Building LLMs for Production
Cuốn sách này mang đến một cách tiếp cận độc đáo, thực hành và thực tế, đồng thời cân bằng giữa lý thuyết và khái niệm. Sách giới thiệu các xu hướng mới nhất trong xử lý ngôn ngữ tự nhiên (Natural Language Processing - NLP), chủ yếu là các mô hình ngôn ngữ lớn (Large Language Models - LLMs), cung cấp cái nhìn sâu sắc về cách các mạng này hoạt động. Ngoài ra, sách còn bao gồm các dự án minh họa ứng dụng của các mô hình này trong việc tạo ra các pipeline sinh dữ liệu tăng cường truy xuất (Retrieval-Augmented Generation - RAG). Những khái niệm này đại diện cho những phát triển tiên tiến trong lĩnh vực, cho phép chúng ta xử lý văn bản viết và tương tác với nó ở cấp độ ngữ cảnh.
Giống như hầu hết các cuốn sách liên quan đến LLMs, chúng ta bắt đầu với nền tảng bằng cách khám phá chi tiết kiến trúc transformer để hiểu cách các mô hình này được đào tạo và cách tương tác với chúng bằng kỹ thuật prompting. Sau đó, chúng ta đi sâu vào các phần tập trung vào ngành, đầu tiên là bao gồm hai frameworks nổi tiếng có thể được sử dụng để tận dụng các mô hình này để tạo ra các ứng dụng hỗ trợ RAG (LlamaIndex và LangChain). Điều này bao gồm nhiều dự án cung cấp trải nghiệm thực hành, giúp hiểu sâu sắc và áp dụng các khái niệm này. Chúng ta cũng khám phá các kỹ thuật nâng cao, chẳng hạn như sử dụng các autonomous agents hoặc kết hợp khả năng thị giác để nâng cao khả năng trả lời câu hỏi. Cuối cùng, chúng ta khám phá các tùy chọn triển khai để lưu trữ ứng dụng và các mẹo để làm cho quá trình hiệu quả hơn.
Cuốn sách này được thiết kế cho những độc giả không có kiến thức trước về trí tuệ nhân tạo hoặc NLP. Sách giới thiệu các chủ đề từ cơ bản, nhằm giúp bạn cảm thấy thoải mái khi sử dụng sức mạnh của AI trong dự án tiếp theo hoặc nâng dự án hiện tại của bạn lên một tầm cao mới. Hiểu biết cơ bản về Python giúp hiểu mã và các triển khai, trong khi các trường hợp sử dụng nâng cao của các kỹ thuật mã hóa được giải thích chi tiết trong sách. Mỗi chương của cuốn sách giới thiệu một chủ đề mới, tiếp theo là một dự án thực tế và triển khai đi kèm (dưới dạng Google Colab Notebooks) để chạy mã và tái tạo kết quả. Cách tiếp cận thực hành này giúp hiểu các khái niệm và áp dụng chúng một cách hiệu quả. Đây là tổng quan ngắn gọn về những gì mong đợi trong mỗi chương:
Chương I: Giới thiệu về LLMs
Bước đầu tiên để tận dụng AI cho dự án của bạn là hiểu những gì đang diễn ra bên trong. Mặc dù bạn có thể không cần tạo mô hình của riêng mình từ đầu và có thể sử dụng các API độc quyền (như OpenAI), nhưng việc hiểu các khái niệm như Scaling Laws, Context Windows, Emergent Abilities giải thích tại sao LLMs lại mạnh mẽ đến vậy. Chương đầu tiên tập trung vào thuật ngữ cơ bản của LLM, điều này rất quan trọng để hiểu phần còn lại của cuốn sách một cách hiệu quả. Ngoài ra, chúng tôi cung cấp các ví dụ đơn giản về việc sử dụng LLMs cho các tác vụ như dịch thuật hoặc xác định các mẫu từ dữ liệu, cho phép bạn tổng quát hóa cho các tác vụ mới và chưa từng thấy.
Chương II: Kiến trúc LLM và Bối cảnh
Chương này sẽ khám phá các kiến trúc mô hình khác nhau và các lựa chọn thiết kế của chúng cho các tác vụ khác nhau, tập trung vào kiến trúc transformer và các thành phần của nó ở mỗi lớp, cũng như họ mô hình GPT, cung cấp sức mạnh cho các sản phẩm như ChatGPT. Chúng tôi đề cập đến các mục tiêu đào tạo của các mô hình này, giới thiệu một loạt các mô hình, thảo luận về tính hữu ích của chúng, khám phá các ứng dụng thực tế của chúng và minh họa cách chúng cung cấp sức mạnh cho các ngành công nghiệp khác nhau.
Đây thường là nơi các trường học kết thúc, và cuốn sách thực sự bắt đầu!
Chương III: LLMs trong Thực tiễn
Trong thực tế, LLMs vẫn có những hạn chế. Vượt qua những hạn chế này để làm cho chúng sẵn sàng cho sản xuất là lý do tại sao chúng tôi quyết định viết cuốn sách này. Chương này khám phá một số vấn đề đã biết với họ mô hình này, chẳng hạn như ảo giác (hallucination), nơi mô hình tạo ra các phản hồi sai lệch về mặt thực tế với độ tin cậy cao hoặc thiên vị đối với giới tính hoặc chủng tộc. Sách nhấn mạnh tầm quan trọng của việc tận dụng các frameworks đánh giá để đánh giá phản hồi và thử nghiệm với các siêu tham số khác nhau để kiểm soát đầu ra của mô hình, chẳng hạn như các kỹ thuật giải mã khác nhau hoặc điều chỉnh độ sáng tạo của mô hình thông qua tham số nhiệt độ (temperature).
Chương IV: Giới thiệu về Prompting
Một cuốn sách về LLMs phải bao gồm một chương về prompting: cách chúng ta nói chuyện với chúng. Cách tốt nhất để tương tác với instruction-tuned LLMs (các mô hình được đào tạo để trả lời câu hỏi) là trực tiếp đặt câu hỏi hoặc nêu những gì bạn muốn mô hình làm. Quá trình này, được gọi là prompting, đã phát triển thành một thực hành tinh vi. Trong chương này, chúng tôi kiểm tra các kỹ thuật prompting khác nhau với các ví dụ mã. Chúng tôi đề cập đến các phương pháp như học ít lần (few-shot learning), nơi bạn cung cấp một vài ví dụ cho mô hình, chain prompting, hữu ích khi gán danh tính cho mô hình, và hơn thế nữa.
Chương V: Giới thiệu về LangChain & LlamaIndex
Có hai frameworks chính được sử dụng rộng rãi giúp đơn giản hóa việc làm việc với LLMs để giảm ảo giác và thiên vị hoặc dễ dàng triển khai chúng trong quy trình của bạn: các gói LangChain và LlamaIndex. Chương này tập trung vào ý tưởng sử dụng các tài nguyên bên ngoài để nâng cao phản hồi của mô hình, tiếp theo là triển khai các dự án khác nhau, chẳng hạn như một công cụ tóm tắt tin tức cạo một trang web để truy xuất nội dung để tóm tắt. Mục tiêu là học các kiến thức cơ bản của cả hai frameworks và hiểu khi nào chúng hữu ích.
Chương VI: Prompting với LangChain
LangChain cung cấp nhiều giao diện cho các kỹ thuật prompting khác nhau, điều này làm cho quá trình trực quan hơn. Chúng tôi giải thích việc sử dụng các loại prompt khác nhau để đặt các quy tắc cơ bản cho mô hình (hệ thống), tương tác của con người và phản hồi của chatbot để theo dõi các tương tác (tất cả đều có ví dụ thực tế). Ngoài ra, chương này nhấn mạnh tầm quan trọng của việc có một cơ chế kiểm soát để quản lý phản hồi của mô hình. Chúng tôi cũng thảo luận về cách thư viện này cung cấp các cách để nhận phản hồi ở các định dạng cụ thể, chẳng hạn như danh sách Python hoặc CSV, và thậm chí cung cấp các giải pháp để khắc phục sự cố định dạng nếu chúng phát sinh.
Chương VII: Sinh dữ liệu tăng cường truy xuất (Retrieval-Augmented Generation - RAG)
Sau khi hiểu các trường hợp sử dụng cơ bản của thư viện LangChain để triển khai một pipeline đơn giản, chương này khám phá chi tiết quá trình và hoạt động bên trong của nó. Chúng tôi tập trung vào việc tạo chỉ mục, các phương pháp khác nhau để tải dữ liệu từ nhiều nguồn dữ liệu khác nhau và chia các phần thông tin lớn thành các phần nhỏ hơn. Chúng tôi cũng khám phá cách lưu trữ thông tin này trong cơ sở dữ liệu để truy cập dễ dàng và nhanh hơn. Chương này cũng bao gồm hai dự án thú vị: phiên âm video YouTube và tóm tắt các điểm chính.
Chương VIII: RAG Nâng cao
Chương này giới thiệu các kỹ thuật nâng cao hơn để cải thiện bất kỳ pipeline RAG nào. Chúng tôi tập trung vào thư viện LlamaIndex, thư viện liên tục triển khai các giải pháp mới, chẳng hạn như mở rộng truy vấn, truy xuất đệ quy và tìm kiếm kết hợp. Chương này tập trung vào các thách thức tiềm ẩn, kỹ thuật tối ưu hóa và quy trình đánh giá hiệu suất chatbot của bạn. Sách cũng đề cập đến dịch vụ LangSmith, cung cấp một trung tâm để giải quyết các vấn đề khác nhau và một cách để chia sẻ các triển khai của bạn với những người khác trong cộng đồng.
Chương IX: Agents
Chương này giới thiệu khái niệm về các intelligent agents, có thể tương tác với môi trường bên ngoài. Chúng có thể truy cập dữ liệu từ nhiều tài nguyên khác nhau, gọi API và sử dụng các công cụ như chạy hàm để hoàn thành một tác vụ thành công mà không cần giám sát. Các agents này thường tạo một kế hoạch hành động dựa trên thông số kỹ thuật của người dùng và làm theo từng bước. Chúng tôi bao gồm một số dự án để minh họa cách các công cụ có thể nâng cao pipeline của bạn.
Introduction
Cuốn sách này sẽ tập trung vào essential tech stack được xác định để điều chỉnh một large language model (LLM) cho một specific use case và đạt được ngưỡng đủ về độ chính xác và độ tin cậy để sử dụng có thể mở rộng bởi khách hàng trả phí. Cụ thể, nó sẽ đề cập đến Prompt Engineering, Fine-tuning, và Retrieval-Augmented Generation (RAG).
Việc xây dựng các ứng dụng và sản phẩm sẵn sàng sản xuất của riêng bạn bằng cách sử dụng các mô hình này vẫn đòi hỏi một nỗ lực phát triển đáng kể. Do đó, cuốn sách này yêu cầu kiến thức trung cấp về Python. Mặc dù không cần kiến thức lập trình để khám phá các khái niệm cụ thể về AI và LLM trong cuốn sách này, chúng tôi khuyên bạn nên sử dụng danh sách các tài nguyên Python hữu ích và miễn phí để có trải nghiệm học tập thực hành hơn.
Chúng tôi hiện đang làm việc trên một khóa học về Python cho LLMs. Trong thời gian chờ đợi, một vài chương đầu tiên của cuốn sách này vẫn sẽ nhẹ nhàng và dễ hiểu. Song song đó, chúng tôi khuyên bạn nên xem qua Python và các tài nguyên khác mà chúng tôi có để phát triển các kỹ năng và hiểu biết kỹ thuật về AI của bạn. Việc xem qua một hoặc hai tài nguyên Python được liệt kê tại towardsai.net/book là đủ để bạn chuẩn bị cho cuốn sách này. Khi bạn tự tin hơn về kỹ năng lập trình của mình, hãy quay lại các phần tập trung vào code.
Bất chấp những nỗ lực đáng kể của các phòng thí nghiệm AI trung tâm và các nhà phát triển mã nguồn mở trong các lĩnh vực như Reinforcement Learning with Human Feedback để điều chỉnh các foundation models theo yêu cầu và use cases của con người, các off-the-shelf foundation models vẫn có những hạn chế hạn chế việc sử dụng trực tiếp của chúng trong sản xuất, ngoại trừ các tác vụ đơn giản nhất.
Có nhiều cách để điều chỉnh một off-the-shelf “foundation model” LLM cho một ứng dụng và use case cụ thể. Quyết định ban đầu là có nên sử dụng LLM qua API hay một nền tảng linh hoạt hơn, nơi bạn có toàn quyền truy cập vào model weights. Một số người cũng có thể muốn thử nghiệm đào tạo các mô hình của riêng họ; tuy nhiên, theo ý kiến của chúng tôi, điều này hiếm khi thực tế hoặc kinh tế bên ngoài các phòng thí nghiệm AI và công ty công nghệ hàng đầu. Hiện có hơn 5 triệu người đang xây dựng trên LLMs trên các nền tảng như OpenAI, Anthropic, Nvidia và Hugging Face. Cuốn sách này hướng dẫn bạn vượt qua những hạn chế của LLM và phát triển các sản phẩm LLM sẵn sàng sản xuất với các key tech stacks!
“Off-the-shelf “foundation model” LLM” đề cập đến một mô hình ngôn ngữ lớn (LLM) được đào tạo trước (pre-trained) và sẵn sàng sử dụng ngay lập tức, mà không cần phải xây dựng từ đầu.
Why Prompt Engineering, Fine-Tuning, and RAG?
Các LLM (Large Language Models) như GPT-4 thường thiếu kiến thức domain-specific, gây khó khăn trong việc tạo ra các phản hồi chính xác hoặc phù hợp trong các lĩnh vực chuyên môn. Chúng cũng gặp khó khăn khi xử lý khối lượng dữ liệu lớn, hạn chế tính hữu dụng trong các kịch bản data-intensive. Một hạn chế quan trọng khác là khó khăn trong việc xử lý các thuật ngữ mới hoặc technical, dẫn đến hiểu nhầm hoặc thông tin sai lệch. Hallucinations, khi LLM tạo ra thông tin sai lệch hoặc gây hiểu nhầm, càng làm phức tạp việc sử dụng chúng. Hallucinations là kết quả trực tiếp của mục tiêu huấn luyện mô hình là next token prediction - ở một mức độ nào đó, chúng là một feature cho phép các câu trả lời “creative” của mô hình. Tuy nhiên, LLM khó biết được khi nào nó đang trả lời từ các facts đã ghi nhớ và trí tưởng tượng. Điều này tạo ra nhiều errors trong các workflows được hỗ trợ bởi LLM, khiến chúng khó xác định. Bên cạnh hallucinations, LLM đôi khi cũng đơn giản là không sử dụng dữ liệu có sẵn một cách hiệu quả, dẫn đến các phản hồi không liên quan hoặc không chính xác.
LLM thường được sử dụng trong production cho các use cases “copilot” nhằm nâng cao hiệu suất và năng suất, với con người vẫn hoàn toàn tham gia vào vòng lặp thay vì cho các nhiệm vụ hoàn toàn tự động do những hạn chế này. Nhưng có một hành trình dài từ một basic LLM prompt đến độ chính xác, độ tin cậy và observability đủ cho một target copilot use case. Hành trình này được gọi là “march of 9s” và được phổ biến trong phát triển xe tự lái. Thuật ngữ này mô tả sự cải thiện dần dần về độ tin cậy, thường được đo bằng số lượng nines (ví dụ: độ tin cậy 99,9%) cần thiết để cuối cùng đạt được hiệu suất ngang con người.
Chúng tôi cho rằng bộ công cụ phát triển chính cho “march of 9s” đối với các sản phẩm dựa trên LLM là
- 1) Prompt Engineering,
- 2) Retrieval-Augmented Generation (RAG),
- 3) Fine-Tuning và
- 4) Custom UI/UX.
Trong thời gian ngắn, AI có thể hỗ trợ nhiều nhiệm vụ của con người trong nhiều ngành khác nhau bằng cách kết hợp LLM, prompting, RAG và fine-tuning workflows. Chúng tôi tin rằng các công ty “AI” thành công nhất sẽ tập trung vào các giải pháp được tùy chỉnh cao cho các ngành hoặc niches cụ thể và đóng góp nhiều dữ liệu và intelligence/experience dành riêng cho ngành vào cách sản phẩm được phát triển.
RAG bao gồm việc tăng cường LLM bằng dữ liệu cụ thể và yêu cầu mô hình sử dụng và trích dẫn dữ liệu này trong câu trả lời của nó thay vì dựa vào những gì nó có thể hoặc không thể ghi nhớ trong model weights. Chúng tôi thích RAG vì nó giúp:
- 1) Giảm hallucinations bằng cách giới hạn LLM trả lời dựa trên dữ liệu đã chọn hiện có.
- 2) Giúp explainability, error checking và các vấn đề về copyright bằng cách tham khảo rõ ràng các nguồn của nó cho mỗi nhận xét.
- 3) Cung cấp dữ liệu private/specific hoặc cập nhật hơn cho LLM.
- 4) Không dựa quá nhiều vào black box LLM training/fine-tuning cho những gì các mô hình biết và đã ghi nhớ.
Một cách khác để tăng hiệu suất LLM là thông qua good prompting. Nhiều kỹ thuật đã được tìm thấy để cải thiện hiệu suất mô hình. Các phương pháp này có thể đơn giản, chẳng hạn như đưa ra hướng dẫn chi tiết cho mô hình hoặc chia nhỏ các nhiệm vụ lớn thành các nhiệm vụ nhỏ hơn để mô hình dễ xử lý hơn. Một số kỹ thuật prompting là:
- 1) “Chain of Thought” prompting bao gồm việc yêu cầu mô hình suy nghĩ từng bước về một vấn đề trước khi đưa ra câu trả lời cuối cùng. Ý tưởng chính là mỗi token trong một language model có “processing bandwidth” hoặc “thinking capacity” hạn chế. LLM cần các token này để tìm ra mọi thứ. Bằng cách yêu cầu nó suy luận từng bước về một vấn đề, chúng ta sử dụng tổng capacity của mô hình để suy nghĩ và giúp nó đạt được câu trả lời chính xác.
- 2) “Few-Shot Prompting” là khi chúng ta cho mô hình xem các ví dụ về câu trả lời mà chúng ta tìm kiếm dựa trên một số câu hỏi tương tự như những câu hỏi mà chúng ta mong đợi mô hình nhận được. Nó giống như việc cho mô hình thấy một pattern về cách chúng ta muốn nó phản hồi.
- 3) “Self-Consistency” bao gồm việc hỏi cùng một câu hỏi cho nhiều phiên bản của mô hình và sau đó chọn câu trả lời xuất hiện thường xuyên nhất. Phương pháp này giúp có được câu trả lời đáng tin cậy hơn.
Nói tóm lại, good prompting là hướng dẫn mô hình bằng các hướng dẫn rõ ràng, chia nhỏ các nhiệm vụ thành các nhiệm vụ đơn giản hơn và sử dụng các phương pháp cụ thể để cải thiện hiệu suất. Về cơ bản, đó là các bước tương tự mà chúng ta phải làm khi bắt đầu các bài tập mới. Giáo sư giả định bạn biết các concepts và yêu cầu bạn áp dụng chúng một cách thông minh.
Mặt khác, fine-tuning giống như việc cho language model các bài học bổ sung để cải thiện đầu ra cho các nhiệm vụ cụ thể. Ví dụ: nếu bạn muốn mô hình biến các câu thông thường thành truy vấn cơ sở dữ liệu SQL, bạn có thể huấn luyện nó cụ thể cho nhiệm vụ đó. Hoặc, nếu bạn cần mô hình phản hồi bằng câu trả lời ở định dạng JSON—một loại dữ liệu có cấu trúc được sử dụng trong lập trình—bạn có thể fine-tune nó. Quá trình này cũng có thể giúp mô hình học các thông tin cụ thể về một lĩnh vực hoặc chủ đề nhất định. Tuy nhiên, nếu bạn muốn thêm kiến thức chuyên môn một cách nhanh chóng và hiệu quả hơn, Retrieval-Augmented Generation (RAG) thường là bước đầu tiên tốt hơn. Với RAG, bạn có nhiều quyền kiểm soát hơn đối với thông tin mà mô hình sử dụng để tạo phản hồi, giúp giai đoạn thử nghiệm nhanh hơn, minh bạch hơn và dễ quản lý hơn.
Các phần của bộ công cụ này sẽ được tích hợp một phần vào thế hệ foundation models tiếp theo, trong khi các phần sẽ được giải quyết thông qua các frameworks bổ sung như LlamaIndex và LangChain, đặc biệt là cho các RAG workflows. Tuy nhiên, các giải pháp tốt nhất sẽ cần điều chỉnh các công cụ này cho các ngành và ứng dụng cụ thể. Chúng tôi cũng tin rằng prompting, cùng với RAG, sẽ tồn tại lâu dài - theo thời gian, prompting sẽ giống như các kỹ năng cần thiết để giao tiếp và ủy quyền hiệu quả cho đồng nghiệp con người. Mặc dù nó sẽ tồn tại lâu dài, nhưng các libraries liên tục phát triển. Chúng tôi đã liên kết đến tài liệu của cả LlamaIndex và LangChain trên towardsai.net/book để có thông tin cập nhật nhất.
Tiềm năng của thế hệ AI models này vượt ra ngoài các nhiệm vụ xử lý ngôn ngữ tự nhiên (NLP) thông thường. Có vô số use cases, chẳng hạn như giải thích các algorithms phức tạp, xây dựng bots, hỗ trợ phát triển ứng dụng và giải thích các concepts học thuật. Các chương trình text-to-image như DALL-E, Stable Diffusion và Midjourney đang cách mạng hóa các lĩnh vực như hoạt hình, trò chơi, nghệ thuật, phim ảnh và kiến trúc. Ngoài ra, generative AI models đã thể hiện khả năng biến đổi trong phát triển phần mềm phức tạp với các công cụ như GitHub Copilot.
The Current LLM Landscape
Tình hình LLM hiện tại
Những đột phá trong lĩnh vực Generative AI đã tạo ra một bối cảnh cực kỳ năng động và sôi động với nhiều bên tham gia. Điều này bao gồm:
- 1) các nhà sản xuất phần cứng AI như Nvidia,
- 2) các nền tảng đám mây AI như Azure, AWS và Google,
- 3) các nền tảng mã nguồn mở để truy cập các mô hình đầy đủ, chẳng hạn như Hugging Face,
- 4) truy cập vào các mô hình LLM thông qua API như OpenAI, Cohere và Anthropic, và
- 5) truy cập vào LLM thông qua các sản phẩm tiêu dùng như ChatGPT, Perplexity và Bing.
Ngoài ra, nhiều đột phá khác đang diễn ra hàng tuần trong vũ trụ AI, chẳng hạn như việc phát hành các mô hình multimodal (có thể hiểu cả văn bản và hình ảnh), các kiến trúc mô hình mới (như Mixture of Experts), Agent Models (các mô hình có thể đặt nhiệm vụ và tương tác với nhau và các công cụ khác), v.v.
Coding Environment and Packages
Môi trường lập trình và các Packages
Tất cả các code notebooks, Google Colabs, GitHub repos, research papers, documentation và các tài nguyên khác đều có thể truy cập tại towardsai.net/book.
Để theo dõi các phần coding của cuốn sách này, bạn cần đảm bảo rằng bạn đã chuẩn bị sẵn sàng môi trường lập trình phù hợp. Hãy đảm bảo sử dụng phiên bản Python bằng hoặc mới hơn 3.8.1. Bạn có thể thiết lập môi trường của mình bằng cách chọn một trong các tùy chọn sau:
- Có một code editor được cài đặt trên máy tính của bạn. Một môi trường lập trình phổ biến là Visual Studio Code, sử dụng Python virtual environments để quản lý các Python libraries.
- Sử dụng các Google Colab notebooks của chúng tôi.
Run the code locally
Nếu bạn chọn tùy chọn đầu tiên, bạn sẽ cần các packages sau để thực thi thành công các sample codes trong mỗi phần. Bạn cũng sẽ cần một environment đã được thiết lập.
Python virtual environments cung cấp một giải pháp tuyệt vời để quản lý các Python libraries và tránh xung đột package. Chúng tạo ra các môi trường biệt lập để cài đặt packages, đảm bảo rằng các packages của bạn và các dependencies của chúng được chứa trong môi trường đó. Thiết lập này cung cấp các môi trường sạch và biệt lập cho các Python projects của bạn.
