ cảnh của tuple.
7.3. A += Assignment Puzzler
Hãy thử trả lời mà không cần sử dụng console: kết quả của việc đánh giá hai biểu thức trong Ví dụ 2-16 là gì?
Ví dụ 2-16: Một câu đố
>>> t = (1, 2, [30, 40])
>>> t[2] += [50, 60]
Điều gì xảy ra tiếp theo? Chọn câu trả lời đúng nhất:
A. t trở thành (1, 2, [30, 40, 50, 60]).
B. TypeError được đưa ra với thông báo “‘tuple’ object does not support item assignment”.
C. Không có câu nào đúng.
D. Cả A và B.
Khi tôi nhìn thấy điều này, tôi khá chắc chắn rằng câu trả lời là B, nhưng thực ra là D, “Cả A và B”! Ví dụ 2-17 là đầu ra thực tế từ console Python 3.9.
Ví dụ 2-17: Kết quả bất ngờ: mục t[2] bị thay đổi và một ngoại lệ được đưa ra
>>> t = (1, 2, [30, 40])
>>> t[2] += [50, 60]
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'tuple' object does not support item assignment
>>> t
(1, 2, [30, 40, 50, 60])
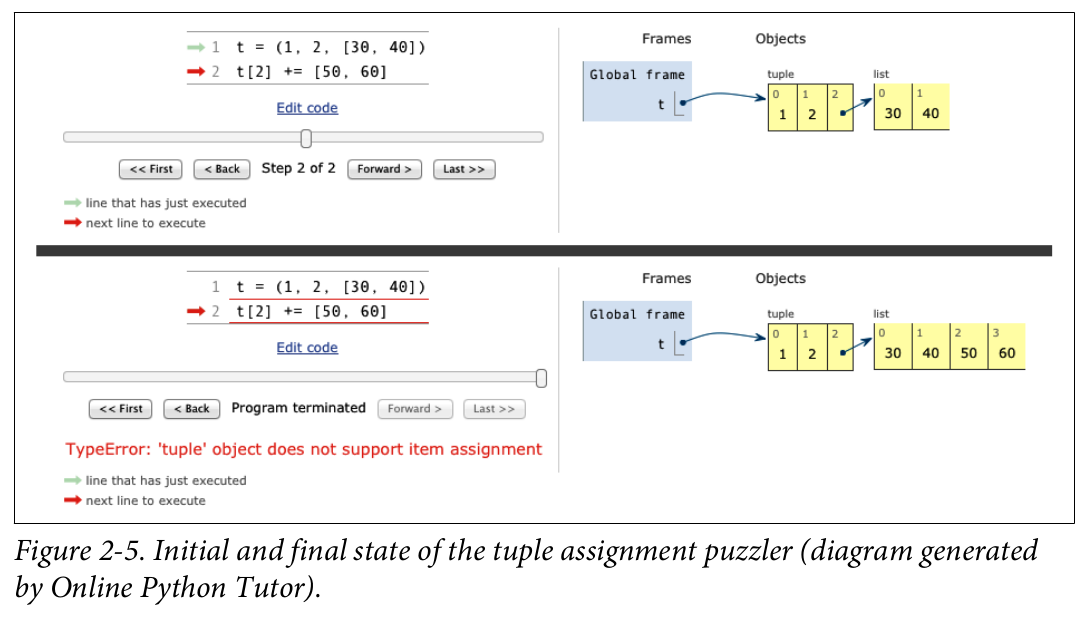
Online Python Tutor là một công cụ trực tuyến tuyệt vời để hình dung cách Python hoạt động chi tiết. Hình 2-5 là ảnh ghép của hai ảnh chụp màn hình hiển thị trạng thái ban đầu và cuối cùng của tuple t từ Ví dụ 2-17.
Giải thích:
Mặc dù tuple là immutable (không thể thay đổi), nhưng nó chứa một list (có thể thay đổi) ở phần tử thứ ba. Khi bạn thực hiện t[2] += [50, 60], nó tương đương với t[2] = t[2] + [50, 60].
Phép cộng t[2] + [50, 60] tạo ra một list mới là [30, 40, 50, 60].
Phần gán t[2] = ... cố gắng thay đổi phần tử thứ ba của tuple t. Vì tuple là immutable, nên việc gán này gây ra TypeError.