Thực thi lệnh python trong terminal của bạn để xác nhận rằng phiên bản Python bằng hoặc lớn hơn 3.8.1. Sau đó, hãy làm theo các bước sau để tạo một virtual environment:
- Tạo một virtual environment bằng lệnh:
python -m venv my_venv_name - Kích hoạt virtual environment:
source my_venv_name/bin/activate - Cài đặt các required libraries và chạy các code snippets từ các bài học trong virtual environment.
Chúng có thể được cài đặt bằng trình quản lý pip packages. Một liên kết đến tệp văn bản requirements này có thể truy cập tại towardsai.net/book.
deeplake==3.6.19
openai==0.27.8
tiktoken==0.4.0
transformers==4.32.0
torch==2.0.1
numpy==1.23.5
deepspeed==0.10.1
trl==0.7.1
peft==0.5.0
wandb==0.15.8
bitsandbytes==0.41.1
accelerate==0.22.0
tqdm==4.66.1
neural_compressor===2.2.1
onnx===1.14.1
pandas==2.0.3
scipy==1.11.2
Mặc dù chúng tôi đặc biệt khuyên bạn nên cài đặt các phiên bản mới nhất của các packages này, nhưng xin lưu ý rằng các mã đã được kiểm tra với các phiên bản được chỉ định trong dấu ngoặc đơn. Hơn nữa, các bài học cụ thể có thể yêu cầu cài đặt các packages bổ sung, sẽ được đề cập rõ ràng. Mã sau đây sẽ minh họa cách cài đặt một package bằng pip:
pip install deeplake
# Hoặc: (để cài đặt một phiên bản cụ thể)
# pip install deeplake==3.6.5
Google Colab
Google Colaboratory, thường được gọi là Google Colab, là một môi trường Jupyter notebook dựa trên đám mây miễn phí. Các Data scientists và engineers sử dụng rộng rãi nó để huấn luyện các mô hình machine learning và deep learning bằng CPU, GPU và TPU. Google Colab đi kèm với một loạt các tính năng, chẳng hạn như:
- Miễn phí truy cập vào GPU và TPU để huấn luyện mô hình được tăng tốc.
- Giao diện dựa trên web cho một dịch vụ chạy trên máy ảo, loại bỏ nhu cầu cài đặt phần mềm cục bộ.
- Tích hợp liền mạch với Google Drive và GitHub.
Bạn chỉ cần một tài khoản Google để sử dụng Google Colab. Bạn có thể chạy các terminal commands trực tiếp trong các notebook cells bằng cách thêm dấu chấm than (!) trước lệnh. Mọi notebook được tạo trong Google Colab đều được lưu trữ trong Google Drive của bạn để dễ dàng truy cập.
Một cách thuận tiện để sử dụng API keys trong Colab bao gồm:
-
Lưu các API keys trong một tệp có tên .env trên Google Drive của bạn. Đây là cách tệp nên được định dạng để lưu Activeloop token và OpenAI API key:
OPENAI_API_KEY=your_openai_key - Mount Google Drive của bạn trên Colab instance.
-
Load chúng làm environment variables bằng thư viện dotenv:
from dotenv import load_dotenv load_dotenv('/content/drive/MyDrive/path/to/.env')
Learning Resources
Để hỗ trợ quá trình học tập của bạn, chúng tôi chia sẻ chatbot AI Tutor mã nguồn mở của mình (aitutor.towardsai.net) để hỗ trợ bạn khi cần thiết. Công cụ này được tạo ra bằng các công cụ chúng tôi dạy trong cuốn sách này. Chúng tôi xây dựng một hệ thống RAG (Retrieval-Augmented Generation) cung cấp cho LLM quyền truy cập vào tài liệu mới nhất từ tất cả các công cụ quan trọng, chẳng hạn như LangChain và LlamaIndex, bao gồm cả các khóa học miễn phí trước đây của chúng tôi. Nếu bạn có bất kỳ câu hỏi nào hoặc cần trợ giúp trong hành trình học AI của mình, cho dù là người mới bắt đầu hay chuyên gia trong lĩnh vực này, bạn có thể liên hệ với các thành viên cộng đồng của chúng tôi và các tác giả của cuốn sách này trong kênh (space) dành riêng cho cuốn sách này trong Cộng đồng Discord Learn AI Together của chúng tôi: discord.gg/learnaitogether.
Chapter I: Introduction to LLMs
What are Large Language Models
Đến thời điểm này, bạn có thể đã nghe nói về chúng. Large Language Models, thường được gọi là LLMs, là một loại neural network phức tạp. Các mô hình này đã khơi dậy nhiều đổi mới trong lĩnh vực xử lý ngôn ngữ tự nhiên (NLP) và được đặc trưng bởi số lượng lớn parameters, thường lên đến hàng tỷ, giúp chúng thành thạo trong việc xử lý và tạo văn bản. Chúng được huấn luyện trên dữ liệu văn bản rộng lớn, cho phép chúng nắm bắt các patterns và cấu trúc ngôn ngữ đa dạng. Mục tiêu chính của LLMs là diễn giải và tạo ra văn bản giống con người, nắm bắt được các sắc thái của ngôn ngữ tự nhiên, bao gồm syntax (cách sắp xếp từ) và semantics (ý nghĩa của từ).
Mục tiêu huấn luyện cốt lõi của LLMs tập trung vào việc dự đoán từ tiếp theo trong một câu. Mục tiêu đơn giản này dẫn đến sự phát triển của các khả năng mới nổi (emergent abilities). Ví dụ, chúng có thể thực hiện các phép tính số học, giải mã từ và thậm chí đã thể hiện sự thành thạo trong các kỳ thi chuyên nghiệp, chẳng hạn như vượt qua Kỳ thi Cấp phép Y tế Hoa Kỳ (US Medical Licensing Exam). Ngoài ra, các mô hình này đã đóng góp đáng kể vào nhiều nhiệm vụ NLP khác nhau, bao gồm machine translation, natural language generation, part-of-speech tagging, parsing, information retrieval và những nhiệm vụ khác, ngay cả khi không được huấn luyện trực tiếp hoặc fine-tuning trong các lĩnh vực cụ thể này.
Quá trình tạo văn bản trong Large Language Models là autoregressive, nghĩa là chúng tạo ra các tokens tiếp theo dựa trên chuỗi tokens đã được tạo ra. Attention mechanism là một thành phần quan trọng trong quá trình này; nó thiết lập các kết nối từ và đảm bảo văn bản mạch lạc và phù hợp với ngữ cảnh. Điều cần thiết là phải thiết lập các terminology và concepts cơ bản liên quan đến Large Language Models trước khi khám phá kiến trúc và các building blocks của nó (như attention mechanisms) một cách sâu sắc hơn. Hãy bắt đầu với tổng quan về kiến trúc cung cấp sức mạnh cho các mô hình này, tiếp theo là định nghĩa một vài terms, chẳng hạn như language modeling và tokenization.
Key LLM Terminologies
Transformer
Nền tảng của một mô hình ngôn ngữ mạnh mẽ nằm ở kiến trúc của nó. Các Mạng Nơ-ron Tái phát (Recurrent Neural Networks - RNNs) thường được sử dụng cho xử lý văn bản do khả năng xử lý dữ liệu tuần tự. Chúng duy trì một trạng thái nội tại (internal state) lưu giữ thông tin từ các từ trước đó, tạo điều kiện cho sự hiểu biết tuần tự. Tuy nhiên, RNNs gặp phải những thách thức với các chuỗi dài, nơi chúng quên thông tin cũ để ưu tiên đầu vào được xử lý gần đây. Điều này chủ yếu là do vấn đề gradient biến mất (vanishing gradient problem), một hiện tượng mà các gradient, được sử dụng để cập nhật trọng số của mạng trong quá trình huấn luyện, trở nên nhỏ dần khi chúng được lan truyền ngược qua mỗi bước thời gian của chuỗi. Kết quả là, các trọng số liên quan đến đầu vào ban đầu thay đổi rất ít, cản trở khả năng học hỏi và ghi nhớ các phụ thuộc dài hạn trong dữ liệu của mạng.
Các mô hình dựa trên Transformer đã giải quyết những thách thức này và nổi lên như kiến trúc ưa thích cho các nhiệm vụ xử lý ngôn ngữ tự nhiên. Kiến trúc này, được giới thiệu trong bài báo có ảnh hưởng “Attention Is All You Need”, là một đổi mới then chốt trong xử lý ngôn ngữ tự nhiên. Nó tạo thành nền tảng cho các mô hình tiên tiến như GPT-4, Claude và LLaMA. Kiến trúc này ban đầu được thiết kế như một khung encoder-decoder. Thiết lập này sử dụng một encoder để xử lý văn bản đầu vào, xác định các phần quan trọng và tạo ra một biểu diễn của đầu vào. Trong khi đó, decoder có khả năng biến đổi đầu ra của encoder, một vector có chiều cao, trở lại văn bản có thể đọc được cho con người. Các mạng này có thể hữu ích trong các nhiệm vụ như tóm tắt, nơi decoder tạo ra các bản tóm tắt có điều kiện dựa trên các bài báo được truyền cho encoder. Nó cung cấp sự linh hoạt bổ sung trên một loạt các nhiệm vụ vì các thành phần của kiến trúc này, encoder và decoder, có thể được sử dụng cùng nhau hoặc riêng biệt. Một số mô hình sử dụng phần encoder của mạng để biến đổi văn bản thành biểu diễn vector hoặc chỉ sử dụng khối decoder, là xương sống của các Mô hình Ngôn ngữ Lớn (Large Language Models - LLMs). Chương tiếp theo sẽ bao gồm từng thành phần này.
Mô hình hóa Ngôn ngữ (Language Modeling)
Với sự trỗi dậy của LLMs, mô hình hóa ngôn ngữ đã trở thành một phần thiết yếu của xử lý ngôn ngữ tự nhiên (natural language processing). Nó có nghĩa là học phân phối xác suất (probability distribution) của các từ trong một ngôn ngữ dựa trên một ngữ liệu lớn (large corpus). Quá trình học này thường liên quan đến việc dự đoán token tiếp theo trong một chuỗi bằng cách sử dụng các phương pháp thống kê cổ điển hoặc các kỹ thuật học sâu (deep learning) mới.
Các mô hình ngôn ngữ lớn được huấn luyện dựa trên cùng một mục tiêu là dự đoán từ, dấu chấm câu hoặc các thành phần khác tiếp theo dựa trên các token đã thấy trong một văn bản. Các mô hình này trở nên thành thạo bằng cách hiểu phân phối của các từ trong dữ liệu huấn luyện của chúng bằng cách đoán xác suất của từ tiếp theo dựa trên ngữ cảnh. Ví dụ: mô hình có thể hoàn thành một câu bắt đầu bằng “Tôi sống ở New” với một từ như “York” thay vì một từ không liên quan như “giày”.
Trong thực tế, các mô hình làm việc với token, không phải từ hoàn chỉnh. Cách tiếp cận này cho phép dự đoán và tạo văn bản chính xác hơn bằng cách nắm bắt hiệu quả hơn sự phức tạp của ngôn ngữ con người.
Tokenization (Phân tách Token)
Tokenization là giai đoạn đầu tiên của việc tương tác với LLMs. Nó liên quan đến việc chia văn bản đầu vào thành các phần nhỏ hơn được gọi là token. Token có thể từ các ký tự đơn lẻ đến toàn bộ từ và kích thước của các token này có thể ảnh hưởng lớn đến hiệu suất của mô hình. Một số mô hình áp dụng subword tokenization, chia các từ thành các đoạn nhỏ hơn giữ lại các yếu tố ngôn ngữ có ý nghĩa.
Hãy xem xét câu sau: “The child’s coloring book.”
Nếu tokenization chia văn bản sau mỗi ký tự khoảng trắng. Kết quả sẽ là:
[“The”, “child’s”, “coloring”, “book.”]
Trong cách tiếp cận này, bạn sẽ nhận thấy rằng dấu chấm câu vẫn được gắn vào các từ như “child’s” và “book.”
Ngoài ra, tokenization có thể được thực hiện bằng cách tách văn bản dựa trên cả khoảng trắng và dấu chấm câu; đầu ra sẽ là:
[“The”, “child”, “’”, “s”, “coloring”, “book”, “.”]
Quá trình tokenization phụ thuộc vào mô hình. Điều quan trọng cần nhớ là các mô hình được phát hành dưới dạng một cặp pre-trained tokenizers và trọng số mô hình liên quan. Có những kỹ thuật tiên tiến hơn, như Byte-Pair encoding, được sử dụng bởi hầu hết các mô hình được phát hành gần đây. Như được minh họa trong ví dụ dưới đây, phương pháp này cũng chia một từ như “coloring” thành hai phần.
[“The”, “child”, “’”, “s”, “color”, “ing”, “book”, “.”]
Subword tokenization tăng cường hơn nữa khả năng hiểu ngôn ngữ của mô hình bằng cách chia các từ thành các đoạn có ý nghĩa, như chia “coloring” thành “color” và “ing.” Điều này mở rộng vốn từ vựng của mô hình và cải thiện khả năng nắm bắt các sắc thái của cấu trúc và hình thái ngôn ngữ. Hiểu rằng phần “ing” của một từ cho biết thì hiện tại cho phép chúng ta đơn giản hóa cách chúng ta biểu diễn các từ ở các thì khác nhau. Chúng ta không còn cần giữ các mục riêng biệt cho dạng cơ bản của một từ, như “play,” và dạng thì hiện tại của nó, “playing.” Bằng cách kết hợp “play” với “ing,” chúng ta có thể diễn đạt “playing” mà không cần hai mục riêng biệt. Phương pháp này làm tăng số lượng token để biểu diễn một đoạn văn bản nhưng giảm đáng kể số lượng token chúng ta cần có trong từ điển.
Quá trình tokenization bao gồm việc quét toàn bộ văn bản để xác định các token duy nhất, sau đó được lập chỉ mục để tạo từ điển. Từ điển này gán một ID token duy nhất cho mỗi token, cho phép biểu diễn số hóa tiêu chuẩn của văn bản. Khi tương tác với các mô hình, việc chuyển đổi văn bản thành ID token này cho phép mô hình xử lý và hiểu đầu vào một cách hiệu quả, vì nó có thể nhanh chóng tham chiếu từ điển để giải mã ý nghĩa của mỗi token. Chúng ta sẽ thấy một ví dụ về quá trình này sau trong cuốn sách.
Sau khi có token, chúng ta có thể xử lý các hoạt động bên trong của transformers: embeddings.
Embeddings (Nhúng)
Bước tiếp theo sau tokenization là biến các token này thành thứ mà máy tính có thể hiểu và làm việc được — đó là lúc embeddings xuất hiện. Embeddings là một cách để dịch các token, là các từ hoặc các phần của từ, thành một ngôn ngữ số mà máy tính có thể nắm bắt. Chúng giúp mô hình hiểu các mối quan hệ và ngữ cảnh. Chúng cho phép mô hình nhìn thấy các kết nối giữa các từ và sử dụng các kết nối này để hiểu văn bản tốt hơn, chủ yếu thông qua quá trình attention, như chúng ta sẽ thấy.
Một embedding cung cấp cho mỗi token một ID số duy nhất nắm bắt ý nghĩa của nó. Dạng số này giúp máy tính thấy hai token giống nhau như thế nào, giống như biết rằng “happy” và “joyful” gần nhau về ý nghĩa, mặc dù chúng là những từ khác nhau.
Bước này rất cần thiết vì nó giúp mô hình hiểu ngôn ngữ theo cách số hóa, thu hẹp khoảng cách giữa ngôn ngữ con người và xử lý máy móc.
Ban đầu, mỗi token được gán một tập hợp số ngẫu nhiên làm embedding của nó. Khi mô hình được huấn luyện—nghĩa là khi nó đọc và học từ rất nhiều văn bản—nó điều chỉnh các số này. Mục tiêu là tinh chỉnh chúng sao cho các token có ý nghĩa tương tự kết thúc bằng các tập hợp số tương tự. Sự điều chỉnh này được thực hiện tự động bởi mô hình khi nó học từ các ngữ cảnh khác nhau mà các token xuất hiện.
Mặc dù khái niệm về các tập hợp số, hoặc vectors, có vẻ phức tạp, nhưng chúng chỉ là một cách để mô hình lưu trữ và xử lý thông tin về các token một cách hiệu quả. Chúng ta sử dụng vectors vì chúng là một phương pháp đơn giản để mô hình theo dõi các token liên quan đến nhau như thế nào. Về cơ bản, chúng chỉ là các danh sách số lớn.
Trong Chương 2, chúng ta sẽ khám phá thêm về cách các embeddings này được tạo và sử dụng trong kiến trúc transformer.
Huấn luyện/Tinh chỉnh (Training/Fine-Tuning)
LLMs được huấn luyện trên một ngữ liệu văn bản lớn (large corpus of text) với mục tiêu dự đoán chính xác token tiếp theo của một chuỗi. Như chúng ta đã học trong phần mô hình hóa ngôn ngữ (language modeling) trước đó, mục tiêu là điều chỉnh các tham số (parameters) của mô hình để tối đa hóa xác suất dự đoán chính xác dựa trên dữ liệu quan sát được. Thông thường, một mô hình được huấn luyện trên một tập dữ liệu mục đích chung (general-purpose dataset) khổng lồ gồm các văn bản từ Internet, chẳng hạn như The Pile hoặc CommonCrawl. Đôi khi, các tập dữ liệu cụ thể hơn, chẳng hạn như tập dữ liệu StackOverflow Posts, cũng là một ví dụ về việc thu thập kiến thức chuyên ngành (domain-specific knowledge). Giai đoạn này còn được gọi là giai đoạn tiền huấn luyện (pre-training stage), cho thấy rằng mô hình được huấn luyện để học khả năng hiểu ngôn ngữ và được chuẩn bị cho việc tinh chỉnh thêm.
Quá trình huấn luyện điều chỉnh trọng số (weights) của mô hình để tăng khả năng dự đoán token tiếp theo trong một chuỗi. Sự điều chỉnh này dựa trên dữ liệu huấn luyện, hướng dẫn mô hình đến các dự đoán token chính xác.
Sau khi tiền huấn luyện, mô hình thường trải qua quá trình tinh chỉnh (fine-tuning) cho một nhiệm vụ cụ thể. Giai đoạn này yêu cầu huấn luyện thêm trên một tập dữ liệu nhỏ hơn cho một nhiệm vụ (ví dụ: dịch văn bản) hoặc một lĩnh vực chuyên ngành (ví dụ: y sinh, tài chính, v.v.). Tinh chỉnh cho phép mô hình điều chỉnh kiến thức trước đó về nhiệm vụ hoặc lĩnh vực cụ thể, nâng cao hiệu suất của nó.
Quá trình tinh chỉnh có thể phức tạp, đặc biệt đối với các mô hình tiên tiến như GPT-4. Các mô hình này sử dụng các kỹ thuật tiên tiến và tận dụng khối lượng dữ liệu lớn để đạt được mức hiệu suất của chúng.
Dự đoán (Prediction)
Sau giai đoạn huấn luyện hoặc tinh chỉnh, mô hình có thể tạo ra văn bản bằng cách dự đoán các token tiếp theo trong một chuỗi. Điều này đạt được bằng cách đưa chuỗi vào mô hình, tạo ra một phân phối xác suất (probability distribution) trên các token tiếp theo tiềm năng, về cơ bản là gán điểm cho mọi từ trong từ vựng. Token tiếp theo được chọn theo điểm số của nó. Quá trình tạo sẽ được lặp lại trong một vòng lặp để dự đoán từng từ một, do đó có thể tạo ra các chuỗi có độ dài bất kỳ. Tuy nhiên, điều quan trọng là phải ghi nhớ kích thước ngữ cảnh hiệu quả (effective context size) của mô hình.
Kích thước Ngữ cảnh (Context Size)
Kích thước ngữ cảnh, hay cửa sổ ngữ cảnh (context window), là một khía cạnh quan trọng của LLMs. Nó đề cập đến số lượng token tối đa mà mô hình có thể xử lý trong một yêu cầu duy nhất. Kích thước ngữ cảnh ảnh hưởng đến độ dài văn bản mà mô hình có thể xử lý tại một thời điểm, ảnh hưởng trực tiếp đến hiệu suất của mô hình và kết quả mà nó tạo ra.
Các LLMs khác nhau được thiết kế với các kích thước ngữ cảnh khác nhau. Ví dụ, mô hình “gpt-3.5-turbo-16k” của OpenAI có cửa sổ ngữ cảnh có khả năng xử lý 16.000 token. Có một giới hạn vốn có đối với số lượng token mà một mô hình có thể tạo ra. Các mô hình nhỏ hơn có thể có dung lượng lên đến 1.000 token, trong khi các mô hình lớn hơn như GPT-4 có thể quản lý lên đến 32.000 token tại thời điểm chúng ta viết cuốn sách này.
Quy luật Tỷ lệ (Scaling Laws)
Quy luật tỷ lệ mô tả mối quan hệ giữa hiệu suất của mô hình ngôn ngữ và các yếu tố khác nhau, bao gồm số lượng tham số (parameters), kích thước tập dữ liệu huấn luyện (training dataset size), ngân sách tính toán (compute budget) và kiến trúc mạng (network architecture). Các quy luật này, được trình bày chi tiết trong bài báo Chinchilla, cung cấp những hiểu biết hữu ích về phân bổ tài nguyên để huấn luyện mô hình thành công. Chúng cũng là nguồn gốc của nhiều meme từ phía cộng đồng “scaling is all you need” trong lĩnh vực AI.
Các yếu tố sau đây xác định hiệu suất của mô hình ngôn ngữ:
- Số lượng tham số (N): Biểu thị khả năng học hỏi từ dữ liệu của mô hình. Số lượng tham số càng lớn, khả năng phát hiện các mẫu phức tạp trong dữ liệu càng cao.
- Kích thước của Tập dữ liệu Huấn luyện (D): Và số lượng token, từ các đoạn văn bản nhỏ đến các ký tự đơn lẻ, được tính.
- FLOPs (Số phép tính dấu phẩy động mỗi giây): Ước tính tài nguyên tính toán được sử dụng trong quá trình huấn luyện.
Trong nghiên cứu của mình, các tác giả đã huấn luyện mô hình Chinchilla, bao gồm 70 tỷ tham số, trên một tập dữ liệu gồm 1,4 nghìn tỷ token. Cách tiếp cận này phù hợp với quy luật tỷ lệ được đề xuất trong bài báo: đối với một mô hình có X tham số, việc huấn luyện tối ưu liên quan đến khoảng X * 20 token. Ví dụ, một mô hình có 100 tỷ tham số lý tưởng sẽ được huấn luyện trên khoảng 2 nghìn tỷ token.
Với cách tiếp cận này, mặc dù có kích thước nhỏ hơn so với các LLMs khác, mô hình Chinchilla đã vượt trội hơn tất cả. Nó đã cải thiện mô hình hóa ngôn ngữ và hiệu suất cụ thể của nhiệm vụ bằng cách sử dụng ít bộ nhớ và sức mạnh tính toán hơn. Tìm bài báo “Training Compute-Optimal Large Language Models” tại towardsai.net/book.
Khả năng Mới nổi trong LLMs (Emergent Abilities in LLMs)
Khả năng mới nổi trong LLMs mô tả hiện tượng mà các kỹ năng mới xuất hiện bất ngờ khi kích thước mô hình tăng lên. Các khả năng này, bao gồm số học, trả lời câu hỏi, tóm tắt tài liệu và những khả năng khác, không được dạy rõ ràng cho mô hình trong suốt quá trình huấn luyện của nó. Thay vào đó, chúng xuất hiện một cách tự phát khi tỷ lệ của mô hình tăng lên, do đó có từ “mới nổi”.
LLMs là các mô hình xác suất học các mẫu ngôn ngữ tự nhiên. Khi các mô hình này được mở rộng, khả năng nhận dạng mẫu của chúng được cải thiện về mặt định lượng đồng thời cũng thay đổi về mặt định tính.
Theo truyền thống, các mô hình yêu cầu tinh chỉnh cụ thể cho từng nhiệm vụ và điều chỉnh kiến trúc để thực hiện các nhiệm vụ cụ thể. Tuy nhiên, các mô hình được mở rộng có thể thực hiện các công việc này mà không cần thay đổi kiến trúc hoặc tinh chỉnh chuyên biệt. Chúng thực hiện điều này bằng cách diễn giải các nhiệm vụ bằng cách sử dụng xử lý ngôn ngữ tự nhiên. Khả năng thực hiện các chức năng khác nhau mà không cần tinh chỉnh rõ ràng của LLMs là một cột mốc quan trọng.