Tuy nhiên, trước khi ngoại lệ được đưa ra, list bên trong tuple đã được sửa đổi tại chỗ bởi toán tử +=. Đây là lý do tại sao list bên trong tuple vẫn thay đổi mặc dù có lỗi.
8. list.sort Versus the sorted Built-In
Phương thức list.sort sắp xếp một danh sách tại chỗ - tức là không tạo bản sao. Nó trả về None để nhắc nhở chúng ta rằng nó thay đổi đối tượng nhận (receiver) và không tạo ra một danh sách mới. Đây là một quy ước API quan trọng của Python: các hàm hoặc phương thức thay đổi một đối tượng tại chỗ nên trả về None để làm rõ cho người gọi rằng đối tượng nhận đã bị thay đổi và không có đối tượng mới nào được tạo. Hành vi tương tự có thể thấy, ví dụ, trong hàm random.shuffle(s), hàm này xáo trộn chuỗi s có thể thay đổi tại chỗ và trả về None.
Ngược lại, hàm sorted có sẵn tạo ra một danh sách mới và trả về nó. Nó chấp nhận bất kỳ đối tượng iterable nào làm đối số, bao gồm cả chuỗi không thể thay đổi và generator (xem Chương 17). Bất kể loại iterable nào được đưa cho sorted, nó luôn trả về một danh sách mới được tạo.
Cả list.sort và sorted đều nhận hai đối số tùy chọn, chỉ dành cho từ khóa:
reverse: Nếu làTrue, các mục được trả về theo thứ tự giảm dần (tức là bằng cách đảo ngược so sánh của các mục). Mặc định làFalse.key: Một hàm một đối số sẽ được áp dụng cho mỗi mục để tạo ra khóa sắp xếp của nó. Ví dụ: khi sắp xếp danh sách các chuỗi,key=str.lowercó thể được sử dụng để thực hiện sắp xếp không phân biệt chữ hoa chữ thường vàkey=lensẽ sắp xếp các chuỗi theo độ dài ký tự. Mặc định là hàm identity (tức là bản thân các mục được so sánh).
Dưới đây là một vài ví dụ để làm rõ cách sử dụng các hàm và đối số từ khóa này. Các ví dụ cũng chứng minh rằng thuật toán sắp xếp của Python là ổn định (tức là nó bảo toàn thứ tự tương đối của các mục so sánh bằng nhau):
>>> fruits = ['grape', 'raspberry', 'apple', 'banana']
>>> sorted(fruits) # Tạo ra một danh sách mới các chuỗi được sắp xếp theo thứ tự bảng chữ cái.
['apple', 'banana', 'grape', 'raspberry']
>>> fruits # Kiểm tra danh sách ban đầu, chúng ta thấy nó không thay đổi.
['grape', 'raspberry', 'apple', 'banana']
>>> sorted(fruits, reverse=True) # Đây là thứ tự "bảng chữ cái" trước đó, được đảo ngược.
['raspberry', 'grape', 'banana', 'apple']
>>> sorted(fruits, key=len) # Một danh sách mới các chuỗi, bây giờ được sắp xếp theo độ dài.
['grape', 'apple', 'banana', 'raspberry']
>>> sorted(fruits, key=len, reverse=True) # Đây là các chuỗi được sắp xếp theo độ dài theo thứ tự giảm dần.
['raspberry', 'banana', 'grape', 'apple']
>>> fruits # Cho đến nay, thứ tự của danh sách fruits ban đầu vẫn chưa thay đổi.
['grape', 'raspberry', 'apple', 'banana']
>>> fruits.sort() # Sắp xếp danh sách tại chỗ và trả về None (mà console bỏ qua).
>>> fruits # Bây giờ fruits đã được sắp xếp.
['apple', 'banana', 'grape', 'raspberry']
Khi chuỗi của bạn được sắp xếp, chúng có thể được tìm kiếm rất hiệu quả. Thuật toán tìm kiếm nhị phân đã được cung cấp trong module bisect của thư viện chuẩn Python. Module đó cũng bao gồm hàm bisect.insort, mà bạn có thể sử dụng để đảm bảo rằng các chuỗi được sắp xếp của bạn vẫn được sắp xếp. Bạn sẽ tìm thấy phần giới thiệu minh họa về module bisect trong bài đăng “Managing Ordered Sequences with Bisect” trên trang web fluentpython.com.
Phần lớn những gì chúng ta đã thấy cho đến nay trong chương này áp dụng cho chuỗi nói chung, không chỉ danh sách hoặc tuple. Các lập trình viên Python đôi khi lạm dụng kiểu danh sách vì nó rất tiện dụng - tôi biết tôi đã làm điều đó. Ví dụ: nếu bạn đang xử lý các danh sách số lớn, bạn nên cân nhắc sử dụng mảng thay thế. Phần còn lại của chương dành cho các lựa chọn thay thế cho danh sách và tuple.
9. When a List Is Not the Answer
Kiểu dữ liệu list rất linh hoạt và dễ sử dụng, nhưng tùy thuộc vào yêu cầu cụ thể, có những lựa chọn tốt hơn. Ví dụ, một array tiết kiệm rất nhiều bộ nhớ khi bạn cần xử lý hàng triệu giá trị số thực. Mặt khác, nếu bạn liên tục thêm và xóa các phần tử từ hai đầu đối diện của một list, thì nên biết rằng deque (hàng đợi hai đầu) là một cấu trúc dữ liệu FIFO14 hiệu quả hơn.
Trong phần còn lại của chương này, chúng ta sẽ thảo luận về các kiểu dữ liệu chuỗi có thể thay đổi (mutable sequence types) có thể thay thế list trong nhiều trường hợp, bắt đầu với array.
9.1. Array
Nếu một list chỉ chứa số, thì array.array là một sự thay thế hiệu quả hơn.
Array hỗ trợ tất cả các thao tác chuỗi có thể thay đổi (bao gồm .pop, .insert và .extend), cũng như các phương thức bổ sung để tải và lưu nhanh, chẳng hạn như .frombytes và .tofile.
Một array trong Python gọn nhẹ như một mảng C. Như được hiển thị trong Hình 2-1, một array các giá trị float không chứa các instance float đầy đủ, mà chỉ chứa các byte được đóng gói đại diện cho các giá trị máy của chúng — tương tự như một mảng double trong ngôn ngữ C. Khi tạo một array, bạn cung cấp một typecode, một chữ cái để xác định kiểu C cơ bản được sử dụng để lưu trữ mỗi phần tử trong array. Ví dụ: b là typecode cho cái mà C gọi là signed char, một số nguyên nằm trong khoảng từ –128 đến 127. Nếu bạn tạo array('b'), thì mỗi phần tử sẽ được lưu trữ trong một byte duy nhất và được hiểu là một số nguyên. Đối với các chuỗi số lớn, điều này giúp tiết kiệm rất nhiều bộ nhớ. Và Python sẽ không cho phép bạn đặt bất kỳ số nào không khớp với kiểu cho array.
Ví dụ 2-19 cho thấy việc tạo, lưu và tải một array gồm 10 triệu số thực ngẫu nhiên.
Ví dụ 2-19. Tạo, lưu và tải một array lớn các số float
>>> from array import array
>>> from random import random
>>> floats = array('d', (random() for i in range(10**7)))
>>> floats[-1]
0.07802343889111107
>>> fp = open('floats.bin', 'wb')
>>> floats.tofile(fp)
>>> fp.close()
>>> floats2 = array('d')
>>> fp = open('floats.bin', 'rb')
>>> floats2.fromfile(fp, 10**7)
>>> fp.close()
>>> floats2[-1]
0.07802343889111107
>>> floats2 == floats
True
- Import kiểu
array. - Tạo một
arraycác sốfloatcó độ chính xác kép (typecode‘d’) từ bất kỳ đối tượng iterable nào — trong trường hợp này, là một biểu thức generator. - Kiểm tra số cuối cùng trong
array. - Lưu
arrayvào một tệp nhị phân. - Tạo một
arraydoublerỗng. - Đọc 10 triệu số từ tệp nhị phân.
- Kiểm tra số cuối cùng trong
array. - Xác minh rằng nội dung của các
arraykhớp nhau.