Điều đáng chú ý hơn là cách các khả năng này thể hiện bản thân. LLMs nhanh chóng và không thể đoán trước tiến triển từ gần bằng không đến đôi khi đạt hiệu suất tối ưu khi kích thước của chúng tăng lên. Hiện tượng này chỉ ra rằng các khả năng này phát sinh từ quy mô của mô hình chứ không phải được lập trình rõ ràng vào mô hình.
Sự tăng trưởng về kích thước mô hình và việc mở rộng tập dữ liệu huấn luyện, cùng với sự gia tăng đáng kể về chi phí tính toán, đã mở đường cho sự xuất hiện của các Mô hình Ngôn ngữ Lớn ngày nay. Ví dụ về các mô hình như vậy bao gồm Cohere Command, GPT-4 và LLaMA, mỗi mô hình đại diện cho những cột mốc quan trọng trong quá trình phát triển của mô hình hóa ngôn ngữ.
Prompts (Lời nhắc)
Văn bản (hoặc hình ảnh, số, bảng…) chúng ta cung cấp cho LLMs (Large Language Models - Mô hình ngôn ngữ lớn) như hướng dẫn thường được gọi là prompts. Prompts là các chỉ dẫn được đưa ra cho các hệ thống AI như GPT-3 và GPT-4 của OpenAI, cung cấp ngữ cảnh để tạo ra văn bản giống như con người—prompt càng chi tiết, đầu ra của mô hình càng tốt.
Concise (ngắn gọn), descriptive (mô tả) và short (ngắn) prompts (tùy thuộc vào nhiệm vụ) thường dẫn đến kết quả hiệu quả hơn, cho phép sự sáng tạo của LLM đồng thời hướng dẫn nó đến đầu ra mong muốn. Sử dụng các từ hoặc cụm từ cụ thể có thể giúp tập trung mô hình vào việc tạo ra nội dung liên quan. Việc tạo ra các prompts hiệu quả đòi hỏi mục đích rõ ràng, giữ mọi thứ đơn giản, sử dụng từ khóa một cách chiến lược và đảm bảo tính khả thi (actionability). Kiểm tra prompts trước khi sử dụng cuối cùng là rất quan trọng để đảm bảo đầu ra liên quan và không có lỗi. Dưới đây là một số mẹo về prompting:
- Use Precise Language (Sử dụng ngôn ngữ chính xác): Sự chính xác trong prompt của bạn có thể cải thiện đáng kể độ chính xác của đầu ra.
- Less Precise (Kém chính xác): “Write about dog food.” (Viết về thức ăn cho chó.)
- More Precise (Chính xác hơn): “Write a 500-word informative article about the dietary needs of adult Golden Retrievers.” (Viết một bài báo thông tin 500 từ về nhu cầu dinh dưỡng của chó Golden Retriever trưởng thành.)
- Provide Sufficient Context (Cung cấp đủ ngữ cảnh): Ngữ cảnh giúp mô hình hiểu đầu ra mong đợi:
- Less Contextual (Ít ngữ cảnh): “Write a story.” (Viết một câu chuyện.)
- More Contextual (Nhiều ngữ cảnh hơn): “Write a short story set in Victorian England featuring a young detective solving his first major case.” (Viết một truyện ngắn lấy bối cảnh nước Anh thời Victoria với một thám tử trẻ giải quyết vụ án lớn đầu tiên.)
- Test Variations (Kiểm tra các biến thể): Thử nghiệm với các kiểu prompt khác nhau để tìm ra cách tiếp cận hiệu quả nhất:
- Initial (Ban đầu): “Write a blog post about the benefits of yoga.” (Viết một bài đăng trên blog về lợi ích của yoga.)
- Variation 1 (Biến thể 1): “Compose a 1000-word blog post detailing the physical and mental benefits of regular yoga practice.” (Soạn một bài đăng trên blog dài 1000 từ chi tiết về lợi ích thể chất và tinh thần của việc tập yoga thường xuyên.)
- Variation 2 (Biến thể 2): “Create an engaging blog post that highlights the top 10 benefits of incorporating yoga into a daily routine.” (Tạo một bài đăng trên blog hấp dẫn làm nổi bật 10 lợi ích hàng đầu của việc kết hợp yoga vào thói quen hàng ngày.)
- Review Outputs (Xem xét đầu ra): Luôn kiểm tra kỹ đầu ra tự động về độ chính xác và mức độ liên quan trước khi xuất bản.
- Before Review (Trước khi xem xét): “Yoga is a great way to improve your flexibility and strength. It can also help reduce stress and improve mental clarity. However, it’s important to remember that all yoga poses are suitable for everyone.” (Yoga là một cách tuyệt vời để cải thiện sự linh hoạt và sức mạnh của bạn. Nó cũng có thể giúp giảm căng thẳng và cải thiện sự minh mẫn tinh thần. Tuy nhiên, điều quan trọng cần nhớ là không phải tất cả các tư thế yoga đều phù hợp với tất cả mọi người.)
- After Review (corrected) (Sau khi xem xét (đã sửa)): “Yoga is a great way to improve your flexibility and strength. It can also help reduce stress and improve mental clarity. However, it’s important to remember that not all yoga poses are suitable for everyone. Always consult with a healthcare professional before starting any new exercise regimen.” (Yoga là một cách tuyệt vời để cải thiện sự linh hoạt và sức mạnh của bạn. Nó cũng có thể giúp giảm căng thẳng và cải thiện sự minh mẫn tinh thần. Tuy nhiên, điều quan trọng cần nhớ là không phải tất cả các tư thế yoga đều phù hợp với tất cả mọi người. Luôn tham khảo ý kiến của chuyên gia chăm sóc sức khỏe trước khi bắt đầu bất kỳ chế độ tập luyện mới nào.)
Hallucinations (Ảo giác) và Biases (Thiên kiến) trong LLMs
Hallucinations trong các hệ thống AI đề cập đến các trường hợp mà các hệ thống này tạo ra đầu ra, chẳng hạn như văn bản hoặc hình ảnh, không nhất quán với sự thật hoặc các đầu vào có sẵn. Một ví dụ là nếu ChatGPT cung cấp một câu trả lời thuyết phục nhưng sai sự thật cho một câu hỏi. Những hallucinations này cho thấy sự không khớp giữa đầu ra của AI và kiến thức hoặc ngữ cảnh thế giới thực.
Trong LLMs, hallucinations xảy ra khi mô hình tạo ra đầu ra không tương ứng với sự thật hoặc ngữ cảnh thế giới thực. Điều này có thể dẫn đến việc lan truyền thông tin sai lệch, đặc biệt là trong các ngành quan trọng như chăm sóc sức khỏe và giáo dục, nơi độ chính xác của thông tin là rất quan trọng. Bias trong LLMs cũng có thể dẫn đến kết quả ưu tiên các quan điểm cụ thể hơn những quan điểm khác, có khả năng củng cố các định kiến và phân biệt đối xử có hại.
Một ví dụ về hallucination có thể là nếu người dùng hỏi, “Ai đã vô địch World Series năm 2025?” và LLM trả lời với một người chiến thắng cụ thể. Tính đến ngày hiện tại (tháng 1 năm 2024), sự kiện này vẫn chưa diễn ra, khiến mọi phản hồi đều mang tính suy đoán và không chính xác.
Ngoài ra, Bias trong AI và LLMs là một vấn đề quan trọng khác. Nó đề cập đến xu hướng của các mô hình này trong việc ưu tiên các đầu ra hoặc quyết định cụ thể dựa trên dữ liệu huấn luyện của chúng. Nếu dữ liệu huấn luyện chủ yếu xuất phát từ một khu vực cụ thể, mô hình có thể bị thiên vị đối với ngôn ngữ, văn hóa hoặc quan điểm của khu vực đó. Trong trường hợp dữ liệu huấn luyện bao gồm các biases, chẳng hạn như giới tính hoặc chủng tộc, đầu ra kết quả từ hệ thống AI có thể bị thiên vị hoặc phân biệt đối xử.
Ví dụ, nếu người dùng hỏi một LLM, “Ai là y tá?” và nó trả lời, “Cô ấy là một chuyên gia chăm sóc sức khỏe, người chăm sóc bệnh nhân trong bệnh viện,” điều này thể hiện một gender bias (thiên kiến giới tính). Mô hình này vốn liên kết nghề y tá với phụ nữ, điều này không phản ánh đầy đủ thực tế rằng cả nam và nữ đều có thể là y tá.
Việc giảm thiểu hallucinations và bias trong các hệ thống AI bao gồm việc tinh chỉnh quá trình huấn luyện mô hình, sử dụng các kỹ thuật xác minh và đảm bảo dữ liệu huấn luyện đa dạng và mang tính đại diện. Việc tìm kiếm sự cân bằng giữa việc tối đa hóa tiềm năng của mô hình và tránh những vấn đề này vẫn là một thách thức.
Đáng ngạc nhiên là, những “ hallucinations” này có thể có lợi trong các lĩnh vực sáng tạo như viết tiểu thuyết, cho phép tạo ra nội dung mới và độc đáo. Mục tiêu cuối cùng là tạo ra các LLMs mạnh mẽ, hiệu quả nhưng cũng đáng tin cậy, công bằng và đáng tin cậy. Chúng ta có thể tối đa hóa tiềm năng của LLMs đồng thời giảm thiểu rủi ro của chúng, đảm bảo rằng lợi ích của công nghệ này có sẵn cho tất cả mọi người.
Translation with LLMs (GPT-3.5 API) (Dịch thuật với LLMs (API GPT-3.5))
Giờ đây, chúng ta có thể kết hợp tất cả những gì đã học để minh họa cách tương tác với LLM độc quyền của OpenAI thông qua API của họ, hướng dẫn mô hình thực hiện dịch thuật. Để tạo văn bản bằng LLMs như những LLMs được cung cấp bởi OpenAI, trước tiên bạn cần một API key cho môi trường Python của mình. Dưới đây là hướng dẫn từng bước để tạo key này:
- Tạo và đăng nhập vào tài khoản OpenAI của bạn.
- Sau khi đăng nhập, hãy chọn ‘Personal’ từ menu trên cùng bên phải và nhấp vào “View API keys”.
- Bạn sẽ tìm thấy nút “Create new secret key” trên trang API keys. Nhấp vào nút đó để tạo một secret key mới. Hãy nhớ lưu trữ key này một cách an toàn, vì nó sẽ được sử dụng sau này.
- Sau khi tạo API key, bạn có thể lưu trữ nó một cách an toàn trong tệp .env bằng định dạng sau:
OPENAI_API_KEY="<YOUR-OPENAI-API-KEY>"Mỗi khi bạn khởi tạo một tập lệnh Python bao gồm các dòng sau, API key của bạn sẽ tự động được tải vào một biến môi trường có tên làOPENAI_API_KEY. Thư việnopenaisau đó sử dụng biến này cho các tác vụ tạo văn bản. Tệp .env phải nằm trong cùng thư mục với tập lệnh Python.
from dotenv import load_dotenv
load_dotenv()
Giờ đây, mô hình đã sẵn sàng để tương tác! Dưới đây là một ví dụ về việc sử dụng mô hình cho dịch thuật ngôn ngữ từ tiếng Anh sang tiếng Pháp. Đoạn mã bên dưới gửi prompt dưới dạng tin nhắn với vai trò người dùng, sử dụng gói Python OpenAI để gửi và truy xuất yêu cầu từ API. Bạn không cần lo lắng nếu bạn không hiểu tất cả các chi tiết, vì chúng ta sẽ sử dụng OpenAI API kỹ lưỡng hơn trong Chương 5. Tốt nhất bạn nên tập trung vào đối số messages ngay bây giờ, đối số này nhận prompt hướng dẫn mô hình thực hiện tác vụ dịch thuật.
from dotenv import load_dotenv
load_dotenv()
import os
import openai
# English text to translate
english_text = "Hello, how are you?"
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": f'''Translate the following English text to French: "{english_text}"'''}
],
)
print(response['choices'][0]['message']['content'])
Đầu ra:
Bonjour, comment ça va?
💡 Bạn có thể lưu trữ an toàn thông tin nhạy cảm, chẳng hạn như API keys, trong một tệp riêng biệt với dotenv và tránh vô tình tiết lộ nó trong mã của bạn. Điều này đặc biệt quan trọng khi làm việc với các dự án mã nguồn mở hoặc chia sẻ mã của bạn với người khác, vì nó đảm bảo tính bảo mật của thông tin nhạy cảm.
Kiểm soát đầu ra của LLMs bằng cách cung cấp các ví dụ
Few-shot learning, một trong những khả năng mới nổi của LLMs, có nghĩa là cung cấp cho mô hình một số lượng nhỏ các ví dụ trước khi đưa ra dự đoán. Những ví dụ này phục vụ mục đích kép: chúng “dạy” mô hình trong quá trình suy luận và hoạt động như “bộ lọc”, giúp mô hình xác định các mẫu liên quan trong tập dữ liệu của nó. Few-shot learning cho phép điều chỉnh mô hình cho các nhiệm vụ mới. Mặc dù LLMs như GPT-3 thể hiện sự thành thạo trong các nhiệm vụ mô hình hóa ngôn ngữ như dịch máy, hiệu suất của chúng có thể thay đổi đối với các nhiệm vụ đòi hỏi khả năng suy luận phức tạp hơn.
Trong few-shot learning, các ví dụ được trình bày cho mô hình giúp khám phá các mẫu liên quan trong tập dữ liệu. Các tập dữ liệu được mã hóa hiệu quả vào trọng số của mô hình trong quá trình đào tạo, vì vậy mô hình tìm kiếm các mẫu kết nối đáng kể với các mẫu được cung cấp và sử dụng chúng để tạo ra đầu ra của nó. Kết quả là, độ chính xác của mô hình được cải thiện bằng cách thêm nhiều ví dụ hơn, cho phép phản hồi có mục tiêu và phù hợp hơn.
Dưới đây là một ví dụ về few-shot learning, nơi chúng ta cung cấp các ví dụ thông qua các loại tin nhắn khác nhau về cách mô tả phim bằng biểu tượng cảm xúc cho mô hình. (Chúng ta sẽ đề cập đến các loại tin nhắn khác nhau sau trong cuốn sách.) Ví dụ: phim “Titanic” có thể được trình bày bằng cách sử dụng biểu tượng cảm xúc cho tàu du lịch, sóng, trái tim, v.v., hoặc cách biểu diễn phim “The Matrix”. Mô hình nắm bắt các mẫu này và quản lý để mô tả chính xác bộ phim “Toy Story” bằng cách sử dụng biểu tượng cảm xúc của đồ chơi.
from dotenv import load_dotenv
load_dotenv()
import os
import openai
# Prompt for summarization
prompt = """
Describe the following movie using emojis.
{movie}: """
examples = [
{ "input": "Titanic", "output": "🛳️🌊❤️🧊🎶🔥🚢💔👫💑" },
{ "input": "The Matrix", "output": "🕶️💊💥👾🔮🌃👨🏻💻🔁🔓💪" }
]
movie = "Toy Story"
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": prompt.format(movie=examples[0]["input"])},
{"role": "assistant", "content": examples[0]["output"]},
{"role": "user", "content": prompt.format(movie=examples[1]["input"])},
{"role": "assistant", "content": examples[1]["output"]},
{"role": "user", "content": prompt.format(movie=movie)},
]
)
print(response['choices'][0]['message']['content'])
🧸🤠👦🧒🎢🌈🌟👫🚁👽🐶🚀
Thật thú vị khi mô hình, chỉ với hai ví dụ, có thể xác định một mẫu phức tạp, chẳng hạn như liên kết tiêu đề phim với một chuỗi biểu tượng cảm xúc. Khả năng này chỉ có thể đạt được với một mô hình có sự hiểu biết sâu sắc về câu chuyện của bộ phim và ý nghĩa của các biểu tượng cảm xúc, cho phép nó hợp nhất cả hai và trả lời các câu hỏi dựa trên cách giải thích của riêng mình.
From Language Models to Large Language Models
Sự evolution (tiến hóa) của các language models (mô hình ngôn ngữ) đã chứng kiến một sự thay đổi mô hình từ các pre-trained language models (LMs) (mô hình ngôn ngữ được huấn luyện trước) đến việc tạo ra các Large Language Models (LLMs) (mô hình ngôn ngữ lớn). Các LMs, như ELMo và BERT, ban đầu nắm bắt các context-aware word representations (biểu diễn từ nhận biết ngữ cảnh) thông qua pre-training (huấn luyện trước) và fine-tuning (tinh chỉnh) cho các nhiệm vụ cụ thể. Tuy nhiên, sự ra đời của các LLMs, như được thể hiện bởi GPT-3 và PaLM, đã chứng minh rằng việc mở rộng quy mô mô hình và dữ liệu có thể mở khóa các kỹ năng mới nổi trội hơn so với các mô hình nhỏ hơn. Thông qua in-context learning (học trong ngữ cảnh), các LLMs này có thể xử lý các nhiệm vụ phức tạp hơn.
Emergent Abilities in LLMs
Khả năng Xuất hiện (Emergent Abilities) trong LLMs
Như chúng ta đã thảo luận, một khả năng được coi là emergent khi các mô hình lớn hơn thể hiện nó, nhưng nó lại vắng mặt ở các mô hình nhỏ hơn—một yếu tố quan trọng góp phần vào thành công của Large Language Models (LLMs). Emergent abilities trong Large Language Models (LLMs) là hiện tượng thực nghiệm xảy ra khi kích thước của các mô hình ngôn ngữ vượt quá các ngưỡng cụ thể. Khi chúng ta tăng kích thước của mô hình, emergent abilities trở nên rõ ràng hơn, bị ảnh hưởng bởi các khía cạnh như sức mạnh tính toán được sử dụng trong quá trình huấn luyện và các parameters của mô hình.
Emergent Abilities là gì?
Hiện tượng này chỉ ra rằng các mô hình đang học và tổng quát hóa vượt ra ngoài quá trình pre-training của chúng theo những cách không được lập trình hoặc dự đoán rõ ràng. Một mô hình riêng biệt xuất hiện khi những khả năng này được mô tả trên đường cong scaling. Ban đầu, hiệu suất của mô hình gần như ngẫu nhiên, nhưng nó cải thiện đáng kể khi đạt đến một ngưỡng quy mô nhất định. Hiện tượng này được gọi là phase transition, thể hiện sự thay đổi hành vi đáng kể mà không thể thấy rõ khi kiểm tra các hệ thống quy mô nhỏ hơn.
Việc scaling các mô hình ngôn ngữ chủ yếu tập trung vào việc tăng lượng tính toán, mở rộng các model parameters và tăng kích thước tập dữ liệu huấn luyện. Các khả năng mới đôi khi có thể xuất hiện với lượng tính toán huấn luyện giảm hoặc ít model parameters hơn, đặc biệt khi các mô hình được huấn luyện trên dữ liệu chất lượng cao hơn. Ngoài ra, sự xuất hiện của emergent abilities bị ảnh hưởng bởi các yếu tố như khối lượng và chất lượng của dữ liệu và số lượng parameters của mô hình. Emergent abilities trong Large Language Models xuất hiện khi các mô hình được scaled up và không thể dự đoán được bằng cách đơn thuần mở rộng các xu hướng quan sát được trong các mô hình nhỏ hơn.
Các Benchmark Đánh giá Emergent Abilities
Một số benchmarks được sử dụng để đánh giá emergent abilities của các mô hình ngôn ngữ, chẳng hạn như BIG-Bench, TruthfulQA, Massive Multi-task Language Understanding (MMLU) benchmark và Word in Context (WiC) benchmark. Các benchmarks chính bao gồm:
- BIG-Bench suite: bao gồm hơn 200 benchmarks kiểm tra một loạt các nhiệm vụ, chẳng hạn như các phép toán số học (ví dụ: “Q: 132 cộng 762 bằng bao nhiêu? A: 894”), chuyển tự từ Bảng chữ cái ngữ âm quốc tế (IPA) và giải mã từ. Những nhiệm vụ này đánh giá khả năng của mô hình trong việc thực hiện các phép tính, thao tác và sử dụng các từ hiếm và làm việc với bảng chữ cái. (ví dụ: “English: The 1931 Malay census was an alarm bell. IPA: ðə 1931 ˈmeɪleɪ ˈsɛnsəs wɑz ən əˈlɑrm bɛl.”). Hiệu suất của các mô hình như GPT-3 và LaMDA trên các nhiệm vụ này thường bắt đầu gần bằng không nhưng cho thấy sự gia tăng đáng kể trên mức ngẫu nhiên ở một quy mô nhất định, cho thấy emergent abilities. Chi tiết hơn về các benchmarks này có thể được tìm thấy trong kho lưu trữ Github.
- TruthfulQA benchmark: đánh giá khả năng cung cấp câu trả lời trung thực của mô hình. Nó bao gồm hai nhiệm vụ: tạo câu trả lời, trong đó mô hình trả lời một câu hỏi trong một hoặc hai câu, và trắc nghiệm, trong đó mô hình chọn câu trả lời đúng từ bốn lựa chọn hoặc câu đúng/sai. Khi mô hình Gopher được scaled đến kích thước lớn nhất của nó, hiệu suất của nó cải thiện đáng kể, vượt quá kết quả ngẫu nhiên hơn 20%, điều này biểu thị sự xuất hiện của khả năng này.
- Massive Multi-task Language Understanding (MMLU): đánh giá kiến thức thế giới và kỹ năng giải quyết vấn đề của mô hình trên 57 nhiệm vụ đa dạng, bao gồm toán học cơ bản, lịch sử Hoa Kỳ và khoa học máy tính. Mặc dù các mô hình GPTs, Gopher và Chinchilla ở một quy mô nhất định không vượt trội hơn mức đoán ngẫu nhiên trung bình trên tất cả các chủ đề, nhưng một mô hình kích thước lớn hơn cho thấy hiệu suất được cải thiện, cho thấy sự xuất hiện của khả năng này.
- The Word in Context (WiC) benchmark: tập trung vào sự hiểu biết ngữ nghĩa và liên quan đến một nhiệm vụ phân loại nhị phân cho các word embeddings nhạy cảm theo ngữ cảnh. Nó yêu cầu xác định xem các từ mục tiêu (động từ hoặc danh từ) trong hai ngữ cảnh có cùng nghĩa hay không. Các mô hình như Chinchilla ban đầu không vượt qua hiệu suất ngẫu nhiên trong các nhiệm vụ one-shot, ngay cả ở quy mô lớn. Tuy nhiên, khi các mô hình như PaLM được scaled đến một kích thước lớn hơn nhiều, hiệu suất trên mức ngẫu nhiên xuất hiện, cho thấy sự xuất hiện của khả năng này ở quy mô lớn hơn.
Các yếu tố dẫn đến Emergent Abilities
- Multi-step reasoning: liên quan đến việc hướng dẫn mô hình thực hiện một loạt các bước trung gian trước khi đưa ra kết quả cuối cùng. Phương pháp này, được gọi là chain-of-thought prompting, chỉ trở nên hiệu quả hơn standard prompting khi được áp dụng cho các mô hình đủ lớn.
- Một chiến lược khác là fine-tuning một mô hình trên nhiều nhiệm vụ được trình bày dưới dạng Instruction Following. Phương pháp này cho thấy hiệu suất được cải thiện chỉ với các mô hình có kích thước nhất định, nhấn mạnh tầm quan trọng của quy mô trong việc đạt được các khả năng tiên tiến.
Rủi ro với Emergent Abilities
Khi các mô hình ngôn ngữ được scaled up, các rủi ro emergent cũng trở thành mối quan tâm. Chúng bao gồm các thách thức xã hội liên quan đến độ chính xác, thiên vị và độc hại. Việc áp dụng các chiến lược khuyến khích các mô hình “hữu ích, vô hại và trung thực” có thể giảm thiểu những rủi ro này.
Ví dụ, benchmark WinoGender, đánh giá sự thiên vị giới tính trong bối cảnh nghề nghiệp, đã chỉ ra rằng mặc dù scaling có thể nâng cao hiệu suất của mô hình, nhưng nó cũng có thể khuếch đại sự thiên vị, đặc biệt là trong các tình huống mơ hồ. Các mô hình lớn hơn có xu hướng ghi nhớ dữ liệu huấn luyện nhiều hơn, nhưng các phương pháp như deduplication có thể giảm thiểu rủi ro này.
Các rủi ro khác liên quan đến các lỗ hổng tiềm ẩn hoặc tổng hợp nội dung có hại có thể phổ biến hơn trong các mô hình ngôn ngữ trong tương lai hoặc vẫn chưa được mô tả trong các mô hình hiện tại.
Sự thay đổi hướng tới các mô hình mục đích chung (General-Purpose Models)
Sự xuất hiện của các khả năng mới đã thay đổi quan điểm và việc sử dụng các mô hình này của cộng đồng NLP. Trong khi NLP truyền thống tập trung vào các mô hình dành riêng cho từng nhiệm vụ, việc scaling các mô hình đã thúc đẩy nghiên cứu về các mô hình “mục đích chung” có khả năng xử lý một loạt các nhiệm vụ không được đưa vào huấn luyện một cách rõ ràng.
Sự thay đổi này thể hiện rõ trong các trường hợp mà các mô hình mục đích chung được scaled, few-shot prompted đã vượt trội hơn các mô hình dành riêng cho từng nhiệm vụ được fine-tuned. Ví dụ bao gồm GPT-3 thiết lập các benchmarks mới trong TriviaQA và PiQA, PaLM xuất sắc trong suy luận số học và mô hình đa phương thức Flamingo đạt hiệu suất hàng đầu trong trả lời câu hỏi hình ảnh. Hơn nữa, khả năng thực hiện các nhiệm vụ của các mô hình mục đích chung với số lượng ví dụ tối thiểu đã mở rộng ứng dụng của chúng vượt ra ngoài nghiên cứu NLP truyền thống. Chúng bao gồm dịch hướng dẫn ngôn ngữ tự nhiên để thực hiện robot, tương tác người dùng và suy luận đa phương thức.
Expanding the Context Window
Tầm quan trọng của Độ dài Ngữ cảnh (Context Length)
Context window trong các mô hình ngôn ngữ đại diện cho số lượng input tokens mà mô hình có thể xử lý đồng thời. Trong các mô hình như GPT-4, hiện tại nó ở mức khoảng 32K hoặc khoảng 50 trang văn bản. Tuy nhiên, những tiến bộ gần đây đã mở rộng con số này lên đến 100K tokens ấn tượng hoặc khoảng 156 trang, như được thấy trong Claude của Anthropic.
Context length chủ yếu cho phép mô hình xử lý và hiểu các tập dữ liệu lớn hơn đồng thời, mang lại sự hiểu biết sâu sắc hơn về ngữ cảnh. Tính năng này đặc biệt có lợi khi nhập một lượng lớn dữ liệu cụ thể vào mô hình ngôn ngữ và đặt câu hỏi liên quan đến dữ liệu này. Ví dụ: khi phân tích một tài liệu dài về một công ty hoặc vấn đề cụ thể, context window lớn hơn cho phép mô hình ngôn ngữ xem xét và ghi nhớ nhiều thông tin độc đáo này hơn, dẫn đến các phản hồi chính xác và phù hợp hơn.
Hạn chế của Kiến trúc Transformer Gốc
Mặc dù có những điểm mạnh, kiến trúc transformer gốc phải đối mặt với những thách thức trong việc xử lý độ dài ngữ cảnh rộng lớn. Cụ thể, các hoạt động của lớp attention trong transformer có độ phức tạp thời gian và không gian bậc hai (biểu thị bằng ) liên quan đến số lượng input tokens, . Khi context length mở rộng, tài nguyên tính toán cần thiết cho quá trình huấn luyện và suy luận tăng lên đáng kể.
Để hiểu rõ hơn điều này, hãy xem xét độ phức tạp tính toán của kiến trúc transformer. Độ phức tạp của lớp attention trong mô hình transformer là , trong đó là context length (số lượng input tokens) và là kích thước nhúng (embedding size).
Độ phức tạp này xuất phát từ hai hoạt động chính trong lớp attention: phép chiếu tuyến tính để tạo ma trận Query, Key và Value (độ phức tạp ~ ) và phép nhân các ma trận này (độ phức tạp ~ ). Khi context length hoặc embedding size tăng lên, độ phức tạp tính toán cũng tăng lên theo bậc hai, gây ra thách thức cho việc xử lý context lengths lớn hơn.
Các Kỹ thuật Tối ưu hóa để Mở rộng Context Window
Bất chấp những thách thức tính toán liên quan đến kiến trúc transformer gốc, các nhà nghiên cứu đã phát triển một loạt các kỹ thuật tối ưu hóa để nâng cao hiệu quả của transformer và tăng khả năng context length lên 100K tokens:
- ALiBi Positional Encoding: transformer gốc sử dụng Positional Sinusoidal Encoding, gặp khó khăn trong việc suy luận context lengths lớn hơn. Mặt khác, ALiBi (Attention with Linear Biases) là một giải pháp có khả năng mở rộng tốt hơn. Kỹ thuật mã hóa vị trí này cho phép mô hình được huấn luyện trong các ngữ cảnh nhỏ hơn và sau đó được fine-tuned trong các ngữ cảnh lớn hơn, giúp nó thích ứng tốt hơn với các kích thước ngữ cảnh khác nhau.
- Sparse Attention: Sparse Attention giải quyết thách thức tính toán bằng cách tập trung điểm attention vào một tập hợp con của tokens. Phương pháp này giảm đáng kể độ phức tạp tính toán xuống thang tuyến tính theo số lượng tokens n, dẫn đến việc giảm đáng kể nhu cầu tính toán tổng thể.
- FlashAttention: FlashAttention tái cấu trúc tính toán lớp attention để tối ưu hóa hiệu quả GPU. Nó chia ma trận đầu vào thành các khối và sau đó xử lý đầu ra attention liên quan đến các khối này, tối ưu hóa việc sử dụng bộ nhớ GPU và tăng hiệu quả xử lý.
- Multi-Query Attention (MQA): MQA giảm mức tiêu thụ bộ nhớ trong bộ đệm giải mã key/value bằng cách tổng hợp trọng số trên tất cả các đầu attention trong quá trình chiếu tuyến tính của ma trận Key và Value. Sự hợp nhất này dẫn đến việc sử dụng bộ nhớ hiệu quả hơn.
FlashAttention-2
FlashAttention-2 nổi lên như một bước tiến so với FlashAttention ban đầu, tập trung vào việc tối ưu hóa tốc độ và hiệu quả bộ nhớ của lớp attention trong các mô hình transformer. Phiên bản nâng cấp này được phát triển lại từ đầu bằng cách sử dụng các nguyên thủy mới của Nvidia. Nó thực hiện nhanh hơn khoảng 2 lần so với phiên bản tiền nhiệm, đạt tới 230 TFLOPs trên GPU A100.
FlashAttention-2 cải thiện FlashAttention ban đầu theo nhiều cách:
- Thay đổi thuật toán để dành nhiều thời gian hơn cho matmul FLOPs nhằm giảm thiểu số lượng non-matmul FLOPs, vốn đắt hơn matmul FLOPs 16 lần.
- Tối ưu hóa tính song song trên các kích thước batch size, headcount và sequence length, dẫn đến sự tăng tốc đáng kể, đặc biệt đối với các chuỗi dài.
- Nâng cao việc phân vùng tác vụ trong mỗi khối luồng để giảm sự đồng bộ hóa và giao tiếp giữa các warps, dẫn đến ít lần đọc/ghi bộ nhớ dùng chung hơn.
- Thêm các tính năng như hỗ trợ kích thước đầu attention lên đến 256 và multi-query attention (MQA), tiếp tục mở rộng context window.
Với những cải tiến này, FlashAttention-2 là một bước thành công hướng tới việc mở rộng context window (trong khi vẫn giữ lại các hạn chế cơ bản của kiến trúc transformer gốc).
LongNet: A Leap Towards Billion-Token Context Window
LongNet: Mở Rộng Context Window Lên 1 Tỷ Tokens
LongNet đại diện cho một bước tiến mang tính chuyển đổi trong lĩnh vực tối ưu hóa transformer, như được trình bày chi tiết trong bài báo “LONGNET: Scaling Transformers to 1,000,000,000 Tokens”. Phương pháp sáng tạo này được thiết lập để mở rộng context window của các mô hình ngôn ngữ lên đến 1 tỷ tokens chưa từng có, tăng cường đáng kể khả năng xử lý và phân tích khối lượng dữ liệu lớn của chúng.
Dilated Attention: Cơ Chế Attention Đột Phá
Tiến bộ chính trong LongNet là việc triển khai “dilated attention” (attention giãn nở). Cơ chế attention sáng tạo này cho phép tăng trưởng theo cấp số nhân của trường attention khi khoảng cách giữa các tokens rộng hơn, đồng thời giảm tính toán attention khi khoảng cách giữa các tokens tăng lên (vì mỗi token sẽ chú ý đến một số lượng tokens nhỏ hơn). Cách tiếp cận thiết kế này cân bằng tài nguyên attention hạn chế và nhu cầu truy cập mọi token trong chuỗi.
Độ Phức Tạp Tuyến Tính: Cải Tiến So Với Transformer Truyền Thống
Cơ chế dilated attention của LongNet có độ phức tạp tính toán tuyến tính, một cải tiến lớn so với độ phức tạp bậc hai của transformer thông thường. Điều này đồng nghĩa với việc LongNet có thể xử lý các chuỗi dữ liệu cực dài một cách hiệu quả hơn nhiều so với các mô hình transformer truyền thống.
Tóm Tắt Các Điểm Chính:
- Mở rộng Context Window: LongNet có khả năng xử lý context window lên đến 1 tỷ tokens, mở ra khả năng xử lý dữ liệu cực lớn.
- Dilated Attention: Cơ chế attention giãn nở giúp cân bằng hiệu quả giữa việc truy cập toàn bộ chuỗi và giảm tải tính toán.
- Độ Phức Tạp Tuyến Tính: Cải thiện đáng kể hiệu quả tính toán so với transformer truyền thống, cho phép xử lý chuỗi dữ liệu dài hơn.
LongNet đánh dấu một bước tiến quan trọng trong việc xử lý dữ liệu chuỗi dài, mở ra những khả năng mới cho các ứng dụng như phân tích văn bản dài, xử lý dữ liệu gen và nhiều lĩnh vực khác.
A Timeline of the Most Popular LLMs
Dưới đây là dòng thời gian của một số LLMs phổ biến nhất trong 5 năm qua:
2018:
- GPT-1 (OpenAI): Đặt nền móng cho dòng GPT với kiến trúc transformer chỉ giải mã, tạo sinh. Tiên phong kết hợp unsupervised pretraining và supervised fine-tuning cho dự đoán văn bản ngôn ngữ tự nhiên.
2019:
- GPT-2 (OpenAI): Mở rộng kích thước mô hình lên 1.5 tỷ parameters, thể hiện tính linh hoạt của mô hình trên nhiều nhiệm vụ bằng cách sử dụng định dạng thống nhất cho đầu vào, đầu ra và thông tin nhiệm vụ.
2020:
- GPT-3 (OpenAI): Bước nhảy vọt với 175 tỷ parameters, giới thiệu in-context learning (ICL). Thể hiện hiệu suất vượt trội trong các nhiệm vụ NLP khác nhau, bao gồm lập luận và thích ứng miền, làm nổi bật tiềm năng của việc mở rộng quy mô mô hình.
2021:
- Codex (OpenAI): Biến thể GPT-3 được fine-tuned trên tập dữ liệu mã GitHub, thể hiện khả năng lập trình và giải quyết vấn đề toán học nâng cao.
- LaMDA (DeepMind): Tập trung vào các ứng dụng hội thoại, với 137 tỷ parameters. Nhằm mục đích nâng cao tạo sinh hội thoại và AI đàm thoại.
- Gopher (DeepMind): Với 280 tỷ parameters, đạt hiệu suất gần bằng con người trên benchmark MMLU nhưng đối mặt với những thách thức như thiên vị và thông tin sai lệch.
2022:
- InstructGPT (OpenAI): Cải tiến GPT-3, sử dụng reinforcement learning from human feedback để cải thiện tuân theo hướng dẫn và an toàn nội dung.
- Chinchilla (DeepMind): Với 70 tỷ parameters, tối ưu hóa việc sử dụng tài nguyên tính toán dựa trên scaling laws, đạt được những cải thiện đáng kể về độ chính xác trên các benchmark.
- PaLM (Google Research): Với 540 tỷ parameters, thể hiện hiệu suất few-shot vượt trội, hưởng lợi từ hệ thống Pathways của Google cho tính toán phân tán.
- ChatGPT (OpenAI): Dựa trên GPT-3.5 và GPT-4, được thiết kế riêng cho AI đàm thoại và thể hiện khả năng giao tiếp và lập luận giống con người.
2023:
- LLaMA (Meta AI): Giới thiệu một họ các mô hình ngôn ngữ lớn với parameters từ 7 tỷ đến 65 tỷ. Phá vỡ truyền thống truy cập hạn chế bằng cách cung cấp trọng số mô hình cho cộng đồng khoa học theo giấy phép phi thương mại.
- GPT-4 (OpenAI): Mở rộng khả năng sang đầu vào đa phương thức, vượt trội so với các phiên bản tiền nhiệm trong các nhiệm vụ khác nhau.
2024:
- Gemini 1.5 (Google): Nâng cấp đáng kể với kiến trúc Mixture-of-Experts mới và khả năng đa phương thức (Gemini 1.5 Pro), hỗ trợ hiểu biết ngữ cảnh dài và context window lên đến 1 triệu tokens.
- Gemma (Google): Hai phiên bản với 2 tỷ và 7 tỷ parameters, được phát triển trong giai đoạn huấn luyện Gemini và hiện có thể truy cập công khai.
- Claude 3 Opus (Anthropic): Đạt điểm số tương đương hoặc vượt GPT-4 trên các benchmark khác nhau. Với context window 200K tokens, được quảng cáo về khả năng ghi nhớ vượt trội.
- Mistral: Mô hình open-source tốt nhất hiện có thể truy cập để sử dụng, dựa trên kiến trúc Mixture of Experts.
- Infinite Attention (Google): Nghiên cứu khám phá các kỹ thuật có thể mở rộng vô hạn kích thước context window của mô hình.
Để tìm hiểu sâu hơn về các mô hình này, bạn nên đọc bài báo “A Survey of Large Language Models”.
History of NLP/LLMs
Đây là hành trình xuyên suốt sự phát triển của các mô hình ngôn ngữ (language modeling models), từ những mô hình thống kê ban đầu đến sự ra đời của các Mô hình Ngôn ngữ Lớn (Large Language Models - LLMs) đầu tiên. Thay vì một nghiên cứu kỹ thuật chuyên sâu, chương này trình bày một khám phá theo kiểu câu chuyện về việc xây dựng mô hình. Đừng lo lắng nếu một số chi tiết cụ thể của mô hình có vẻ phức tạp.
Sự Tiến Hóa của Mô Hình Ngôn Ngữ (The Evolution of Language Modeling)
Sự tiến hóa của các mô hình xử lý ngôn ngữ tự nhiên (natural language processing - NLP) là một câu chuyện về sự phát minh và cải tiến không ngừng. Mô hình “Túi Từ” (Bag of Words - BOW), một phương pháp đơn giản để đếm số lần xuất hiện của từ trong tài liệu, bắt đầu vào năm 1954. Sau đó, vào năm 1972, TF-IDF xuất hiện, cải tiến chiến lược này bằng cách điều chỉnh số lượng từ dựa trên độ hiếm hoặc tần suất. Sự ra đời của Word2Vec vào năm 2013 đánh dấu một bước đột phá quan trọng. Mô hình này sử dụng “nhúng từ” (word embeddings) để nắm bắt các liên kết ngữ nghĩa tinh tế giữa các từ mà các mô hình trước đó không thể.
Tiếp theo đó, Mạng Nơ-ron Tái Phát (Recurrent Neural Networks - RNNs) được giới thiệu. RNNs có khả năng học các mẫu trong chuỗi, cho phép chúng xử lý hiệu quả các tài liệu có độ dài khác nhau.
Sự ra mắt của kiến trúc Transformer vào năm 2017 đánh dấu một sự thay đổi mô hình trong lĩnh vực này. Cơ chế “chú ý” (attention mechanism) của mô hình cho phép nó tập trung vào các phần tử liên quan nhất của đầu vào một cách chọn lọc trong quá trình tạo đầu ra. Bước đột phá này đã mở đường cho BERT vào năm 2018. BERT sử dụng Transformer hai chiều (bidirectional transformer), tăng đáng kể hiệu suất trong nhiều công việc NLP truyền thống.
Những năm tiếp theo chứng kiến sự gia tăng trong sự phát triển của mô hình. Mỗi mô hình mới, chẳng hạn như RoBERTa, XLM, ALBERT và ELECTRA, đều giới thiệu các cải tiến và tối ưu hóa bổ sung, đẩy mạnh giới hạn của những gì có thể thực hiện được trong NLP.
Dòng Thời Gian của Mô Hình (Model’s Timeline)
- [1954] Túi Từ (Bag of Words - BOW):
- Mô hình “Túi Từ” là một phương pháp cơ bản đếm số lần xuất hiện của từ trong bản thảo. Mặc dù đơn giản, nó không thể xem xét thứ tự hoặc ngữ cảnh của từ.
- [1972] TF-IDF:
- TF-IDF mở rộng trên BOW bằng cách tăng trọng lượng cho các từ hiếm và giảm trọng lượng cho các thuật ngữ phổ biến, cải thiện khả năng của mô hình trong việc phát hiện mức độ liên quan của tài liệu. Tuy nhiên, nó không đề cập đến ngữ cảnh từ.
- [2013] Word2Vec:
- “Nhúng từ” (word embeddings) là các vectơ đa chiều gói gọn các liên kết ngữ nghĩa, như được mô tả bởi Word2Vec. Đây là một bước tiến đáng kể trong việc nắm bắt ngữ nghĩa văn bản.
- [2014] RNNs trong kiến trúc Encoder-Decoder:
- RNNs là một bước tiến quan trọng, có khả năng tính toán “nhúng tài liệu” (document embeddings) và thêm ngữ cảnh từ. Chúng phát triển bao gồm LSTM (1997) cho các phụ thuộc dài hạn và RNN hai chiều (Bidirectional RNN) (1997) để hiểu ngữ cảnh. Encoder-Decoder RNNs (2014) cải thiện phương pháp này.
- [2017] Transformer:
- Transformer, với cơ chế “chú ý” (attention mechanisms), đã cải thiện đáng kể việc tính toán “nhúng” (embedding computation) và sự căn chỉnh giữa đầu vào và đầu ra, cách mạng hóa các tác vụ NLP.
- [2018] BERT:
- BERT, một Transformer hai chiều (bidirectional transformer), đạt được kết quả NLP ấn tượng bằng cách sử dụng “chú ý toàn cục” (global attention) và kết hợp các mục tiêu đào tạo.
- [2018] GPT:
- Kiến trúc Transformer đã được sử dụng để tạo ra mô hình tự hồi quy (autoregressive model) đầu tiên, GPT. Sau đó, nó phát triển thành GPT-2 [2019], một phiên bản lớn hơn và được tối ưu hóa hơn của GPT được đào tạo trước trên WebText, và GPT-3 [2020], một phiên bản lớn hơn và được tối ưu hóa hơn của GPT-2 được đào tạo trước trên Common Crawl.
- [2019] CTRL:
- CTRL, tương tự như GPT, giới thiệu các mã điều khiển cho phép tạo văn bản có điều kiện. Tính năng này tăng cường khả năng kiểm soát nội dung và phong cách của văn bản được tạo ra.
- [2019] Transformer-XL:
- Transformer-XL đổi mới bằng cách tái sử dụng các trạng thái ẩn (hidden states) đã được tính toán trước đó, cho phép mô hình duy trì bộ nhớ ngữ cảnh dài hơn. Sự cải tiến này cải thiện đáng kể khả năng của mô hình trong việc xử lý các chuỗi văn bản mở rộng.
- [2019] ALBERT:
- ALBERT cung cấp một phiên bản hiệu quả hơn của BERT bằng cách triển khai Dự đoán Thứ tự Câu (Sentence Order Prediction) thay vì Dự đoán Câu Tiếp theo (Next Sentence Prediction) và sử dụng các kỹ thuật giảm tham số. Những thay đổi này dẫn đến việc sử dụng bộ nhớ thấp hơn và đào tạo nhanh hơn.
- [2019] RoBERTa:
- RoBERTa cải thiện BERT bằng cách giới thiệu Mô hình Ngôn ngữ Mặt nạ Động (dynamic Masked Language Modeling), bỏ qua Dự đoán Câu Tiếp theo (Next Sentence Prediction), sử dụng bộ mã hóa BPE (BPE tokenizer) và sử dụng các siêu tham số tốt hơn để tăng cường hiệu suất.
- [2019] XLM:
- XLM là một Transformer đa ngôn ngữ, được đào tạo trước bằng nhiều mục tiêu khác nhau, bao gồm Mô hình Ngôn ngữ Nhân quả (Causal Language Modeling), Mô hình Ngôn ngữ Mặt nạ (Masked Language Modeling) và Mô hình Ngôn ngữ Dịch (Translation Language Modeling), phục vụ cho các tác vụ NLP đa ngôn ngữ.
- [2019] XLNet:
- XLNet kết hợp các điểm mạnh của Transformer-XL với phương pháp đào tạo trước tự hồi quy tổng quát, cho phép học các phụ thuộc hai chiều và cung cấp hiệu suất được cải thiện so với các mô hình đơn hướng truyền thống.
- [2019] PEGASUS:
- PEGASUS có bộ mã hóa hai chiều và bộ giải mã từ trái sang phải, được đào tạo trước bằng các mục tiêu như Mô hình Ngôn ngữ Mặt nạ (Masked Language Modeling) và Tạo Câu Khoảng trống (Gap Sentence Generation), tối ưu hóa nó cho các tác vụ tóm tắt.
- [2019] DistilBERT:
- DistilBERT giới thiệu một phiên bản nhỏ hơn, nhanh hơn của BERT, giữ lại hơn 95% hiệu suất của nó. Mô hình này được đào tạo bằng các kỹ thuật chưng cất để nén mô hình BERT được đào tạo trước.
- [2019] XLM-RoBERTa:
- XLM-RoBERTa là một bản chuyển thể đa ngôn ngữ của RoBERTa, được đào tạo trên một tập hợp đa ngôn ngữ đa dạng, chủ yếu sử dụng mục tiêu Mô hình Ngôn ngữ Mặt nạ (Masked Language Modeling), tăng cường khả năng đa ngôn ngữ của nó.
- [2019] BART:
- BART, với bộ mã hóa hai chiều và bộ giải mã từ trái sang phải, được đào tạo bằng cách cố ý làm hỏng văn bản và sau đó học cách xây dựng lại bản gốc, làm cho nó thực tế cho một loạt các tác vụ tạo và hiểu.
- [2019] ConvBERT:
- ConvBERT đổi mới bằng cách thay thế các khối tự chú ý truyền thống bằng các mô-đun kết hợp tích chập, cho phép xử lý hiệu quả hơn các ngữ cảnh toàn cục và cục bộ trong văn bản.
- [2020] Funnel Transformer:
- Funnel Transformer đổi mới bằng cách nén dần chuỗi trạng thái ẩn thành một chuỗi ngắn hơn, giảm chi phí tính toán một cách hiệu quả trong khi vẫn duy trì hiệu suất.
- [2020] Reformer:
- Reformer cung cấp một phiên bản hiệu quả hơn của Transformer. Nó sử dụng băm nhạy cảm cục
Chapter II: LLM Architectures and Landscape
Understanding Transformers
Kiến trúc transformer đã chứng minh tính linh hoạt của nó trong nhiều ứng dụng khác nhau. Mạng lưới ban đầu được trình bày dưới dạng kiến trúc encoder-decoder cho các nhiệm vụ dịch thuật. Sự tiến hóa tiếp theo của kiến trúc transformer bắt đầu với sự ra đời của các mô hình chỉ có encoder như BERT, tiếp theo là sự ra đời của các mạng lưới chỉ có decoder trong phiên bản đầu tiên của các mô hình GPT.
Sự khác biệt không chỉ mở rộng ra ngoài thiết kế mạng lưới mà còn bao gồm cả các mục tiêu học tập (learning objectives). Những mục tiêu học tập tương phản này đóng một vai trò quan trọng trong việc định hình hành vi và kết quả của mô hình. Hiểu rõ những khác biệt này là điều cần thiết để chọn kiến trúc phù hợp nhất cho một nhiệm vụ cụ thể và đạt được hiệu suất tối ưu trong nhiều ứng dụng khác nhau.