Như bạn có thể thấy, array.tofile và array.fromfile rất dễ sử dụng. Nếu bạn thử ví dụ, bạn sẽ nhận thấy chúng cũng rất nhanh. Một thí nghiệm nhanh cho thấy array.fromfile mất khoảng 0,1 giây để tải 10 triệu số float có độ chính xác kép từ một tệp nhị phân được tạo bằng array.tofile. Điều đó nhanh hơn gần 60 lần so với việc đọc các số từ một tệp văn bản, cũng liên quan đến việc phân tích cú pháp từng dòng với hàm float tích hợp sẵn. Lưu bằng array.tofile nhanh hơn khoảng bảy lần so với việc ghi một số float trên mỗi dòng trong một tệp văn bản. Ngoài ra, kích thước của tệp nhị phân với 10 triệu số double là 80.000.000 byte (8 byte cho mỗi số double, không có overhead), trong khi tệp văn bản có 181.515.739 byte cho cùng một dữ liệu.
Đối với trường hợp cụ thể của các array số đại diện cho dữ liệu nhị phân, chẳng hạn như hình ảnh raster, Python có các kiểu bytes và bytearray được thảo luận trong Chương 4.
Chúng tôi kết thúc phần này về array với Bảng 2-3, so sánh các tính năng của list và array.array.
Nếu bạn làm việc nhiều với array và không biết về memoryview, bạn đang bỏ lỡ điều gì đó. Xem chủ đề tiếp theo.
9.2. Memory View
Lớp memoryview tích hợp sẵn là một kiểu chuỗi bộ nhớ dùng chung cho phép bạn xử lý các lát cắt của array mà không cần sao chép byte. Nó được lấy cảm hứng từ thư viện NumPy (mà chúng ta sẽ thảo luận ngay sau đây trong “NumPy” trên trang 64). Travis Oliphant, tác giả chính của NumPy, trả lời câu hỏi, “Khi nào nên sử dụng memoryview?” như thế này:
memoryviewvề cơ bản là một cấu trúcarrayNumPy tổng quát trong chính Python (không có toán học). Nó cho phép bạn chia sẻ bộ nhớ giữa các cấu trúc dữ liệu (những thứ như hình ảnh PIL, cơ sở dữ liệu SQLite,arrayNumPy, v.v.) mà không cần sao chép trước. Điều này rất quan trọng đối với các tập dữ liệu lớn.
Sử dụng ký hiệu tương tự như mô-đun array, phương thức memoryview.cast cho phép bạn thay đổi cách nhiều byte được đọc hoặc ghi dưới dạng các đơn vị mà không cần di chuyển các bit xung quanh. memoryview.cast trả về một đối tượng memoryview khác, luôn chia sẻ cùng một bộ nhớ.
Ví dụ 2-20 cho thấy cách tạo các chế độ xem thay thế trên cùng một array gồm 6 byte, để vận hành nó như một ma trận 2 × 3 hoặc ma trận 3 × 2.
Ví dụ 2-20. Xử lý 6 byte bộ nhớ dưới dạng chế độ xem 1 × 6, 2 × 3 và 3 × 2
>>> from array import array
>>> octets = array('B', range(6))
>>> m1 = memoryview(octets)
>>> m1.tolist()
[0, 1, 2, 3, 4, 5]
>>> m2 = m1.cast('B', [2, 3])
>>> m2.tolist()
[[0, 1, 2], [3, 4, 5]]
>>> m3 = m1.cast('B', [3, 2])
>>> m3.tolist()
[[0, 1], [2, 3], [4, 5]]
>>> m2[1,1] = 22
>>> m3[1,1] = 33
>>> octets
array('B', [0, 1, 2, 33, 22, 5])
- Xây dựng
arraygồm 6 byte (typecode‘B’). - Xây dựng
memoryviewtừarrayđó, sau đó xuất nó dưới dạng mộtlist. - Xây dựng
memoryviewmới từmemoryviewtrước đó, nhưng với 2 hàng và 3 cột. - Một
memoryviewkhác, bây giờ với 3 hàng và 2 cột. - Ghi đè byte trong
m2tại hàng 1, cột 1 với 22. - Ghi đè byte trong
m3tại hàng 1, cột 1 với 33. - Hiển thị
arrayban đầu, chứng minh rằng bộ nhớ được chia sẻ giữaoctets,m1,m2vàm3.
Sức mạnh tuyệt vời của memoryview cũng có thể được sử dụng để sửa đổi dữ liệu. Ví dụ 2-21 cho thấy cách thay đổi một byte duy nhất của một phần tử trong một array các số nguyên 16 bit.