Trong chương này, chúng ta sẽ khám phá transformers sâu hơn, cung cấp sự hiểu biết toàn diện về các thành phần khác nhau của chúng và các cơ chế bên trong mạng lưới. Chúng ta cũng sẽ xem xét bài báo mang tính bước ngoặt “Attention is all you need”.
Chúng ta cũng sẽ tải các mô hình được huấn luyện trước (pre-trained models) để làm nổi bật sự khác biệt giữa kiến trúc transformer và GPT và kiểm tra những đổi mới mới nhất trong lĩnh vực này với các mô hình đa phương thức lớn (large multimodal models - LMMs).
Attention Is All You Need
“Attention Is All You Need” là một tiêu đề rất dễ nhớ trong lĩnh vực xử lý ngôn ngữ tự nhiên (NLP). Bài báo “Attention Is All You Need” đánh dấu một cột mốc quan trọng trong việc phát triển kiến trúc mạng nơ-ron cho NLP. Sự hợp tác giữa Google Brain và Đại học Toronto đã giới thiệu transformer, một mạng encoder-decoder khai thác cơ chế attention cho các nhiệm vụ dịch tự động. Mô hình transformer đã đạt được điểm số state-of-the-art mới là 41.8 trên tập dữ liệu (WMT 2014) cho nhiệm vụ dịch từ tiếng Anh sang tiếng Pháp. Đáng chú ý, mức hiệu suất này đạt được chỉ sau 3.5 ngày huấn luyện trên tám GPU, cho thấy sự giảm đáng kể về chi phí huấn luyện so với các mô hình trước đó.
Transformers đã thay đổi đáng kể lĩnh vực này và đã chứng minh hiệu quả vượt trội trong các nhiệm vụ khác nhau ngoài dịch thuật, bao gồm phân loại, tóm tắt và tạo sinh ngôn ngữ. Một cải tiến quan trọng của transformer là cấu trúc mạng song song cao, giúp tăng cường cả hiệu quả và hiệu suất trong quá trình huấn luyện.
The Architecture

Như bạn thấy trong sơ đồ, kiến trúc gốc được thiết kế cho các nhiệm vụ sequence-to-sequence (nơi một chuỗi được đưa vào và một đầu ra được tạo ra dựa trên nó), chẳng hạn như dịch thuật. Trong quá trình này, encoder tạo ra một biểu diễn của cụm từ đầu vào và decoder tạo ra đầu ra của nó bằng cách sử dụng biểu diễn này làm tham chiếu.
Tổng quan về kiến trúc Transformer. Thành phần bên trái được gọi là encoder, được kết nối với decoder bằng cơ chế cross-attention.
Nghiên cứu sâu hơn về kiến trúc đã dẫn đến việc phân chia nó thành ba loại riêng biệt, được phân biệt bởi tính linh hoạt và khả năng chuyên biệt trong việc xử lý các nhiệm vụ khác nhau:
- Loại chỉ có encoder được dành riêng để trích xuất các biểu diễn nhận thức ngữ cảnh từ dữ liệu đầu vào. Một mô hình đại diện từ loại này là BERT, có thể hữu ích cho các nhiệm vụ phân loại.
- Loại encoder-decoder tạo điều kiện cho các nhiệm vụ sequence-to-sequence như dịch thuật, tóm tắt và huấn luyện các mô hình đa phương thức như trình tạo chú thích. Một ví dụ về mô hình thuộc phân loại này là BART.
- Loại chỉ có decoder được thiết kế đặc biệt để tạo ra đầu ra bằng cách tuân theo các hướng dẫn được cung cấp, như được thể hiện trong LLMs. Một mô hình đại diện trong loại này là họ GPT.
Tiếp theo, chúng ta sẽ đề cập đến sự tương phản giữa các lựa chọn thiết kế này và ảnh hưởng của chúng đến các nhiệm vụ khác nhau. Tuy nhiên, như bạn có thể thấy từ sơ đồ, một số khối xây dựng, như lớp nhúng (embedding layers) và cơ chế attention, được chia sẻ trên cả thành phần encoder và decoder. Hiểu rõ những yếu tố này sẽ giúp cải thiện sự hiểu biết của bạn về cách các mô hình hoạt động bên trong. Phần này phác thảo các thành phần chính và sau đó chứng minh cách tải một mô hình mã nguồn mở để theo dõi từng bước.
Nhúng đầu vào (Input Embedding)
Như chúng ta đã thấy trong kiến trúc transformer, bước đầu tiên là biến các mã thông báo đầu vào (từ hoặc từ phụ) thành các nhúng (embeddings). Các nhúng này là các vectơ đa chiều nắm bắt các đặc điểm ngữ nghĩa của các mã thông báo đầu vào. Bạn có thể xem chúng như một danh sách lớn các đặc điểm đại diện cho các từ đang được nhúng. Danh sách này chứa hàng nghìn số mà mô hình tự học để biểu diễn thế giới của chúng ta. Thay vì làm việc với các câu, từ và từ đồng nghĩa để so sánh mọi thứ với nhau, đòi hỏi sự hiểu biết về ngôn ngữ của chúng ta, nó làm việc với các danh sách số này để so sánh chúng về mặt số học bằng các phép tính cơ bản, trừ và cộng các vectơ đó lại với nhau để xem chúng có giống nhau hay không. Nghe có vẻ phức tạp hơn nhiều so với việc hiểu chính các từ, phải không? Đây là lý do tại sao kích thước của các vectơ nhúng này khá lớn. Khi bạn không thể hiểu ý nghĩa và từ ngữ, bạn cần hàng nghìn giá trị đại diện cho chúng. Kích thước này thay đổi tùy thuộc vào kiến trúc của mô hình. GPT-3 của OpenAI, chẳng hạn, sử dụng các vectơ nhúng 12.000 chiều, nhưng các mô hình nhỏ hơn như BERT sử dụng các nhúng 768 chiều. Lớp này cho phép mô hình hiểu và xử lý đầu vào một cách hiệu quả, đóng vai trò là nền tảng cho tất cả các lớp tiếp theo.
Mã hóa vị trí (Positional Encoding)
Các mô hình trước đó, chẳng hạn như Mạng nơ-ron hồi quy (RNN), xử lý đầu vào tuần tự, từng mã thông báo một, tự nhiên bảo toàn thứ tự của văn bản. Không giống như những mô hình này, transformers không có khả năng xử lý tuần tự tích hợp. Thay vào đó, chúng sử dụng mã hóa vị trí để duy trì thứ tự của các từ trong một cụm từ cho các lớp tiếp theo. Các mã hóa này là các vectơ được điền các giá trị duy nhất tại mỗi chỉ mục, khi kết hợp với các nhúng đầu vào, cung cấp cho mô hình dữ liệu liên quan đến vị trí tương đối hoặc tuyệt đối của các mã thông báo trong chuỗi. Các vectơ này mã hóa vị trí của mỗi từ, đảm bảo rằng mô hình xác định thứ tự từ, điều này cần thiết để giải thích ngữ cảnh và ý nghĩa của một câu.
Cơ chế tự chú ý (Self-Attention Mechanism)
Cơ chế tự chú ý là cốt lõi của mô hình transformer, tính toán tổng trọng số của các nhúng của tất cả các từ trong một cụm từ. Các trọng số này được tính toán bằng cách sử dụng điểm “chú ý” được học giữa các từ. Trọng số “chú ý” cao hơn sẽ được gán cho các thuật ngữ có liên quan chặt chẽ hơn với nhau. Dựa trên đầu vào, điều này được thực hiện bằng cách sử dụng các vectơ Truy vấn, Khóa và Giá trị. Đây là mô tả ngắn gọn về từng vectơ:
- Vectơ Truy vấn (Query Vector): Đây là từ hoặc mã thông báo mà trọng số chú ý được tính toán. Vectơ Truy vấn chỉ định phần nào của chuỗi đầu vào cần được ưu tiên. Khi bạn nhân các nhúng từ với vectơ Truy vấn, bạn hỏi: “Tôi nên chú ý đến điều gì?”
- Vectơ Khóa (Key Vector): Tập hợp các từ hoặc mã thông báo trong chuỗi đầu vào được so sánh với Truy vấn. Vectơ Khóa hỗ trợ xác định thông tin quan trọng hoặc có liên quan trong chuỗi đầu vào. Khi bạn nhân các nhúng từ với vectơ Khóa, bạn tự hỏi: “Điều gì quan trọng cần xem xét?”
- Vectơ Giá trị (Value Vector): Nó lưu trữ thông tin hoặc đặc điểm liên quan đến mỗi từ hoặc mã thông báo trong chuỗi đầu vào. Vectơ Giá trị chứa dữ liệu thực tế sẽ được cân nhắc và trộn lẫn theo trọng số chú ý được tính toán giữa Truy vấn và Khóa. Vectơ Giá trị trả lời truy vấn: “Chúng ta có thông tin gì?”
Trước khi giới thiệu thiết kế transformer, cơ chế chú ý chủ yếu được sử dụng để so sánh hai phần của văn bản. Ví dụ, mô hình có thể tập trung vào các khu vực khác nhau của bài viết đầu vào trong khi tạo bản tóm tắt cho một nhiệm vụ như tóm tắt.
Cơ chế tự chú ý cho phép các mô hình làm nổi bật các phần quan trọng nhất của văn bản. Nó có thể được sử dụng trong các mô hình chỉ có encoder hoặc chỉ có decoder để xây dựng một biểu diễn đầu vào mạnh mẽ. Văn bản có thể được dịch thành nhúng cho các kịch bản chỉ có encoder, nhưng các mô hình chỉ có decoder cho phép tạo văn bản.
Việc triển khai cơ chế đa đầu chú ý (multi-head attention) giúp tăng cường đáng kể độ chính xác của nó. Trong thiết lập này, nhiều thành phần chú ý xử lý cùng một thông tin, với mỗi đầu học cách tập trung vào các đặc điểm duy nhất của văn bản, chẳng hạn như động từ, danh từ, số và hơn thế nữa, trong suốt quá trình huấn luyện và tạo.
The Architecture In Action
Tìm Notebook cho phần này tại towardsai.net/book.
Việc xem kiến trúc trong hành động sẽ cho thấy các thành phần trên hoạt động như thế nào trong một mô hình ngôn ngữ lớn đã được huấn luyện trước (pre-trained large language model), cung cấp cái nhìn sâu sắc về hoạt động bên trong của chúng bằng cách sử dụng thư viện Transformers của Hugging Face. Bạn sẽ học cách tải một pre-trained tokenizer để chuyển đổi văn bản thành token IDs, sau đó đưa các đầu vào vào từng lớp của mạng và kiểm tra đầu ra.
Đầu tiên, sử dụng AutoModelForCausalLM và AutoTokenizer để tải mô hình và tokenizer tương ứng. Sau đó, tokenize một câu mẫu sẽ được sử dụng làm đầu vào trong các bước tiếp theo.
from transformers import AutoModelForCausalLM, AutoTokenizer
OPT = AutoModelForCausalLM.from_pretrained("facebook/opt-1.3b", load_in_8bit=True)
tokenizer = AutoTokenizer.from_pretrained("facebook/opt-1.3b")
inp = "The quick brown fox jumps over the lazy dog"
inp_tokenized = tokenizer(inp, return_tensors="pt")
print(inp_tokenized['input_ids'].size())
print(inp_tokenized)
torch.Size([1, 10])
{'input_ids': tensor([[ 2, 133, 2119, 6219, 23602, 13855, 81,
5, 22414, 2335]]), 'attention_mask': tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]])}
Chúng ta tải mô hình Open Pre-trained transformer của Facebook với 1.3B tham số (facebook/opt-1.3b) ở định dạng 8-bit, một chiến lược tiết kiệm bộ nhớ để sử dụng hiệu quả tài nguyên GPU. Đối tượng tokenizer tải từ vựng cần thiết để tương tác với mô hình và được sử dụng để chuyển đổi đầu vào mẫu (biến inp) thành token IDs và attention mask. Attention mask là một vector được thiết kế để giúp bỏ qua các tokens cụ thể. Trong ví dụ đã cho, tất cả các chỉ số của vector attention mask được đặt thành 1, cho biết rằng mọi token sẽ được xử lý bình thường. Tuy nhiên, bằng cách đặt một chỉ số trong vector attention mask thành 0, bạn có thể hướng dẫn mô hình bỏ qua các tokens cụ thể từ đầu vào. Ngoài ra, hãy lưu ý cách đầu vào văn bản được chuyển đổi thành token IDs bằng từ điển được huấn luyện trước của mô hình.
Tiếp theo, hãy kiểm tra kiến trúc của mô hình bằng cách sử dụng phương thức .model.
print(OPT.model)
OPTModel(
(decoder): OPTDecoder(
(embed_tokens): Embedding(50272, 2048, padding_idx=1)
(embed_positions): OPTLearnedPositionalEmbedding(2050, 2048)
(final_layer_norm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(layers): ModuleList(
(0-23): 24 x OPTDecoderLayer(
(self_attn): OPTAttention(
(k_proj): Linear8bitLt(in_features=2048, out_features=2048, bias=True)
(v_proj): Linear8bitLt(in_features=2048, out_features=2048, bias=True)
(q_proj): Linear8bitLt(in_features=2048, out_features=2048, bias=True)
(out_proj): Linear8bitLt(in_features=2048, out_features=2048, bias=True)
)
(activation_fn): ReLU()
(self_attn_layer_norm): LayerNorm((2048,), eps=1e-05,
elementwise_affine=True)
(fc1): Linear8bitLt(in_features=2048, out_features=8192, bias=True)
(fc2): Linear8bitLt(in_features=8192, out_features=2048, bias=True)
(final_layer_norm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
)
)
)
)
Mô hình decoder-only là một lựa chọn phổ biến cho các mô hình ngôn ngữ dựa trên transformer. Do đó, chúng ta phải sử dụng khóa decoder để truy cập vào hoạt động bên trong của nó. Khóa layers cũng tiết lộ rằng thành phần decoder bao gồm 24 lớp xếp chồng lên nhau với cùng một thiết kế. Để bắt đầu, hãy xem xét lớp embedding.
embedded_input = OPT.model.decoder.embed_tokens(inp_tokenized['input_ids'])
print("Layer:\t", OPT.model.decoder.embed_tokens)
print("Size:\t", embedded_input.size())
print("Output:\t", embedded_input)
Layer: Embedding(50272, 2048, padding_idx=1)
Size: torch.Size([1, 10, 2048])
Output: tensor([[[-0.0407, 0.0519, 0.0574, ..., -0.0263, -0.0355, -0.0260],
[-0.0371, 0.0220, -0.0096, ..., 0.0265, -0.0166, -0.0030],
[-0.0455, -0.0236, -0.0121, ..., 0.0043, -0.0166, 0.0193],
...,
[ 0.0007, 0.0267, 0.0257, ..., 0.0622, 0.0421, 0.0279],
[-0.0126, 0.0347, -0.0352, ..., -0.0393, -0.0396, -0.0102],
[-0.0115, 0.0319, 0.0274, ..., -0.0472, -0.0059, 0.0341]]],
device='cuda:0', dtype=torch.float16, grad_fn=<EmbeddingBackward0>)
Lớp embedding được truy cập thông qua phương thức .embed_tokens của đối tượng decoder, phương thức này cung cấp đầu vào đã được tokenize của chúng ta cho lớp. Như bạn có thể thấy, lớp embedding sẽ chuyển đổi một danh sách IDs có kích thước [1, 10] thành [1, 10, 2048]. Biểu diễn này sau đó sẽ được sử dụng và truyền qua các lớp decoder.
Như đã đề cập trước đó, thành phần positional encoding sử dụng attention masks để xây dựng một vector truyền tín hiệu định vị trong mô hình. Các positional embeddings được tạo bằng phương thức .embed_positions của decoder. Như có thể thấy, lớp này tạo ra một vector duy nhất cho mỗi vị trí, sau đó được thêm vào đầu ra của lớp embedding. Lớp này thêm thông tin vị trí vào mô hình.
embed_pos_input = OPT.model.decoder.embed_positions(
inp_tokenized['attention_mask']
)
print("Layer:\t", OPT.model.decoder.embed_positions)
print("Size:\t", embed_pos_input.size())
print("Output:\t", embed_pos_input)
Layer: OPTLearnedPositionalEmbedding(2050, 2048)
Size: torch.Size([1, 10, 2048])
Output: tensor([[[-8.1406e-03, -2.6221e-01, 6.0768e-03, ..., 1.7273
Transformer Model’s Design Choices
Bạn có thể tìm Notebook cho phần này tại towardsai.net/book.
Kiến trúc Transformer đã chứng minh khả năng thích ứng của nó cho nhiều ứng dụng khác nhau. Mô hình gốc được giới thiệu cho nhiệm vụ dịch thuật encoder-decoder. Sau sự xuất hiện của các mô hình chỉ có encoder như BERT, sự tiến hóa của thiết kế transformer tiếp tục với sự ra đời của các mạng chỉ có decoder trong phiên bản đầu tiên của các mô hình GPT.
Các biến thể không chỉ giới hạn ở kiến trúc mạng mà còn bao gồm sự khác biệt trong các mục tiêu học tập (learning objectives). Những mục tiêu học tập khác nhau này ảnh hưởng đáng kể đến hành vi và kết quả của mô hình. Việc hiểu rõ những điểm khác biệt này là rất quan trọng để chọn thiết kế tốt nhất cho một nhiệm vụ cụ thể và đạt được hiệu suất cao nhất trong các ứng dụng khác nhau.
The Encoder-Decoder Architecture
Kiến trúc transformer hoàn chỉnh, thường được gọi là mô hình encoder-decoder, bao gồm một số lớp encoder xếp chồng lên nhau, được liên kết với một số lớp decoder thông qua cơ chế cross-attention. Kiến trúc này giống hệt như chúng ta đã thấy trong phần trước.
Các mô hình này đặc biệt hiệu quả cho các nhiệm vụ liên quan đến việc chuyển đổi một chuỗi thành một chuỗi khác, như dịch thuật hoặc tóm tắt văn bản, nơi cả đầu vào và đầu ra đều dựa trên văn bản. Nó cũng rất hữu ích trong các ứng dụng đa phương thức (multi-modal applications), chẳng hạn như chú thích hình ảnh (image captioning), nơi đầu vào là một hình ảnh và đầu ra mong muốn là chú thích tương ứng của nó. Trong những kịch bản này, cross-attention đóng một vai trò quan trọng, hỗ trợ decoder tập trung vào các phần nội dung phù hợp nhất trong suốt quá trình tạo sinh.
Một ví dụ điển hình của phương pháp này là mô hình tiền huấn luyện BART, có một encoder hai chiều được giao nhiệm vụ tạo ra một biểu diễn chi tiết của đầu vào. Đồng thời, một decoder tự hồi quy (autoregressive decoder) tạo ra đầu ra tuần tự, từng token một. Mô hình này xử lý một đầu vào nơi một số phần bị che ngẫu nhiên cùng với một đầu vào được dịch chuyển một token. Nó cố gắng tái tạo đầu vào ban đầu, đặt nhiệm vụ này làm mục tiêu học tập (learning goal) của nó. Mã được cung cấp bên dưới tải mô hình BART để kiểm tra kiến trúc của nó.
from transformers import AutoModel, AutoTokenizer
BART = AutoModel.from_pretrained("facebook/bart-large")
print(BART)
BartModel(
(shared): Embedding(50265, 1024, padding_idx=1)
(encoder): BartEncoder(
(embed_tokens): Embedding(50265, 1024, padding_idx=1)
(embed_positions): BartLearnedPositionalEmbedding(1026, 1024)
(layers): ModuleList(
(0-11): 12 x BartEncoderLayer(
(self_attn): BartAttention(
(k_proj): Linear(in_features=1024, out_features=1024, bias=True)
(v_proj): Linear(in_features=1024, out_features=1024, bias=True)
(q_proj): Linear(in_features=1024, out_features=1024, bias=True)
(out_proj): Linear(in_features=1024, out_features=1024, bias=True)
)
(self_attn_layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(activation_fn): GELUActivation()
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(final_layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
)
)
(layernorm_embedding): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
)
(decoder): BartDecoder(
(embed_tokens): Embedding(50265, 1024, padding_idx=1)
(embed_positions): BartLearnedPositionalEmbedding(1026, 1024)
(layers): ModuleList(
(0-11): 12 x BartDecoderLayer(
(self_attn): BartAttention(
(k_proj): Linear(in_features=1024, out_features=1024, bias=True)
(v_proj): Linear(in_features=1024, out_features=1024, bias=True)
(q_proj): Linear(in_features=1024, out_features=1024, bias=True)
(out_proj): Linear(in_features=1024, out_features=1024, bias=True)
)
(activation_fn): GELUActivation()
(self_attn_layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(encoder_attn): BartAttention(
(k_proj): Linear(in_features=1024, out_features=1024, bias=True)
(v_proj): Linear(in_features=1024, out_features=1024, bias=True)
(q_proj): Linear(in_features=1024, out_features=1024, bias=True)
(out_proj): Linear(in_features=1024, out_features=1024, bias=True)
)
(encoder_attn_layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
(fc1): Linear(in_features=1024, out_features=4096, bias=True)
(fc2): Linear(in_features=4096, out_features=1024, bias=True)
(final_layer_norm): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
)
)
(layernorm_embedding): LayerNorm((1024,), eps=1e-05, elementwise_affine=True)
)
)
Chúng ta đã quen thuộc với hầu hết các lớp trong mô hình BART. Mô hình này bao gồm các thành phần encoder và decoder, mỗi thành phần có 12 lớp. Hơn nữa, thành phần decoder, đặc biệt, kết hợp một lớp encoder_attn bổ sung được gọi là cross-attention. Thành phần cross-attention sẽ điều kiện hóa đầu ra của decoder dựa trên các biểu diễn encoder. Chúng ta có thể sử dụng chức năng transformers pipeline và phiên bản tinh chỉnh của mô hình này để tóm tắt.
from transformers import pipeline
summarizer = pipeline("summarization", model="facebook/bart-large-cnn")
sum = summarizer("""Gaga was best known in the 2010s for pop hits like “Poker Face” and avant-garde experimentation on albums like “Artpop,” and Bennett, a singer who mostly stuck to standards, was in his 80s when the pair met. And yet Bennett and Gaga became fast friends and close collaborators, which they remained until Bennett’s death at 96 on Friday. They recorded two albums together, 2014’s “Cheek to Cheek” and 2021’s “Love for Sale,” which both won Grammys for best traditional pop vocal album.""", min_length=20, max_length=50)
print(sum[0]['summary_text'])
Bennett and Gaga became fast friends and close collaborators.
They recorded two albums together, 2014's "Cheek to Cheek" and 2021's
"Love for Sale"
The Encoder-Only Architecture
Tổng quan về kiến trúc encoder-only với các đầu attention và feed forward, nhận đầu vào, nhúng nó, đi qua nhiều khối encoder và đầu ra của nó thường được gửi đến một khối decoder của kiến trúc transformer hoặc được sử dụng trực tiếp cho các nhiệm vụ hiểu ngôn ngữ và phân loại.
Các mô hình encoder-only được tạo ra bằng cách xếp chồng nhiều thành phần encoder. Vì đầu ra của encoder không thể được ghép nối với một decoder khác, nó chỉ có thể được sử dụng như một phương pháp chuyển văn bản thành vector để đo lường độ tương tự. Nó cũng có thể được ghép nối với một đầu phân loại (classification head) (lớp feedforward) trên cùng để giúp dự đoán nhãn (còn được gọi là lớp Pooler trong các thư viện như Hugging Face).
Sự vắng mặt của lớp Masked Self-Attention là sự khác biệt cơ bản trong kiến trúc encoder-only. Do đó, encoder có thể xử lý toàn bộ đầu vào cùng một lúc. (Không giống như decoder, các token tương lai phải được che giấu trong quá trình huấn luyện để tránh “gian lận” khi tạo ra các token mới.) Đặc điểm này làm cho chúng đặc biệt phù hợp để tạo ra các biểu diễn vector từ một tài liệu, đảm bảo việc giữ lại tất cả thông tin.
Bài báo BERT (hoặc một biến thể chất lượng cao hơn như RoBERTa) đã giới thiệu một mô hình tiền huấn luyện nổi tiếng, giúp cải thiện đáng kể điểm số state-of-the-art trên nhiều nhiệm vụ NLP khác nhau. Mô hình này được tiền huấn luyện với hai mục tiêu học tập (learning objectives) trong tâm trí:
- Masked Language Modeling: che giấu các token ngẫu nhiên trong đầu vào và cố gắng dự đoán các token bị che giấu này.
- Next Sentence Prediction: trình bày các câu theo cặp và xác định xem câu thứ hai có theo logic câu đầu tiên trong một chuỗi văn bản hay không.
BERT = AutoModel.from_pretrained("bert-base-uncased")
print(BERT)
BertModel(
(embeddings): BertEmbeddings(
(word_embeddings): Embedding(30522, 768, padding_idx=0)
(position_embeddings): Embedding(512, 768)
(token_type_embeddings): Embedding(2, 768)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(encoder): BertEncoder(
(layer): ModuleList(
(0-11): 12 x BertLayer(
(attention): BertAttention(
(self): BertSelfAttention(
(query): Linear(in_features=768, out_features=768, bias=True)
(key): Linear(in_features=768, out_features=768, bias=True)
(value): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.1, inplace=False)
)
(output): BertSelfOutput(
(dense): Linear(in_features=768, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
(intermediate): BertIntermediate(
(dense): Linear(in_features=768, out_features=3072, bias=True)
(intermediate_act_fn): GELUActivation()
)
(output): BertOutput(
(dense): Linear(in_features=3072, out_features=768, bias=True)
(LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True)
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
)
(pooler): BertPooler(
(dense): Linear(in_features=768, out_features=768, bias=True)
(activation): Tanh()
)
)
Mô hình BERT sử dụng kiến trúc transformer truyền thống với 12 khối encoder xếp chồng lên nhau. Tuy nhiên, đầu ra của mạng sẽ được chuyển đến một lớp pooler, một lớp tuyến tính feed-forward theo sau là phi tuyến tính, sẽ xây dựng biểu diễn cuối cùng. Biểu diễn này sẽ được sử dụng cho các nhiệm vụ khác như phân loại và đánh giá độ tương tự. Mã bên dưới sử dụng phiên bản tinh chỉnh của mô hình BERT cho phân tích cảm xúc:
classifier = pipeline("text-classification", model="nlptown/bert-base-multilingual-uncased-sentiment")
lbl = classifier("""This restaurant is awesome.""")
print(lbl)
[{'label': '5 stars', 'score': 0.8550480604171753}]
The Decoder-Only Architecture
Tổng quan về kiến trúc decoder-only với các đầu attention và feed forward. Đầu vào cũng như đầu ra được dự đoán gần đây được đưa vào mô hình, được nhúng, đi qua nhiều khối decoder và tạo ra xác suất đầu ra cho token tiếp theo.
Các mô hình ngôn ngữ lớn (Large Language Models) ngày nay chủ yếu sử dụng các mạng decoder-only làm cơ sở, với một vài sửa đổi nhỏ không thường xuyên. Do tích hợp masked self-attention, các mô hình này chủ yếu tập trung vào việc dự đoán token tiếp theo, điều này đã làm nảy sinh khái niệm prompting.
Theo nghiên cứu, việc mở rộng quy mô các mô hình decoder-only có thể cải thiện đáng kể khả năng hiểu ngôn ngữ và khả năng tổng quát hóa của mạng. Do đó, mọi người có thể vượt trội trong nhiều nhiệm vụ chỉ bằng cách sử dụng các prompt khác nhau. Các mô hình tiền huấn luyện lớn, chẳng hạn như GPT-4 và LLaMA 2, có thể thực hiện các nhiệm vụ như phân loại, tóm tắt, dịch thuật, v.v. bằng cách sử dụng các chỉ dẫn liên quan.
Các mô hình ngôn ngữ lớn, chẳng hạn như các mô hình trong họ GPT, được tiền huấn luyện với mục tiêu Causal Language Modeling. Điều này có nghĩa là mô hình cố gắng dự đoán từ tiếp theo, trong khi cơ chế attention chỉ có thể chú ý đến các token trước đó ở bên trái. Điều này có nghĩa là mô hình chỉ có thể dự đoán token tiếp theo dựa trên ngữ cảnh trước đó và không thể nhìn trộm các token tương lai, tránh gian lận.
gpt2 = AutoModel.from_pretrained("gpt2")
print(gpt2)
GPT2Model(
(wte): Embedding(50257, 768)
(wpe): Embedding(1024, 768)
(drop): Dropout(p=0.1, inplace=False)
(h): ModuleList(
(0-11): 12 x GPT2Block(
(ln_1): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(attn): GPT2Attention(
(c_attn): Conv1D()
(c_proj): Conv1D()
(attn_dropout): Dropout(p=0.1, inplace=False)
(resid_dropout): Dropout(p=0.1, inplace=False)
)
(ln_2): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
(mlp): GPT2MLP(
(c_fc): Conv1D()
(c_proj): Conv1D()
(act): NewGELUActivation()
(dropout): Dropout(p=0.1, inplace=False)
)
)
)
(ln_f): LayerNorm((768,), eps=1e-05, elementwise_affine=True)
)
Bằng cách xem xét kiến trúc, bạn sẽ khám phá ra khối decoder transformer thông thường mà không có lớp cross-attention. Họ GPT cũng sử dụng các lớp tuyến tính riêng biệt (Conv1D) để chuyển vị trọng số. (Xin lưu ý rằng điều này không nên nhầm lẫn với lớp tích chập của PyTorch!) Lựa chọn thiết kế này là duy nhất đối với OpenAI; các mô hình ngôn ngữ nguồn mở lớn khác sử dụng lớp tuyến tính thông thường. Mã được cung cấp cho thấy cách pipeline có thể kết hợp mô hình GPT-2 để tạo văn bản. Nó tạo ra bốn khả năng để hoàn thành câu “This movie was a very.”
generator = pipeline(model="gpt2")
output = generator("This movie was a very", do_sample=True, top_p=0.95, num_return_sequences=4, max_new_tokens=50, return_full_text=False)
for item in output:
print(">", item['generated_text'])
> hard thing to make, but this movie is still one of the most amazing
shows I've seen in years. You know, it's sort of fun for a couple of
decades to watch, and all that stuff, but one thing's for sure —
> special thing and that's what really really made this movie special,"
said Kiefer Sutherland, who co-wrote and directed the film's cinematography.
"A lot of times things in our lives get passed on from one generation to
another, whether
> good, good effort and I have no doubt that if it has been released,
I will be very pleased with it."
Read more at the Mirror.
> enjoyable one for the many reasons that I would like to talk about here.
First off, I'm not just talking about the original cast, I'm talking about
the cast members that we've seen before and it would be fair to say that
none of
💡 Xin lưu ý rằng việc chạy mã trên sẽ cho ra các đầu ra khác nhau do tính ngẫu nhiên liên quan đến quá trình tạo sinh.
The Generative Pre-trained Transformer (GPT) Architecture
OpenAI Generative Pre-trained Transformer (GPT) là một mô hình ngôn ngữ dựa trên kiến trúc transformer. Thành phần ‘transformer’ trong tên của nó liên quan đến thiết kế transformer, được giới thiệu trong bài nghiên cứu của Vaswani và cộng sự, “Attention is All You Need.”
Khác với các mạng nơ-ron hồi quy truyền thống (Recurrent Neural Networks - RNNs), vốn gặp khó khăn với sự phụ thuộc dài hạn do vấn đề gradient biến mất (vanishing gradient problem), các mạng Long Short-Term Memory (LSTMs) giới thiệu một kiến trúc phức tạp hơn với các ô nhớ (memory cells) có thể duy trì thông tin qua các chuỗi dài hơn. Tuy nhiên, cả RNNs và LSTMs vẫn dựa vào xử lý tuần tự (sequential processing). Ngược lại, kiến trúc transformer loại bỏ tính hồi quy (recurrence) để ưu tiên các quá trình tự chú ý (self-attention), cải thiện đáng kể tốc độ và khả năng mở rộng (scalability) bằng cách cho phép xử lý song song (parallel processing) dữ liệu chuỗi.
The GPT Architecture
Dòng mô hình GPT chứa các mô hình chỉ có bộ giải mã (decoder-only) với cơ chế tự chú ý (self-attention) kết hợp với mạng truyền thẳng (feed-forward network) được liên kết đầy đủ theo vị trí (position-wise fully linked) trong mỗi lớp của kiến trúc.
Cơ chế tự chú ý tích vô hướng được chia tỷ lệ (scaled dot-product attention) là một kỹ thuật tự chú ý cho phép mô hình gán điểm số quan trọng cho mỗi từ trong chuỗi đầu vào trong khi tạo ra các từ tiếp theo. Ngoài ra, “mặt nạ” (masking) trong quá trình tự chú ý là một yếu tố nổi bật của kiến trúc này. Việc tạo mặt nạ này thu hẹp sự tập trung của mô hình, ngăn cản nó xem xét các vị trí hoặc từ nhất định trong chuỗi.
Hình minh họa các token được chú ý bởi tự chú ý có mặt nạ tại một dấu thời gian cụ thể. Toàn bộ chuỗi được chuyển đến mô hình, nhưng mô hình tại bước thời gian 5 cố gắng dự đoán token tiếp theo bằng cách chỉ xem xét các token đã được tạo trước đó, che giấu các token tương lai. Điều này ngăn mô hình “gian lận” bằng cách dự đoán và tận dụng các token tương lai.
Đoạn mã sau triển khai cơ chế “tự chú ý có mặt nạ” (masked self-attention):
import numpy as np
def self_attention(query, key, value, mask=None):
# Tính toán điểm số chú ý (Compute attention scores)
scores = np.dot(query, key.T)
if mask is not None:
# Áp dụng mặt nạ bằng cách đặt các vị trí được che giấu thành một giá trị âm lớn (Apply mask by setting masked positions to a large negative value)
scores = scores + mask * -1e9
# Áp dụng softmax để lấy trọng số chú ý (Apply softmax to obtain attention weights)
attention_weights = np.exp(scores) / np.sum(np.exp(scores), axis=-1,
keepdims=True)
# Tính toán tổng trọng số của các vector giá trị (Compute weighted sum of value vectors)
output = np.dot(attention_weights, value)
return output
Bước đầu tiên liên quan đến việc tạo một vector Query, Key và Value cho mỗi từ trong chuỗi đầu vào. Điều này đạt được thông qua các phép biến đổi tuyến tính riêng biệt được áp dụng cho vector đầu vào. Về cơ bản, đó là một lớp tuyến tính truyền thẳng đơn giản mà mô hình thu được thông qua quá trình huấn luyện.
Tiếp theo, mô hình tính toán điểm số chú ý bằng cách tính tích vô hướng giữa vector Query của mỗi từ và vector Key của mọi từ khác. Để đảm bảo mô hình bỏ qua các cụm từ nhất định trong quá trình chú ý, mặt nạ được áp dụng bằng cách gán các giá trị âm đáng kể cho điểm số ở các vị trí cụ thể. Hàm SoftMax sau đó biến đổi các điểm số chú ý này thành xác suất, vô hiệu hóa tác động của các giá trị âm đáng kể. Sau đó, mỗi vector Value được nhân với trọng số tương ứng của nó và được tổng hợp để tạo ra đầu ra cho cơ chế tự chú ý có mặt nạ cho mỗi từ.
Mặc dù mô tả này minh họa chức năng của một đầu tự chú ý đơn lẻ (single self-attention head), điều quan trọng cần lưu ý là mỗi lớp thường chứa nhiều đầu (multiple heads), với số lượng thay đổi từ 16 đến 32, tùy thuộc vào kiến trúc mô hình cụ thể. Các đầu này hoạt động đồng thời, tăng cường đáng kể khả năng phân tích và giải thích dữ liệu của mô hình.
Causal Language Modeling
Các Mô hình Ngôn ngữ Lớn (Large Language Models - LLMs) sử dụng học tự giám sát (self-supervised learning) để tiền huấn luyện (pre-training) trên dữ liệu với ground truth mềm (soft ground truth), loại bỏ nhu cầu về nhãn rõ ràng (explicit labels) cho mô hình trong quá trình huấn luyện. Dữ liệu này có thể là văn bản mà chúng ta đã biết các từ tiếp theo để dự đoán hoặc, ví dụ, hình ảnh có chú thích lấy từ Instagram. Điều này cho phép LLMs thu nhận kiến thức một cách độc lập. Ví dụ, việc sử dụng học có giám sát (supervised learning) để huấn luyện một mô hình tóm tắt đòi hỏi phải sử dụng các bài báo và bản tóm tắt của chúng làm tài liệu tham khảo huấn luyện. Mặt khác, LLMs sử dụng mục tiêu mô hình hóa ngôn ngữ nhân quả để học từ dữ liệu văn bản mà không yêu cầu nhãn do con người cung cấp. Tại sao nó được gọi là “nhân quả”? Bởi vì dự đoán ở mỗi bước hoàn toàn dựa trên các bước trước đó trong chuỗi chứ không phải các bước tương lai.
💡 Quy trình bao gồm cung cấp cho mô hình một phần văn bản và hướng dẫn nó dự đoán từ tiếp theo.
Sau khi mô hình dự đoán một từ, nó được nối (concatenated) với đầu vào gốc và được trình bày cho mô hình để dự đoán token tiếp theo. Quá trình lặp đi lặp lại này tiếp tục, với mỗi token mới được tạo được đưa vào mạng. Trong suốt quá trình tiền huấn luyện, mô hình dần dần thu được sự hiểu biết sâu rộng về ngôn ngữ và ngữ pháp. Sau đó, mô hình tiền huấn luyện có thể được tinh chỉnh (fine-tuned) bằng phương pháp có giám sát cho các nhiệm vụ khác nhau hoặc các miền cụ thể.
Phương pháp này mang lại lợi thế so với các phương pháp khác bằng cách mô phỏng chặt chẽ hơn cách con người viết và nói tự nhiên. Không giống như mô hình hóa ngôn ngữ được che giấu (masked language modeling), vốn đưa các token bị che giấu vào đầu vào, mô hình hóa ngôn ngữ nhân quả xây dựng các câu một từ tại một thời điểm một cách tuần tự. Sự khác biệt này đảm bảo mô hình vẫn hiệu quả khi xử lý văn bản thực tế không bao gồm các token bị che giấu.
Ngoài ra, kỹ thuật này cho phép sử dụng một loạt nội dung chất lượng cao do con người tạo ra từ các nguồn như sách, Wikipedia và trang web tin tức. Các tập dữ liệu nổi tiếng có thể dễ dàng truy cập từ các nền tảng như Hugging Face Hub.
MinGPT
Có nhiều cách triển khai kiến trúc GPT khác nhau, mỗi cách được điều chỉnh cho các mục đích cụ thể. Mặc dù chúng ta sẽ đề cập đến các thư viện thay thế phù hợp hơn cho môi trường sản xuất trong các chương sắp tới, nhưng cũng đáng chú ý là phiên bản gọn nhẹ của mô hình GPT-2 của OpenAI, được phát triển bởi Andrej Karpathy, có tên là minGPT.
Karpathy mô tả minGPT như một công cụ giáo dục được thiết kế để đơn giản hóa cấu trúc GPT. Đáng chú ý, nó được cô đọng trong khoảng 300 dòng mã và sử dụng thư viện PyTorch. Sự đơn giản của nó làm cho nó trở thành một nguồn tài liệu tuyệt vời để hiểu sâu hơn về hoạt động bên trong của các mô hình như vậy. Mã được mô tả kỹ lưỡng, cung cấp giải thích rõ ràng về các quy trình liên quan.
Ba tệp chính rất quan trọng trong kho lưu trữ minGPT. Kiến trúc được trình bày chi tiết trong tệp model.py. Token hóa được xử lý thông qua tệp bpe.py, sử dụng kỹ thuật Mã hóa cặp byte (Byte Pair Encoding - BPE). Tệp trainer.py chứa một vòng lặp huấn luyện chung (generic training loop) có thể được sử dụng cho bất kỳ mạng nơ-ron nào, bao gồm cả mô hình GPT. Hơn nữa, notebook demo.ipynb hiển thị toàn bộ ứng dụng của mã, bao gồm cả quy trình suy luận (inference process). Mã này đủ nhẹ để chạy trên MacBook Air, cho phép thử nghiệm dễ dàng trên PC cục bộ. Những người thích giải pháp dựa trên đám mây có thể fork kho lưu trữ và sử dụng nó trên các nền tảng như Colab.
Introduction to Large Multimodal Models
Các mô hình đa phương thức (multimodal models) được thiết kế để xử lý và diễn giải các loại dữ liệu đa dạng, hay còn gọi là các phương thức (modalities), chẳng hạn như văn bản (text), hình ảnh (images), âm thanh (audio) và video. Cách tiếp cận tích hợp này cho phép phân tích toàn diện hơn so với các mô hình chỉ giới hạn ở một loại dữ liệu duy nhất, chẳng hạn như văn bản trong các LLMs truyền thống. Ví dụ, việc bổ sung các lời nhắc văn bản (text prompts) bằng đầu vào âm thanh (audio inputs) hoặc hình ảnh (visual inputs) cho phép các mô hình này hiểu được sự biểu diễn thông tin phức tạp hơn, xem xét các yếu tố như sắc thái giọng nói (vocal nuances) hoặc bối cảnh trực quan (visual contexts).
Sự gia tăng quan tâm gần đây đối với LLMs đã tự nhiên mở rộng sang việc khám phá tiềm năng của LMMs, nhằm mục đích tạo ra các trợ lý đa năng (versatile general-purpose assistants) có khả năng xử lý một loạt các nhiệm vụ.
Common Architectures and Training Objectives
Kiến trúc Phổ biến và Mục tiêu Huấn luyện
Theo định nghĩa, các mô hình đa phương thức (multimodal models) được thiết kế để xử lý nhiều phương thức đầu vào (input modalities), chẳng hạn như văn bản (text), hình ảnh (images) và video, và tạo ra đầu ra ở nhiều phương thức. Tuy nhiên, một tập hợp con đáng kể của các mô hình ngôn ngữ lớn đa phương thức (LMMs) phổ biến hiện nay chủ yếu chấp nhận đầu vào hình ảnh và chỉ có thể tạo ra đầu ra văn bản.
Những LMM chuyên biệt này thường sử dụng các mô hình thị giác (vision models) hoặc mô hình ngôn ngữ (language models) quy mô lớn được huấn luyện trước (pre-trained) làm nền tảng. Chúng được gọi là ‘Image-to-Text Generative Models’ hoặc mô hình ngôn ngữ thị giác (visual language models - VLMs). Chúng thường thực hiện các nhiệm vụ hiểu hình ảnh như trả lời câu hỏi (question answering) và chú thích hình ảnh (image captioning). Ví dụ bao gồm GIT của Microsoft, BLIP2 của SalesForce và Flamingo của DeepMind.
Kiến trúc Mô hình
Trong kiến trúc của các mô hình này, một bộ mã hóa hình ảnh (image encoder) được sử dụng để trích xuất các đặc trưng thị giác (visual features), tiếp theo là một mô hình ngôn ngữ tiêu chuẩn (standard language model) tạo ra một chuỗi văn bản. Bộ mã hóa hình ảnh có thể dựa trên Mạng nơ-ron tích chập (Convolutional Neural Networks - CNNs), ví dụ như ResNet, hoặc nó có thể sử dụng kiến trúc dựa trên transformer, như Vision Transformer (ViT).
Có hai phương pháp chính để huấn luyện: xây dựng mô hình từ đầu hoặc sử dụng các mô hình được huấn luyện trước. Phương pháp thứ hai thường được ưa chuộng trong các mô hình tiên tiến. Một ví dụ đáng chú ý là bộ mã hóa hình ảnh được huấn luyện trước từ mô hình CLIP của OpenAI. Về mô hình ngôn ngữ, có nhiều lựa chọn được huấn luyện trước, bao gồm OPT, LLaMA 2 của Meta hoặc FlanT5 của Google, là những mô hình được huấn luyện theo hướng dẫn (instruction-trained).
Một số mô hình, như BLIP2, kết hợp một yếu tố mới: một mô-đun kết nối nhẹ, có thể huấn luyện được (trainable, lightweight connection module) kết nối các phương thức thị giác và ngôn ngữ. Phương pháp này, chỉ huấn luyện mô-đun kết nối, tiết kiệm chi phí và thời gian. Hơn nữa, nó thể hiện hiệu suất zero-shot mạnh mẽ trong các nhiệm vụ hiểu hình ảnh.
Mục tiêu Huấn luyện
LMMs được huấn luyện bằng cách sử dụng hàm mất mát tự hồi quy (auto-regressive loss function) áp dụng cho các token đầu ra (output tokens). Khái niệm ‘token hình ảnh’ (picture tokens), tương tự như token hóa văn bản (text tokenization), được giới thiệu khi sử dụng kiến trúc Vision Transformer. Bằng cách này, văn bản có thể được phân tách thành các đơn vị nhỏ hơn như câu, từ hoặc từ con (sub-words) để xử lý nhanh hơn, và hình ảnh có thể được phân đoạn thành các mảng nhỏ, không chồng chéo được gọi là ‘image tokens’.
Trong kiến trúc Transformer được sử dụng bởi LMMs, các cơ chế chú ý cụ thể (specific attention mechanisms) là chìa khóa. Ở đây, các token hình ảnh có thể ‘chú ý’ (attend) lẫn nhau, ảnh hưởng đến cách mỗi token được biểu diễn trong mô hình. Hơn nữa, việc tạo ra mỗi token văn bản bị ảnh hưởng bởi tất cả các token hình ảnh và văn bản đã được tạo ra trước đó.
Differences in Training Schemes
Mặc dù có cùng mục tiêu huấn luyện, các mô hình ngôn ngữ đa phương thức (LMMs) riêng biệt có những khác biệt đáng kể trong chiến lược huấn luyện của chúng. Để huấn luyện, hầu hết các mô hình, chẳng hạn như GIT và BLIP2, chỉ sử dụng các cặp hình ảnh-văn bản (image-text pairs). Phương pháp này thiết lập hiệu quả các liên kết giữa biểu diễn văn bản và hình ảnh, nhưng đòi hỏi một tập dữ liệu lớn, được tuyển chọn kỹ lưỡng các cặp hình ảnh-văn bản.
Mặt khác, Flamingo được thiết kế để chấp nhận một lời nhắc đa phương thức (multimodal prompt), có thể bao gồm sự kết hợp của hình ảnh, video và văn bản, và tạo ra các phản hồi văn bản ở định dạng mở (open-ended format). Khả năng này cho phép nó thực hiện hiệu quả các nhiệm vụ, chẳng hạn như chú thích hình ảnh (image captioning) và trả lời câu hỏi trực quan (visual question answering). Mô hình Flamingo kết hợp các tiến bộ kiến trúc cho phép huấn luyện với dữ liệu web không được gắn nhãn (unlabeled web data). Nó xử lý văn bản và hình ảnh được trích xuất từ HTML của 43 triệu trang web. Ngoài ra, mô hình đánh giá vị trí của hình ảnh liên quan đến văn bản, sử dụng các vị trí tương đối của các phần tử văn bản và hình ảnh trong Mô hình Đối tượng Tài liệu (Document Object Model - DOM).
Việc tích hợp các phương thức khác nhau được thực hiện thông qua một loạt các bước. Ban đầu, một mô-đun Perceiver Resampler xử lý các đặc trưng không gian-thời gian (spatiotemporal features) từ dữ liệu trực quan, như hình ảnh hoặc video, mà bộ mã hóa thị giác (Vision Encoder) được huấn luyện trước xử lý. Perceiver sau đó tạo ra một số lượng token hình ảnh cố định (fixed number of visual tokens).
Những token hình ảnh này điều kiện hóa (condition) một mô hình ngôn ngữ đóng băng (frozen language model), một mô hình ngôn ngữ được huấn luyện trước sẽ không nhận được cập nhật trong quá trình này. Việc điều kiện hóa được thực hiện bằng cách thêm các lớp chú ý chéo (cross-attention layers) được khởi tạo mới kết hợp với các lớp hiện có của mô hình ngôn ngữ. Không giống như các thành phần khác, các lớp này không tĩnh và được cập nhật trong quá trình huấn luyện. Mặc dù kiến trúc này có thể kém hiệu quả hơn do số lượng tham số cần huấn luyện tăng lên so với BLIP2, nhưng nó cung cấp các phương tiện phức tạp hơn để mô hình ngôn ngữ tích hợp và diễn giải thông tin trực quan.
Học trong ngữ cảnh ít ví dụ (Few-shot In-Context-Learning)
Kiến trúc linh hoạt của Flamingo cho phép nó được huấn luyện với các lời nhắc đa phương thức xen kẽ văn bản với token hình ảnh. Điều này cho phép mô hình thể hiện các khả năng mới nổi, chẳng hạn như học trong ngữ cảnh ít ví dụ, tương tự như GPT-3.