Ví dụ 2-21. Thay đổi giá trị của một phần tử array số nguyên 16 bit bằng cách chọc một trong các byte của nó
>>> numbers = array('h', [-2, -1, 0, 1, 2])
>>> memv = memoryview(numbers)
>>> len(memv)
5
>>> memv[0]
-2
>>> memv_oct = memv.cast('B')
>>> memv_oct.tolist()
[254, 255, 255, 255, 0, 0, 1, 0, 2, 0]
>>> memv_oct[5] = 4
>>> numbers
array('h', [-2, -1, 1024, 1, 2])
- Xây dựng
memoryviewtừarraygồm 5 số nguyên có dấu 16 bit (typecode‘h’). memvnhìn thấy 5 phần tử giống nhau trongarray.- Tạo
memv_octbằng cách ép kiểu các phần tử củamemvthành byte (typecode‘B’). - Xuất các phần tử của
memv_octdưới dạng mộtlistgồm 10 byte, để kiểm tra. - Gán giá trị 4 cho byte offset 5.
- Lưu ý sự thay đổi đối với
numbers: số 4 trong byte có trọng số cao nhất của số nguyên không dấu 2 byte là 1024.
Trong khi đó, nếu bạn đang thực hiện xử lý số nâng cao trong array, bạn nên sử dụng các thư viện NumPy. Chúng ta sẽ xem xét ngắn gọn về chúng ngay bây giờ.
9.3. NumPy
Trong suốt cuốn sách này, tôi nhấn mạnh những gì đã có trong thư viện chuẩn của Python để bạn có thể tận dụng tối đa nó. Nhưng NumPy quá tuyệt vời đến nỗi một lối đi vòng là điều cần thiết.
Đối với các phép toán array và ma trận nâng cao, NumPy là lý do tại sao Python trở thành xu hướng chủ đạo trong các ứng dụng tính toán khoa học. NumPy triển khai các kiểu array đồng nhất, nhiều chiều và ma trận không chỉ chứa số mà còn cả các bản ghi do người dùng định nghĩa, đồng thời cung cấp các phép toán trên từng phần tử hiệu quả.
SciPy là một thư viện, được viết trên nền tảng NumPy, cung cấp nhiều thuật toán tính toán khoa học từ đại số tuyến tính, giải tích số và thống kê. SciPy nhanh chóng và đáng tin cậy vì nó tận dụng cơ sở mã C và Fortran được sử dụng rộng rãi từ Netlib Repository. Nói cách khác, SciPy mang đến cho các nhà khoa học những điều tốt nhất của cả hai thế giới: một trình thông dịch tương tác và các API Python cấp cao, cùng với các hàm xử lý số mạnh mẽ được tối ưu hóa trong C và Fortran.
Là một bản demo NumPy rất ngắn gọn, Ví dụ 2-22 cho thấy một số phép toán cơ bản với array hai chiều.
Ví dụ 2-22. Các phép toán cơ bản với các hàng và cột trong numpy.ndarray
>>> import numpy as np
>>> a = np.arange(12)
>>> a
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
>>> type(a)
<class 'numpy.ndarray'>
>>> a.shape
(12,)
>>> a.shape = 3, 4
>>> a
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>> a[2]
array([ 8, 9, 10, 11])
>>> a[2, 1]
9
>>> a[:, 1]
array([1, 5, 9])
>>> a.transpose()
array([[ 0, 4, 8],
[ 1, 5, 9],
[ 2, 6, 10],
[ 3, 7, 11]])
- Import NumPy, sau khi cài đặt (nó không có trong thư viện chuẩn của Python). Theo quy ước,
numpyđược import với tênnp. - Xây dựng và kiểm tra một
numpy.ndarrayvới các số nguyên từ 0 đến 11. - Kiểm tra kích thước của
array: đây làarraymột chiều, 12 phần tử. - Thay đổi hình dạng của
array, thêm một chiều, sau đó kiểm tra kết quả. - Lấy hàng tại chỉ mục 2.
- Lấy phần tử tại chỉ mục 2, 1.
- Lấy cột tại chỉ mục 1.
- Tạo một
arraymới bằng cách chuyển vị (hoán đổi cột với hàng).