Open-sourcing Flamingo
Như được báo cáo trong bài báo nghiên cứu của mình, những tiến bộ được thể hiện trong mô hình Flamingo đánh dấu một bước tiến quan trọng trong các Mô hình Ngôn ngữ Đa phương thức (Language-Multimodal Models - LMMs). Mặc dù đạt được những thành tựu này, DeepMind vẫn chưa phát hành mô hình Flamingo để sử dụng công khai.
Để giải quyết vấn đề này, nhóm tại Hugging Face đã khởi xướng phát triển một phiên bản mã nguồn mở của Flamingo có tên là IDEFICS. Phiên bản này được xây dựng hoàn toàn bằng các tài nguyên có sẵn công khai, kết hợp các yếu tố như mô hình LLaMA v1 và OpenCLIP. IDEFICS được trình bày trong hai phiên bản: biến thể ‘base’ và ‘instructed’, mỗi phiên bản có hai kích thước, 9 và 80 tỷ tham số. Hiệu suất của IDEFICS có thể so sánh với mô hình Flamingo.
Để huấn luyện các mô hình này, nhóm Hugging Face đã sử dụng kết hợp các tập dữ liệu có thể truy cập công khai, bao gồm Wikipedia, Tập dữ liệu Đa phương thức Công khai (Public Multimodal Dataset) và LAION. Ngoài ra, họ đã biên soạn một tập dữ liệu mới có tên là OBELICS, một tập dữ liệu 115 tỷ token có 141 triệu tài liệu hình ảnh-văn bản có nguồn gốc từ web, với 353 triệu hình ảnh. Tập dữ liệu này phản ánh tập dữ liệu được DeepMind mô tả cho mô hình Flamingo.
Ngoài IDEFICS, một bản sao mã nguồn mở khác của Flamingo, được gọi là Open Flamingo, cũng có sẵn công khai. Mô hình 9 tỷ tham số thể hiện hiệu suất tương tự như Flamingo. Liên kết đến playground của IDEFICS có thể truy cập tại towardsai.net/book.
Instruction-tuned LMMs
Như đã được chứng minh bởi khả năng emergent abilities của GPT-3 với few-shot prompting, nơi mô hình có thể giải quyết các nhiệm vụ mà nó chưa từng thấy trong quá trình huấn luyện, đã có sự quan tâm ngày càng tăng đối với instruction-fine-tuned LMMs. Bằng cách cho phép các mô hình được instruction-tuned, chúng ta có thể mong đợi các mô hình này thực hiện một tập hợp các nhiệm vụ rộng hơn và phù hợp hơn với ý định của con người. Điều này phù hợp với công việc được thực hiện bởi OpenAI với InstructGPT và gần đây hơn là GPT-4. Họ đã nhấn mạnh khả năng của phiên bản mới nhất của mình, mô hình “GPT-4 with vision”, có thể xử lý các hướng dẫn bằng cách sử dụng đầu vào hình ảnh. Sự tiến bộ này được trình bày chi tiết trong GPT-4 technical report và GPT-4V(ision) System Card.
Ví dụ về prompt minh họa khả năng đầu vào hình ảnh của GPT-4. Prompt yêu cầu hiểu hình ảnh. Từ GPT-4 Technical Report.
Sau khi phát hành multimodal GPT-4 của OpenAI, đã có sự gia tăng đáng kể trong nghiên cứu và phát triển của instruction-tuned Language-Multimodal Models (LMMs). Một số phòng thí nghiệm nghiên cứu đã đóng góp vào lĩnh vực đang phát triển này với các mô hình của họ, chẳng hạn như LLaVA, MiniGPT-4 và InstructBlip. Các mô hình này có những điểm tương đồng về kiến trúc với các LMMs trước đó, nhưng được huấn luyện rõ ràng trên các tập dữ liệu được thiết kế để tuân theo hướng dẫn (instruction-following).
Khám phá LLaVA - Một LMM được Instruction-tuned
LLaVA, một instruction-tuned Language-Multimodal Model (LMM), có kiến trúc mạng tương tự như các mô hình đã thảo luận trước đó. Nó tích hợp một CLIP visual encoder được huấn luyện trước với mô hình ngôn ngữ Vicuna. Một lớp tuyến tính đơn giản, hoạt động như một projection matrix, tạo điều kiện kết nối giữa các thành phần hình ảnh và ngôn ngữ. Ma trận này, được gọi là W, được thiết kế để chuyển đổi các đặc trưng hình ảnh thành các language embedding tokens. Các tokens này được khớp về chiều với không gian word embedding của mô hình ngôn ngữ, đảm bảo sự tích hợp liền mạch.
Trong thiết kế LLaVA, các nhà nghiên cứu đã chọn các lớp linear projection mới này, nhẹ hơn mô-đun kết nối Q-Former được sử dụng trong BLIP2 và các lớp perceiver resampler và cross-attention của Flamingo. Sự lựa chọn này phản ánh sự tập trung vào hiệu quả và sự đơn giản trong kiến trúc của mô hình.
Mô hình này được huấn luyện bằng quy trình instruction-tuning hai giai đoạn. Ban đầu, projection matrix được huấn luyện trước trên một tập con của tập dữ liệu CC3M bao gồm các cặp hình ảnh-chú thích. Sau đó, mô hình được fine-tuned end-to-end. Trong giai đoạn này, projection matrix và mô hình ngôn ngữ được huấn luyện trên một tập dữ liệu multimodal instruction-following được xây dựng đặc biệt cho các ứng dụng hướng đến người dùng hàng ngày.
Ngoài ra, các tác giả sử dụng GPT-4 để tạo ra một tập dữ liệu tổng hợp với các hướng dẫn đa phương thức. Điều này được thực hiện bằng cách sử dụng dữ liệu cặp hình ảnh có sẵn rộng rãi. GPT-4 được trình bày các biểu diễn tượng trưng của hình ảnh trong quá trình xây dựng tập dữ liệu, bao gồm các chú thích và tọa độ của các bounding boxes. Các biểu diễn tập dữ liệu COCO này được sử dụng làm prompts để GPT-4 tạo ra các mẫu huấn luyện.
Kỹ thuật này tạo ra ba loại mẫu huấn luyện: các cuộc trò chuyện hỏi-đáp, mô tả chi tiết và các bài toán và câu trả lời lý luận phức tạp. Tổng số mẫu huấn luyện được tạo ra bởi kỹ thuật này là 158.000.
Mô hình LLaVA chứng minh hiệu quả của việc visual instruction tuning bằng cách sử dụng GPT-4 chỉ bằng ngôn ngữ. Họ chứng minh khả năng của nó bằng cách kích hoạt mô hình với cùng một truy vấn và hình ảnh như trong báo cáo GPT-4. Các tác giả cũng mô tả một SOTA mới bằng cách fine-tuning ScienceQA, một benchmark với 21k câu hỏi trắc nghiệm đa phương thức với sự đa dạng miền đáng kể trên ba môn học, 26 chủ đề, 127 danh mục và 379 khả năng.
Beyond Vision and Language
Trong những tháng gần đây, các mô hình tạo sinh hình ảnh thành văn bản (image-to-text generative models) đã thống trị môi trường Large Multimodal Model (LMM). Tuy nhiên, các mô hình khác bao gồm các phương thức (modalities) khác ngoài vision và language. Ví dụ: PandaGPT được thiết kế để xử lý bất kỳ loại dữ liệu đầu vào nào, nhờ tích hợp với ImageBind encoder. Cũng có SpeechGPT, một mô hình tích hợp dữ liệu văn bản và giọng nói và tạo ra giọng nói cùng với văn bản. Ngoài ra, NExT-GPT là một mô hình đa năng có khả năng nhận và tạo ra đầu ra ở bất kỳ phương thức nào.
HuggingGPT là một giải pháp sáng tạo hoạt động với nền tảng Hugging Face. Bộ điều khiển trung tâm của nó là một Large Language Model (LLM). LLM này xác định mô hình Hugging Face nào phù hợp nhất cho một nhiệm vụ, chọn mô hình đó và sau đó trả về đầu ra của mô hình.
Cho dù chúng ta đang xem xét LLMs, LMMs và tất cả các loại mô hình mà chúng ta vừa đề cập, một câu hỏi vẫn còn: chúng ta nên sử dụng mô hình độc quyền (proprietary models), mô hình mở (open models) hay mô hình mã nguồn mở (open-source models)?
Để trả lời câu hỏi này, trước tiên chúng ta cần hiểu từng loại mô hình này.
Proprietary vs. Open Models vs. Open-Source Language Models
Mô hình độc quyền (Proprietary), Mô hình mở (Open Models) và Mô hình ngôn ngữ mã nguồn mở (Open-Source Language Models)
Các mô hình ngôn ngữ có thể được phân loại thành ba loại: proprietary, open models, và open-source models. Mô hình proprietary, như GPT-4 của OpenAI và Claude 3 Opus của Anthropic, chỉ có thể truy cập thông qua paid APIs hoặc giao diện web. Open models, như LLaMA 2 của Meta hoặc Mixtral 8x7B của Mistral, có kiến trúc mô hình và weights công khai trên internet. Cuối cùng, open-source models như OLMo của AI2 cung cấp đầy đủ dữ liệu tiền huấn luyện (pre-training data), mã huấn luyện (training code), mã đánh giá (evaluation code) và model weights, cho phép các học giả và nhà nghiên cứu tái tạo và phân tích mô hình một cách chuyên sâu.
Mô hình proprietary thường vượt trội hơn các lựa chọn mở vì các công ty muốn duy trì lợi thế cạnh tranh của họ. Chúng có xu hướng lớn hơn và trải qua quá trình fine-tuning mở rộng. Tính đến tháng 4 năm 2024, các mô hình proprietary liên tục dẫn đầu bảng xếp hạng LLM trên bảng xếp hạng LYMSYS Chatbot Arena. Đấu trường này liên tục thu thập phiếu bầu ưu tiên của con người để xếp hạng LLM bằng hệ thống xếp hạng Elo.
Một số công ty cung cấp mô hình proprietary, như OpenAI, cho phép fine-tuning cho LLM của họ, cho phép người dùng tối ưu hóa hiệu suất tác vụ cho các trường hợp sử dụng cụ thể và trong các chính sách sử dụng được xác định. Các chính sách nêu rõ rằng người dùng phải tôn trọng các biện pháp bảo vệ và không tham gia vào các hoạt động bất hợp pháp. Open weights và open-source models cho phép tùy chỉnh hoàn toàn nhưng yêu cầu triển khai rộng rãi và tài nguyên điện toán của riêng bạn để chạy. Khi kiểm tra độ tin cậy, thời gian ngừng dịch vụ (service downtime) phải được xem xét trong các mô hình proprietary, điều này có thể làm gián đoạn quyền truy cập của người dùng.
Khi lựa chọn giữa mô hình AI proprietary và open, điều quan trọng là phải xem xét các yếu tố như nhu cầu của người dùng hoặc tổ chức, tài nguyên có sẵn và chi phí. Đối với các nhà phát triển, nên bắt đầu với các mô hình proprietary đáng tin cậy trong giai đoạn phát triển ban đầu và chỉ xem xét các lựa chọn thay thế mã nguồn mở sau này khi sản phẩm đã đạt được sức hút trên thị trường. Điều này là do tài nguyên cần thiết để triển khai mô hình mở cao hơn.
Sau đây là danh sách các mô hình proprietary và open đáng chú ý tính đến tháng 4 năm 2024. Các liên kết tài liệu có thể truy cập tại towardsai.net/book.
Cohere LLMs
Cohere là một nền tảng cho phép các nhà phát triển và doanh nghiệp tạo các ứng dụng được hỗ trợ bởi Language Models (LLMs). Các mô hình LLM do Cohere cung cấp được phân loại thành ba loại chính - “Command,” “Rerank,” và “Embed.” Danh mục “Command” dành cho các tác vụ trò chuyện và ngữ cảnh dài, “Rerank” dành cho việc sắp xếp các đầu vào văn bản theo mức độ liên quan ngữ nghĩa và “Embed” dành cho việc tạo text embeddings.
Mô hình Command R mới nhất của Cohere tương tự như LLM của OpenAI và được huấn luyện bằng dữ liệu có nguồn gốc từ internet rộng lớn. Nó được tối ưu hóa cho các hệ thống retrieval-augmented generation (RAG) và các tác vụ sử dụng công cụ (tool-use tasks). Mô hình Command R có độ dài ngữ cảnh là 128.000 tokens và có khả năng cao trong mười ngôn ngữ chính.
Việc phát triển các mô hình này đang diễn ra liên tục, với các bản cập nhật và cải tiến mới được phát hành thường xuyên.
Người dùng quan tâm đến việc khám phá các mô hình của Cohere có thể đăng ký tài khoản Cohere và nhận khóa API dùng thử miễn phí. Khóa dùng thử này không có giới hạn tín dụng hoặc thời gian; tuy nhiên, các lệnh gọi API bị giới hạn ở 100 mỗi phút, thường đủ cho các dự án thử nghiệm.
Để lưu trữ an toàn khóa API của bạn, bạn nên lưu nó trong tệp .env, như minh họa dưới đây:
COHERE_API_KEY="<YOUR-COHERE-API-KEY>"
Sau đó, cài đặt cohere Python SDK bằng lệnh này.
pip install cohere
Bây giờ bạn có thể tạo văn bản với Cohere như sau.
import cohere
co = cohere.Client('<<apiKey>>')
response = co.chat(
chat_history=[
{"role": "USER", "message": "Who discovered gravity?"},
{"role": "CHATBOT", "message": "The man who is widely credited with discovering gravity is Sir Isaac Newton"}
],
message="What year was he born?", # perform web search before answering the question. You can also use your own custom connector.
connectors=[{"id": "web-search"}]
)
print(response)
GPT-3.5 và GPT-4 của OpenAI
OpenAI hiện cung cấp hai Large Language Models tiên tiến, GPT-3.5 và GPT-4, mỗi mô hình đi kèm với các phiên bản “Turbo” nhanh hơn của chúng.
GPT-3.5, được biết đến với hiệu quả chi phí và khả năng tạo ra văn bản giống con người, có đủ khả năng cho các ứng dụng trò chuyện cơ bản và các tác vụ ngôn ngữ tạo sinh khác. Biến thể Turbo nhanh hơn và rẻ hơn, khiến nó trở thành lựa chọn tuyệt vời cho các nhà phát triển tìm kiếm LLM rẻ nhưng hiệu suất cao. Mặc dù được tối ưu hóa chủ yếu cho tiếng Anh, nhưng nó mang lại hiệu suất đáng khen ngợi trong nhiều ngôn ngữ khác nhau.
OpenAI cung cấp Language Model Models (LLMs) của mình thông qua paid APIs. Azure Chat Solution Accelerator cũng sử dụng Azure Open AI Service để tích hợp các mô hình này trong cài đặt doanh nghiệp, tập trung vào GPT-3.5. Nền tảng này tăng cường kiểm duyệt và an toàn, cho phép các tổ chức thiết lập môi trường trò chuyện an toàn và riêng tư trong Azure Subscription của họ. Nó cung cấp trải nghiệm người dùng tùy chỉnh, ưu tiên quyền riêng tư và quyền kiểm soát trong phạm vi thuê bao Azure của tổ chức.
OpenAI cũng cung cấp GPT-4 và GPT-4 Turbo, đại diện cho đỉnh cao thành tựu của OpenAI trong LLM và đa phương thức mô hình (model multimodality). Không giống như những người tiền nhiệm của nó, GPT-4 Turbo có thể xử lý đầu vào văn bản và hình ảnh, mặc dù nó chỉ tạo ra đầu ra văn bản. Dòng GPT-4 hiện là trạng thái tiên tiến về hiệu suất mô hình lớn.
Giống như tất cả các mô hình OpenAI hiện tại, các thông số và thông số kỹ thuật huấn luyện của GPT-4 vẫn được giữ bí mật. Tuy nhiên, tính đa phương thức của nó đại diện cho một bước đột phá quan trọng trong phát triển AI, cung cấp khả năng vô song để hiểu và tạo nội dung trên nhiều định dạng khác nhau.
Mô hình Claude 3 của Anthropic
Claude 3 là dòng Large Language Models (LLMs) mới nhất của Anthropic, thiết lập các tiêu chuẩn ngành mới trên một loạt các nhiệm vụ nhận thức. Dòng này bao gồm ba mô hình hiện đại: Claude 3 Haiku, Claude 3 Sonnet và Claude 3 Opus. Mỗi mô hình kế tiếp cung cấp hiệu suất ngày càng mạnh mẽ, cho phép người dùng chọn sự cân bằng tốt nhất giữa hiệu suất, tốc độ và chi phí cho ứng dụng cụ thể của họ.
Tính đến tháng 4 năm 2024, Claude 3 Opus được xếp hạng trong số các mô hình tốt nhất trên Bảng xếp hạng LMSYS Chatbot Arena.
Tất cả các mô hình Claude 3 đều có cửa sổ ngữ cảnh 200K token, có khả năng xử lý đầu vào lên đến 1 triệu tokens. Cửa sổ 1M token sẽ có sẵn cho một số khách hàng chọn lọc trong thời gian ngắn. Các mô hình thể hiện khả năng tăng cường trong phân tích, dự báo, tạo nội dung sắc thái, tạo mã và trò chuyện bằng các ngôn ngữ không phải tiếng Anh.
Các mô hình Claude 3 kết hợp các kỹ thuật từ Anthropic, chẳng hạn như Constitutional AI, nơi bạn sử dụng mô hình ngôn ngữ với các chỉ thị rõ ràng (hiến pháp) để hướng dẫn mô hình của riêng bạn trong quá trình huấn luyện thay vì dựa vào phản hồi của con người để giảm rủi ro thương hiệu và hướng tới việc hữu ích, trung thực và vô hại. Quá trình tiền phát hành của Anthropic bao gồm “red teaming” đáng kể để đánh giá mức độ
Google DeepMind’s Gemini
Gemini của Google DeepMind, LLM mới nhất của Google, là một mô hình AI tiên tiến và đa năng. Gemini là một mô hình multimodal có thể xử lý nhiều định dạng khác nhau, như text, images, audio, video và code. Điều này cho phép nó thực hiện nhiều task và hiểu các input phức tạp.
Mô hình này có ba phiên bản: Gemini Ultra cho các task phức tạp và hiệu suất tương đương với GPT-4; Gemini Pro, hữu ích cho một loạt các task; và Gemini Nano, một LLM nhỏ gọn cho hiệu quả trên thiết bị (on-device efficiency). Bạn có thể nhận API key để sử dụng và xây dựng các application với Gemini thông qua Google AI Studio hoặc Google Vertex AI. Gần đây, họ cũng đã công bố Gemini Pro 1.5 với context window lên đến 1 triệu tokens, Gemini 1.5 Pro đạt được context window dài nhất trong số các large-scale foundation model cho đến nay.
Meta’s LLaMA 2
LLaMA 2, một LLM state-of-the-art được phát triển bởi Meta AI, đã được công bố công khai vào ngày 18 tháng 7 năm 2023, theo giấy phép mở (open license) cho mục đích nghiên cứu và thương mại.
Ấn phẩm chi tiết 77 trang của Meta phác thảo kiến trúc của LLaMA 2, tạo điều kiện thuận lợi cho việc tái tạo và tùy chỉnh cho các application cụ thể. Được đào tạo trên một dataset mở rộng gồm 2 nghìn tỷ tokens, LLaMA 2 hoạt động ngang bằng với GPT-3.5 theo các human evaluation metrics, thiết lập các tiêu chuẩn mới trong các open-source benchmark.
Có sẵn trong ba kích thước tham số - 7B, 13B và 70B - LLaMA 2 cũng bao gồm các phiên bản được instruction-tuned được gọi là LLaMA-Chat.
Việc fine-tuning của nó sử dụng cả Supervised Fine-Tuning (SFT) và Reinforcement Learning with Human Feedback (RLHF), áp dụng một phương pháp sáng tạo để phân đoạn dữ liệu dựa trên các prompt cho sự an toàn và hữu ích. Đừng lo lắng nếu điều này nghe có vẻ đáng sợ; chúng ta sẽ thảo luận chi tiết về SFT và RLHF trong chương tiếp theo.
Các reward models là chìa khóa cho hiệu suất của nó. LLaMA 2 sử dụng các safety and helpfulness reward models riêng biệt để đánh giá chất lượng phản hồi, đạt được sự cân bằng giữa hai yếu tố này.
LLaMA 2 đã có những đóng góp đáng kể cho lĩnh vực Generative AI, vượt trội so với các mô hình open innovation khác như Falcon hoặc Vicuna về hiệu suất.
Các mô hình LLaMA 2 có sẵn trên Hugging Face Hub. Để kiểm tra mô hình meta-llama/Llama-2-7b-chat-hf, trước tiên bạn phải yêu cầu quyền truy cập bằng cách điền vào biểu mẫu trên trang web của họ.
Bắt đầu bằng cách tải xuống mô hình. Sẽ mất một chút thời gian vì mô hình nặng khoảng 14GB.
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
# download model
model_id = "meta-llama/Llama-2-7b-chat-hf"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
trust_remote_code=True,
torch_dtype=torch.bfloat16
)
Sau đó, chúng ta tạo ra một completion với nó. Bước này tốn thời gian nếu bạn tạo text bằng CPU thay vì GPU!
# generate answer
prompt = "Translate English to French: Configuration files are easy to use!"
inputs = tokenizer(prompt, return_tensors="pt", return_token_type_ids=False)
outputs = model.generate(**inputs, max_new_tokens=100)
# print answer
print(tokenizer.batch_decode(outputs, skip_special_tokens=True)[0])
Falcon
Các mô hình Falcon, được phát triển bởi Technology Innovation Institute (TII) của Abu Dhabi, đã thu hút sự quan tâm đáng kể kể từ khi ra mắt vào tháng 5 năm 2023. Chúng có sẵn theo Apache 2.0 License, cho phép sử dụng cho mục đích thương mại.
Mô hình Falcon-40B đã thể hiện hiệu suất đáng chú ý, vượt trội so với các LLM khác như LLaMA 65B và MPT-7B. Falcon-7B, một biến thể nhỏ hơn khác, cũng được phát hành và được thiết kế để fine-tuning trên phần cứng tiêu dùng. Nó có số lượng layers và embedding dimensions bằng một nửa so với Falcon-40B, giúp nó dễ tiếp cận hơn với nhiều người dùng hơn.
Dataset đào tạo cho các mô hình Falcon, được gọi là “Falcon RefinedWeb dataset,” được tuyển chọn cẩn thận và có lợi cho các multimodal applications, duy trì các liên kết và alternative texts cho images. Dataset này, kết hợp với các corpora được tuyển chọn khác, chiếm 75% dữ liệu pre-training cho các mô hình Falcon. Mặc dù chủ yếu tập trung vào tiếng Anh, các phiên bản như “RefinedWeb-Europe” mở rộng phạm vi bao gồm một số ngôn ngữ châu Âu.
Các phiên bản instruct của Falcon-40B và Falcon-7B được fine-tuned trên hỗn hợp các chat and instruct datasets từ các nguồn như GPT4all và GPTeacher, cho thấy hiệu suất thậm chí còn tốt hơn.
Các mô hình Falcon có thể được tìm thấy trên Hugging Face Hub. Trong ví dụ này, chúng ta kiểm tra mô hình tiiuae/falcon-7b-instruct. Mã tương tự được sử dụng cho mô hình LLaMA có thể được áp dụng ở đây bằng cách thay đổi model_id.
model_id = "tiiuae/falcon-7b-instruct"
Dolly
Dolly là một Large Language Model (LLM) open-source được phát triển bởi Databricks. Ban đầu được ra mắt với tên gọi Dolly 1.0, nó thể hiện khả năng tương tác giống như trò chuyện (chat-like). Nhóm đã giới thiệu Dolly 2.0, một phiên bản nâng cao với khả năng tuân theo hướng dẫn được cải thiện.
Một tính năng chính của Dolly 2.0 là nền tảng của nó trên một instruction dataset chất lượng cao mới có tên là “databricks-dolly-15k.” Dataset này bao gồm 15.000 cặp prompt/response được thiết kế đặc biệt cho instruction tuning trong Large Language Models. Độc đáo thay, dataset Dolly 2.0 là open-source, được cấp phép theo Creative Commons Attribution-ShareAlike 3.0 Unported License, cho phép sử dụng rộng rãi, sửa đổi và mở rộng, bao gồm cả sử dụng thương mại.