NumPy cũng hỗ trợ các phép toán cấp cao để tải, lưu và vận hành trên tất cả các phần tử của numpy.ndarray:
>>> import numpy
>>> floats = numpy.loadtxt('floats-10M-lines.txt')
>>> floats[-3:]
array([ 3016362.69195522, 535281.10514262, 4566560.44373946])
>>> floats *= .5
>>> floats[-3:]
array([ 1508181.34597761, 267640.55257131, 2283280.22186973])
>>> from time import perf_counter as pc
>>> t0 = pc(); floats /= 3; pc() - t0
0.03690556302899495
>>> numpy.save('floats-10M', floats)
>>> floats2 = numpy.load('floats-10M.npy', 'r+')
>>> floats2 *= 6
>>> floats2[-3:]
memmap([ 3016362.69195522, 535281.10514262, 4566560.44373946])
- Tải 10 triệu số dấu phẩy động từ một tệp văn bản.
- Sử dụng ký hiệu cắt lát chuỗi để kiểm tra ba số cuối cùng.
- Nhân mọi phần tử trong
arrayfloatsvới .5 và kiểm tra lại ba phần tử cuối cùng. - Import bộ đếm thời gian hiệu suất có độ phân giải cao (có sẵn từ Python 3.3).
- Chia mọi phần tử cho 3; thời gian trôi qua cho 10 triệu số
floatnhỏ hơn 40 mili giây. - Lưu
arraytrong tệp nhị phân .npy. - Tải dữ liệu dưới dạng tệp ánh xạ bộ nhớ vào một
arraykhác; điều này cho phép xử lý hiệu quả các lát cắt củaarrayngay cả khi nó không vừa hoàn toàn trong bộ nhớ. - Kiểm tra ba phần tử cuối cùng sau khi nhân mọi phần tử với 6.
Đây chỉ là một món khai vị.
NumPy và SciPy là những thư viện đáng gờm và là nền tảng của các công cụ tuyệt vời khác như Pandas — triển khai các kiểu array hiệu quả có thể chứa dữ liệu phi số và cung cấp các hàm import/export cho nhiều định dạng khác nhau, như .csv, .xls, SQL dumps, HDF5, v.v. — và scikit-learn, hiện là bộ công cụ Machine Learning được sử dụng rộng rãi nhất. Hầu hết các hàm NumPy và SciPy được triển khai bằng C hoặc C ++ và có thể tận dụng tất cả các lõi CPU vì chúng giải phóng GIL (Global Interpreter Lock) của Python. Dự án Dask hỗ trợ song song hóa xử lý NumPy, Pandas và scikit-learn trên các cụm máy. Các gói này xứng đáng có toàn bộ sách viết về chúng. Đây không phải là một trong những cuốn sách đó. Nhưng không có cái nhìn tổng quan nào về các chuỗi Python sẽ hoàn chỉnh nếu không có ít nhất một cái nhìn nhanh về array NumPy.
Sau khi xem xét các chuỗi phẳng — array chuẩn và array NumPy — bây giờ chúng ta chuyển sang một tập hợp hoàn toàn khác để thay thế cho list cũ đơn giản: hàng đợi.
9.4. Deques và các hàng đợi khác
Các phương thức .append và .pop làm cho một list có thể sử dụng như một stack hoặc queue (nếu bạn sử dụng .append và .pop(0), bạn sẽ có được hành vi FIFO). Nhưng việc chèn và xóa khỏi đầu của một list (phần cuối có chỉ số 0) rất tốn kém vì toàn bộ list phải được dịch chuyển trong bộ nhớ.
Lớp collections.deque là một hàng đợi hai đầu an toàn cho luồng, được thiết kế để chèn và xóa nhanh chóng từ cả hai đầu. Đây cũng là cách nên làm nếu bạn cần giữ một list các “mục được nhìn thấy lần cuối” hoặc thứ gì đó tương tự, bởi vì deque có thể bị giới hạn — tức là được tạo với độ dài tối đa cố định. Nếu một deque bị giới hạn đã đầy, khi bạn thêm một mục mới, nó sẽ loại bỏ một mục khỏi đầu đối diện. Ví dụ 2-23 cho thấy một số thao tác điển hình được thực hiện trên deque.
Ví dụ 2-23. Làm việc với deque
>>> from collections import deque
>>> dq = deque(range(10), maxlen=10)
>>> dq
deque([0, 1, 2, 3, 4, 5, 6, 7, 8, 9], maxlen=10)
>>> dq.rotate(3)
>>> dq
deque([7, 8, 9, 0, 1, 2, 3, 4, 5, 6], maxlen=10)
>>> dq.rotate(-4)
>>> dq
deque([1, 2, 3, 4, 5, 6, 7, 8, 9, 0], maxlen=10)
>>> dq.appendleft(-1)
>>> dq
deque([-1, 1, 2, 3, 4, 5, 6, 7, 8, 9], maxlen=10)
>>> dq.extend([11, 22, 33])
>>> dq
deque([3, 4, 5, 6, 7, 8, 9, 11, 22, 33], maxlen=10)
>>> dq.extendleft([10, 20, 30, 40])
>>> dq
deque([40, 30, 20, 10, 3, 4, 5, 6, 7, 8], maxlen=10)
- Đối số
maxlentùy chọn đặt số lượng mục tối đa được phép trong instancedequenày; điều này đặt một thuộc tính instancemaxlenchỉ đọc. - Xoay với
n> 0lấy các mục từ đầu bên phải và thêm chúng vào bên trái; khin <0các mục được lấy từ bên trái và được nối vào bên phải. - Nối vào
dequeđã đầy (len(d) == d.maxlen) sẽ loại bỏ các mục khỏi đầu kia; lưu ý trong dòng tiếp theo rằng số 0 bị loại bỏ. - Thêm ba mục vào bên phải sẽ đẩy ra ba mục ngoài cùng bên trái là -1, 1 và 2.
- Lưu ý rằng
extendleft(iter)hoạt động bằng cách nối thêm từng mục kế tiếp của đối sốitervào bên trái củadeque, do đó vị trí cuối cùng của các mục bị đảo ngược.
Bảng 2-4 so sánh các phương thức dành riêng cho list và deque (loại bỏ những phương thức cũng xuất hiện trong object).
Lưu ý rằng deque triển khai hầu hết các phương thức list và thêm một số phương thức dành riêng cho thiết kế của nó, như popleft và rotate. Nhưng có một chi phí ẩn: việc xóa các mục khỏi giữa deque không nhanh. Nó thực sự được tối ưu hóa để nối thêm và bật ra khỏi hai đầu.
Các thao tác append và popleft là nguyên tử, vì vậy deque an toàn để sử dụng làm hàng đợi FIFO trong các ứng dụng đa luồng mà không cần khóa.
Bên cạnh deque, các gói thư viện chuẩn khác của Python triển khai hàng đợi:
queue: Cung cấp các lớp được đồng bộ hóa (tức là an toàn cho luồng)SimpleQueue,Queue,LifoQueuevàPriorityQueue. Chúng có thể được sử dụng để giao tiếp an toàn giữa các luồng. Tất cả ngoại trừSimpleQueuecó thể bị giới hạn bằng cách cung cấp đối sốmaxsizelớn hơn 0 cho hàm tạo. Tuy nhiên, chúng không loại bỏ các mục để nhường chỗ nhưdeque. Thay vào đó, khi hàng đợi đã đầy, việc chèn một mục mới sẽ bị chặn — tức là nó đợi cho đến khi một số luồng khác nhường chỗ bằng cách lấy một mục khỏi hàng đợi, điều này hữu ích để điều chỉnh số lượng luồng đang hoạt động.multiprocessing: Triển khaiSimpleQueuekhông giới hạn vàQueuegiới hạn của riêng nó, rất giống với các lớp trong góiqueue, nhưng được thiết kế để giao tiếp giữa các tiến trình.multiprocessing.JoinableQueuechuyên biệt được cung cấp để quản lý tác vụ.asyncio: Cung cấpQueue,LifoQueue,PriorityQueuevàJoinableQueuevới các API lấy cảm hứng từ các lớp trong mô-đunqueuevàmultiprocessing, nhưng được điều chỉnh để quản lý các tác vụ trong lập trình không đồng bộ.heapq: Trái ngược với ba mô-đun trước đó,heapqkhông triển khai lớpqueue, nhưng cung cấp các hàm nhưheappushvàheappopcho phép bạn sử dụng một chuỗi có thể thay đổi làm hàng đợi heap hoặc hàng đợi ưu tiên.