Dolly 2.0 được xây dựng trên kiến trúc EleutherAI Pythia-12b, có 12 tỷ tham số. Điều này cho phép nó hiển thị hiệu suất tuân theo hướng dẫn chất lượng tương đối cao. Mặc dù có quy mô nhỏ hơn so với một số mô hình như LLaMA 70B, Dolly 2.0 đạt được kết quả ấn tượng, một phần nhờ vào quá trình đào tạo trên dữ liệu do con người tạo ra trong thế giới thực, thay vì các synthesized datasets.
Các mô hình của Databricks, bao gồm Dolly 2.0, có thể truy cập trên Hugging Face Hub. Mô hình databricks/dolly-v2-3b có sẵn để kiểm tra. Mã tương tự được sử dụng cho mô hình LLaMA có thể được áp dụng ở đây bằng cách thay đổi model_id.
model_id = "databricks/dolly-v2-3b"
Open Assistant
Sáng kiến Open Assistant tập trung vào việc dân chủ hóa quyền truy cập vào Large Language Models chất lượng cao thông qua mô hình open-source và hợp tác. Dự án này khác biệt với các lựa chọn thay thế open-source LLM khác, thường đi kèm với giấy phép hạn chế, bằng cách hướng đến việc cung cấp một mô hình ngôn ngữ dựa trên trò chuyện (chat-based) linh hoạt, có thể so sánh với ChatGPT và GPT-4 cho mục đích sử dụng thương mại.
Trọng tâm của Open Assistant là cam kết tính mở và tính bao trùm. Dự án đã biên soạn một dataset đáng kể được đóng góp bởi hơn 13.000 tình nguyện viên. Dataset này bao gồm hơn 600.000 tương tác, 150.000 tin nhắn và 10.000 cây hội thoại được chú thích đầy đủ bao gồm nhiều chủ đề bằng nhiều ngôn ngữ. Dự án thúc đẩy sự tham gia và đóng góp của cộng đồng, mời người dùng tham gia vào các task thu thập dữ liệu và xếp hạng để nâng cao hơn nữa khả năng của mô hình ngôn ngữ.
Các mô hình Open Assistant có sẵn trên Hugging Face, có thể truy cập qua bản demo Hugging Face hoặc trang web chính thức.
Mặc dù Open Assistant cung cấp một loạt các chức năng rộng rãi, nhưng nó gặp phải một số hạn chế về hiệu suất, đặc biệt là trong các lĩnh vực như toán học và code, do có ít tương tác đào tạo hơn trong các lĩnh vực này. Nói chung, mô hình này thành thạo trong việc tạo ra các phản hồi giống như con người, mặc dù nó không tránh khỏi những sai sót ngẫu nhiên.
Mistral LLMs
Mistral đã phát hành cả mô hình Open và Proprietary. Vào tháng 9 năm 2023, Mistral đã phát hành Mistral 7B, một mô hình mở với 7,3 tỷ tham số. Nó vượt trội hơn các mô hình LLaMA 2 13B và LLaMA 1 34B trong nhiều benchmark và gần như phù hợp với CodeLLaMA 7B trong các task liên quan đến code.
Mixtral 8x7B, một mô hình mở khác được phát hành vào tháng 12 năm 2023, là một sparse mixture of expert models vượt trội so với LLaMA 2 70B với suy luận nhanh hơn 6 lần. Nó có 46,7 tỷ tham số nhưng chỉ sử dụng 12,9 tỷ trên mỗi token, mang lại hiệu suất tiết kiệm chi phí. Mixtral 8x7B hỗ trợ nhiều ngôn ngữ, xử lý 32k token context, và vượt trội trong việc tạo code. Mixtral 8x7B Instruct là phiên bản được tối ưu hóa để tuân theo hướng dẫn.
Vào tháng 2 năm 2024, Mistral AI đã giới thiệu Mistral Large, mô hình proprietary ngôn ngữ tiên tiến nhất của họ. Nó đạt được kết quả mạnh mẽ trên các commonly used benchmarks, đưa nó vào số những mô hình được xếp hạng tốt nhất thường có sẵn thông qua API, tiếp theo là GPT-4 và Claude 3 Opus. Mistral Large thông thạo tiếng Anh, tiếng Pháp, tiếng Tây Ban Nha, tiếng Đức và tiếng Ý và có 32K token context window để thu hồi thông tin chính xác. Nó có sẵn thông qua La Plateforme và Azure.
Cùng với Mistral Large, Mistral AI đã phát hành Mistral Small, một mô hình được tối ưu hóa cho độ trễ và chi phí, vượt trội hơn Mixtral 8x7B. Cả Mistral Large và Mistral Small đều hỗ trợ chế độ định dạng JSON và function calling, cho phép các nhà phát triển tương tác với các mô hình một cách tự nhiên hơn và giao tiếp với các công cụ của riêng họ.
Applications and Use-Cases of LLMs
Y tế và Nghiên cứu Y khoa
Generative AI tăng cường đáng kể chăm sóc bệnh nhân, khám phá thuốc và hiệu quả hoạt động trong lĩnh vực y tế. Trong chẩn đoán, generative AI đang đạt được những bước tiến quan trọng với việc theo dõi bệnh nhân và tối ưu hóa tài nguyên. Việc tích hợp Large Language Models (LLM) vào digital pathology đã cải thiện đáng kể độ chính xác trong việc phát hiện bệnh, bao gồm cả ung thư. Ngoài ra, các model này còn góp phần tự động hóa các nhiệm vụ hành chính, hợp lý hóa quy trình làm việc và cho phép nhân viên lâm sàng tập trung vào các khía cạnh quan trọng của việc chăm sóc bệnh nhân. Ngành dược phẩm đã chứng kiến những thay đổi mang tính chuyển đổi nhờ generative AI trong khám phá thuốc. Công nghệ này đã đẩy nhanh quá trình, mang lại độ chính xác cao hơn cho các liệu pháp y tế, giảm thời gian phát triển thuốc và cắt giảm chi phí. Tiến bộ này đang mở ra cánh cửa cho các phương pháp điều trị cá nhân hóa hơn và các liệu pháp nhắm mục tiêu, hứa hẹn lớn cho việc chăm sóc bệnh nhân. Các công ty Medtech cũng đang khai thác tiềm năng của generative AI để phát triển các thiết bị cá nhân hóa cho việc chăm sóc lấy bệnh nhân làm trung tâm. Bằng cách tích hợp generative AI vào quy trình thiết kế, các thiết bị y tế có thể được tối ưu hóa cho các yêu cầu cá nhân của bệnh nhân, cải thiện kết quả điều trị và sự hài lòng của bệnh nhân. Ví dụ, Med-PaLM, được phát triển bởi Google, là một LLM được thiết kế để cung cấp câu trả lời chính xác cho các truy vấn y tế. Đây là một multimodal generative model có khả năng xử lý nhiều dữ liệu sinh học y tế khác nhau, bao gồm văn bản lâm sàng, hình ảnh y tế và genomics, sử dụng một bộ tham số model thống nhất. Một ví dụ đáng chú ý khác là BioMedLM, một domain-specific LLM cho văn bản sinh học y tế được tạo ra bởi Stanford Center for Research on Foundation Models (CRFM) và MosaicML.
Tài chính
LLM như GPT đang ngày càng có ảnh hưởng trong lĩnh vực tài chính, mang lại những cách thức mới cho các tổ chức tài chính tương tác với khách hàng và quản lý rủi ro. Ứng dụng chính của các model này trong tài chính là tăng cường tương tác khách hàng trên các nền tảng kỹ thuật số. Các model được sử dụng để cải thiện trải nghiệm người dùng thông qua chatbot hoặc các ứng dụng dựa trên AI, cung cấp hỗ trợ khách hàng hiệu quả và liền mạch với phản hồi thời gian thực cho các yêu cầu và mối quan tâm. LLM cũng đang đóng góp đáng kể vào việc phân tích dữ liệu chuỗi thời gian tài chính. Các model này có thể cung cấp những hiểu biết quan trọng cho phân tích kinh tế vĩ mô và dự đoán thị trường chứng khoán bằng cách tận dụng các bộ dữ liệu lớn từ các sàn giao dịch chứng khoán. Khả năng dự báo xu hướng thị trường và xác định các cơ hội đầu tư tiềm năng của chúng rất hữu ích cho việc đưa ra các quyết định tài chính sáng suốt. Một ví dụ về ứng dụng LLM trong tài chính là việc Bloomberg phát triển BloombergGPT. Model này, được đào tạo trên sự kết hợp của các tài liệu chung và domain-specific, thể hiện hiệu suất vượt trội trong các nhiệm vụ financial natural language processing mà không ảnh hưởng đến hiệu suất LLM chung đối với các nhiệm vụ khác.
Viết quảng cáo (Copywriting)
Language models và generative AI tác động đáng kể đến lĩnh vực copywriting bằng cách cung cấp các công cụ mạnh mẽ để tạo nội dung. Các ứng dụng của generative AI trong copywriting rất đa dạng. Nó có thể đẩy nhanh quá trình viết, vượt qua tình trạng bí ý tưởng của người viết và tăng năng suất, từ đó giảm chi phí. Hơn nữa, nó góp phần duy trì giọng điệu thương hiệu nhất quán bằng cách học và sao chép các mẫu ngôn ngữ và phong cách của công ty, thúc đẩy sự đồng nhất trong các nỗ lực tiếp thị. Các trường hợp sử dụng chính bao gồm tạo nội dung cho trang web và bài đăng trên blog, soạn thảo các cập nhật trên mạng xã hội, soạn mô tả sản phẩm và tối ưu hóa nội dung để hiển thị trên công cụ tìm kiếm. Ngoài ra, generative AI đóng một vai trò quan trọng trong việc tạo nội dung phù hợp cho các ứng dụng di động, điều chỉnh nó cho các nền tảng và trải nghiệm người dùng khác nhau. Jasper là một ví dụ về công cụ đơn giản hóa việc tạo nhiều nội dung tiếp thị khác nhau bằng cách sử dụng LLM. Người dùng có thể chọn từ một tập hợp các phong cách được xác định trước hoặc nắm bắt giọng điệu độc đáo của một công ty.
Giáo dục
LLM ngày càng có giá trị trong học trực tuyến và dạy kèm cá nhân hóa. Bằng cách đánh giá tiến độ học tập cá nhân, các model này cung cấp phản hồi phù hợp, kiểm tra thích ứng và các can thiệp học tập tùy chỉnh. Để giải quyết tình trạng thiếu giáo viên, LLM cung cấp các giải pháp có thể mở rộng như giáo viên ảo hoặc tăng cường khả năng của trợ giảng với các công cụ tiên tiến. Điều này cho phép các nhà giáo dục chuyển sang vai trò cố vấn và hướng dẫn, cung cấp hỗ trợ cá nhân hóa và trải nghiệm học tập tương tác. Khả năng của AI trong việc phân tích dữ liệu hiệu suất của học sinh cho phép cá nhân hóa trải nghiệm học tập, thích ứng với nhu cầu và tốc độ riêng của từng học sinh. Một ví dụ về LLM trong lĩnh vực giáo dục là Khanmigo từ Khan Academy. Trong ứng dụng này, LLM hoạt động như gia sư ảo, cung cấp các giải thích và ví dụ chi tiết để nâng cao sự hiểu biết về các môn học khác nhau. Ngoài ra, chúng hỗ trợ học ngôn ngữ bằng cách tạo câu để luyện ngữ pháp và từ vựng, đóng góp đáng kể vào trình độ ngôn ngữ.
Lập trình
Trong lập trình, LLMs (Large Language Models) và AI tạo sinh (generative AI) đang trở thành những công cụ không thể thiếu, cung cấp sự hỗ trợ đáng kể cho các nhà phát triển. Các mô hình như GPT-4 và các phiên bản tiền nhiệm vượt trội trong việc tạo ra các đoạn mã (code snippets) từ các yêu cầu bằng ngôn ngữ tự nhiên (natural language prompts), từ đó tăng hiệu quả của lập trình viên. Các mô hình này, được huấn luyện trên các bộ sưu tập mẫu mã rộng lớn, có thể nắm bắt ngữ cảnh, dần dần cải thiện khả năng tạo ra mã liên quan và chính xác.
Các ứng dụng của LLMs trong việc viết mã rất đa dạng và có giá trị. Chúng tạo điều kiện cho việc hoàn thiện mã (code completion) bằng cách đưa ra các gợi ý đoạn mã khi nhà phát triển gõ, tiết kiệm thời gian và giảm thiểu lỗi. LLMs cũng được sử dụng để tạo các unit tests và tự động hóa việc tạo các trường hợp kiểm thử (test cases), từ đó nâng cao chất lượng mã và có lợi cho việc bảo trì phần mềm.
Tuy nhiên, việc sử dụng AI tạo sinh trong viết mã đặt ra những thách thức. Mặc dù các công cụ này có thể tăng năng suất, điều quan trọng là các nhà phát triển phải xem xét kỹ lưỡng mã được tạo ra để đảm bảo nó không có lỗi hoặc lỗ hổng bảo mật (security vulnerabilities). Ngoài ra, cần giám sát và xác thực cẩn thận đối với những điểm không chính xác của mô hình (model inaccuracies).
Một sản phẩm đáng chú ý tận dụng LLMs cho lập trình là GitHub Copilot. Được huấn luyện trên hàng tỷ dòng mã, Copilot có thể chuyển đổi các yêu cầu bằng ngôn ngữ tự nhiên thành các gợi ý mã trên nhiều ngôn ngữ lập trình khác nhau.
Ngành Pháp lý
Trong lĩnh vực pháp lý, LLMs và AI tạo sinh đã chứng tỏ là những nguồn tài nguyên hữu ích, cung cấp các ứng dụng đa dạng phù hợp với các yêu cầu riêng của lĩnh vực này. Các mô hình này vượt trội trong việc điều hướng sự phức tạp của ngôn ngữ pháp lý, diễn giải và bối cảnh pháp luật không ngừng phát triển. Chúng có thể hỗ trợ đáng kể cho các chuyên gia pháp lý trong nhiều nhiệm vụ, chẳng hạn như đưa ra lời khuyên pháp lý, hiểu các tài liệu pháp lý phức tạp và phân tích văn bản từ các vụ án tòa án.
Một mục tiêu quan trọng đối với tất cả các ứng dụng LLM trong luật là giảm thiểu sự không chính xác, thường được gọi là ‘hallucinations,’ vốn là một vấn đề đáng chú ý với các mô hình này. Kết hợp kiến thức đặc thù lĩnh vực (domain-specific knowledge), thông qua các mô-đun tham chiếu hoặc bằng cách lấy dữ liệu đáng tin cậy từ các cơ sở kiến thức đã được thiết lập, có thể cho phép các mô hình này mang lại kết quả chính xác và đáng tin cậy hơn.
Ngoài ra, chúng có thể xác định các thuật ngữ pháp lý quan trọng trong đầu vào của người dùng và nhanh chóng đánh giá các kịch bản pháp lý, nâng cao tính hữu dụng thực tế của chúng trong bối cảnh pháp lý.
Rủi ro và Cân nhắc Đạo đức khi Sử dụng LLMs trong Thế giới Thực
Việc triển khai Large Language Models (LLMs) cho các ứng dụng trong thế giới thực đặt ra nhiều rủi ro và cân nhắc đạo đức.
Một rủi ro đáng chú ý là sự xuất hiện của “hallucinations,” nơi các mô hình tạo ra thông tin có vẻ hợp lý nhưng sai lệch. Điều này có thể có những tác động sâu sắc, đặc biệt là trong các lĩnh vực nhạy cảm như chăm sóc sức khỏe, tài chính và luật pháp, nơi độ chính xác là rất quan trọng.
Một lĩnh vực đáng lo ngại khác là “bias” (thiên vị). LLMs có thể vô tình phản ánh và lan truyền những thiên vị xã hội vốn có trong dữ liệu huấn luyện của chúng. Điều này có thể dẫn đến những kết quả không công bằng trong các lĩnh vực quan trọng như chăm sóc sức khỏe và tài chính. Giải quyết vấn đề này đòi hỏi một nỗ lực chuyên biệt hướng tới đánh giá dữ liệu kỹ lưỡng, thúc đẩy tính hòa nhập và liên tục làm việc để nâng cao tính công bằng.
Quyền riêng tư và bảo mật dữ liệu (data privacy and security) cũng rất cần thiết. LLMs có khả năng vô tình ghi nhớ và tiết lộ thông tin nhạy cảm, gây ra rủi ro vi phạm quyền riêng tư. Những người tạo ra các mô hình này phải thực hiện các biện pháp như ẩn danh hóa dữ liệu (data anonymization) và kiểm soát truy cập nghiêm ngặt để giảm thiểu rủi ro này.
Hơn nữa, tác động của LLMs đối với việc làm không thể bỏ qua. Mặc dù chúng mang lại lợi ích tự động hóa, điều cần thiết là phải duy trì sự cân bằng với sự tham gia của con người để giữ gìn và coi trọng chuyên môn của con người. Sự phụ thuộc quá mức vào LLMs mà không có đủ sự phán xét của con người có thể gây nguy hiểm. Việc áp dụng một cách tiếp cận có trách nhiệm, hài hòa những lợi ích của AI với sự giám sát của con người là điều bắt buộc để sử dụng hiệu quả và đạo đức.
Chapter III: LLMs in Practice
Understanding Hallucinations and Bias
Những thành tựu đạt được với AI trong vài năm qua thật phi thường, nhưng các foundation models có sẵn vẫn có những hạn chế, ngăn cản việc sử dụng trực tiếp chúng trong sản xuất, ngay cả đối với những tác vụ đơn giản nhất. Về cốt lõi, LLMs học từ lượng lớn dữ liệu thu thập từ Internet, sách và bài viết. Mặc dù dữ liệu này phong phú và nhiều thông tin, nhưng nó cũng chứa đầy những sai sót và định kiến xã hội. Trong quá trình cố gắng hiểu dữ liệu này, LLMs đôi khi đưa ra những kết luận sai lầm, dẫn đến hallucinations và biases. Giải quyết, hiểu và giải quyết vấn đề này sẽ là một bước quan trọng trong việc áp dụng rộng rãi AI.
Hallucinations trong LLMs
Hallucinations trong Large Language Models (LLMs) xảy ra khi mô hình tạo ra văn bản không chính xác và không dựa trên thực tế. Hiện tượng này liên quan đến việc mô hình tự tin tạo ra các phản hồi không có cơ sở trong dữ liệu huấn luyện của nó. Một số yếu tố góp phần gây ra hallucinations trong LLMs:
- LLMs có thể được huấn luyện trên các tập dữ liệu thiếu kiến thức cần thiết để trả lời các câu hỏi cụ thể.
- Các mô hình này thường thiếu cơ chế để xác minh tính chính xác thực tế của đầu ra, dẫn đến các phản hồi có vẻ thuyết phục nhưng không chính xác.
- Dữ liệu huấn luyện có thể chứa nội dung hư cấu và chủ quan, bao gồm ý kiến hoặc niềm tin.
- LLMs không được thiết kế để thể hiện sự không chắc chắn hoặc thừa nhận thiếu thông tin. Khi đối mặt với dữ liệu không đủ, một LLM có thể sẽ tạo ra chuỗi văn bản có khả năng xảy ra cao nhất làm phản hồi. Tuy nhiên, “khả năng xảy ra cao nhất” không có nghĩa là “đúng”. Hallucinations cũng có thể phát sinh từ sự khác biệt này vì mục tiêu chính của mô hình ngôn ngữ là học các mẫu phân phối từ của ngôn ngữ, chứ không phải phân biệt giữa các câu đúng và sai.
Đây là một ví dụ: Databricks đã công bố “Dolly 2.0”, một mô hình ngôn ngữ mã nguồn mở 12 tỷ tham số được tinh chỉnh với tập dữ liệu được tạo ra để tuân theo hướng dẫn của con người vào ngày 12 tháng 4 năm 2023. GPT-3.5, với dữ liệu huấn luyện đến năm 2022, không có thông tin về Dolly 2. Khi GPT-3.5 được hỏi, “Databricks’ Dolly có đóng góp giá trị cho cộng đồng mã nguồn mở không?”, phản hồi của nó có thể là:
GPT-3.5: Databricks Dolly là sản phẩm của Databricks, nhằm hỗ trợ người dùng chuyển dữ liệu giữa các nền tảng, đặc biệt là từ các trung tâm dữ liệu tại chỗ sang các nền tảng đám mây như AWS hoặc Azure. Mặc dù Databricks Dolly không phải là mã nguồn mở, nhưng nó có khả năng mang lại lợi ích cho cộng đồng mã nguồn mở ở một số khía cạnh. […]
Ngoài việc nhận ra chính xác “Databricks Dolly” là sản phẩm của công ty Databricks, phản hồi còn chứa một số điểm không chính xác. Nó trình bày sai Dolly là một công cụ di chuyển dữ liệu. Tuy nhiên, vì GPT-3.5 biết Databricks là một công ty, nó tạo ra một mô tả có vẻ hợp lý nhưng không chính xác về Dolly 2 như một sản phẩm điển hình của Databricks.
Đây là một ví dụ về hallucination trong GPT-3.5 của OpenAI, nhưng vấn đề này không chỉ có ở mô hình này. Tất cả các LLMs tương tự, như Bard hoặc LLaMA, cũng thể hiện hành vi này.
Large Language Models (LLMs) có thể tạo ra nội dung có vẻ đáng tin cậy nhưng không chính xác về mặt thực tế do khả năng hiểu sự thật và xác minh sự kiện hạn chế của chúng. Điều này khiến chúng vô tình dễ lan truyền thông tin sai lệch. Ngoài ra, có nguy cơ những cá nhân có ý định xấu có thể cố ý sử dụng LLMs để phát tán thông tin sai lệch, tạo và khuếch đại các câu chuyện sai sự thật. Theo một nghiên cứu của Blackberry, khoảng 49% người được hỏi tin rằng GPT-4 có thể được sử dụng để lan truyền thông tin sai lệch. Việc xuất bản không kiểm soát thông tin không chính xác như vậy thông qua LLMs có thể gây ra những hậu quả sâu rộng trên các lĩnh vực xã hội, văn hóa, kinh tế và chính trị. Giải quyết những thách thức liên quan đến hallucinations của LLM là rất quan trọng đối với việc áp dụng đạo đức của các mô hình này.
Một số chiến lược để giảm hallucinations bao gồm điều chỉnh các tham số hướng dẫn tạo văn bản, cải thiện chất lượng dữ liệu huấn luyện, xây dựng lời nhắc cẩn thận và sử dụng kiến trúc retriever. Kiến trúc retriever giúp neo các phản hồi trong các tài liệu cụ thể, cung cấp nền tảng thực tế cho đầu ra của mô hình.
Cải thiện độ chính xác của LLM
Điều chỉnh các tham số tạo văn bản
Các tham số như temperature, frequency penalty, presence penalty và top-p ảnh hưởng đáng kể đến đầu ra của LLM—giá trị temperature thấp hơn dẫn đến các phản hồi có thể dự đoán và tái tạo được nhiều hơn. Frequency penalty dẫn đến việc sử dụng bảo thủ hơn các token lặp lại. Tăng presence penalty khuyến khích mô hình tạo ra các token mới chưa xuất hiện trước đó trong văn bản được tạo. Các tham số “top-p” kiểm soát sự đa dạng của phản hồi bằng cách xác định ngưỡng xác suất tích lũy để chọn từ và tùy chỉnh phạm vi phản hồi của mô hình. Tất cả những yếu tố này góp phần làm giảm nguy cơ hallucinations.
Tận dụng tài liệu bên ngoài với kiến trúc Retrievers
Độ chính xác của LLM có thể được cải thiện bằng cách kết hợp kiến thức cụ thể theo miền thông qua các tài liệu bên ngoài. Quá trình này cập nhật cơ sở kiến thức của mô hình bằng thông tin liên quan, cho phép nó dựa trên phản hồi của mình trên cơ sở kiến thức mới. Khi một truy vấn được gửi, các tài liệu liên quan sẽ được truy xuất bằng mô-đun “retriever”, giúp cải thiện phản hồi của mô hình. Phương pháp này là không thể thiếu đối với kiến trúc retriever. Các kiến trúc này hoạt động như sau:
- Khi nhận được câu hỏi, hệ thống sẽ tạo ra biểu diễn embedding của nó.
- Embedding này được sử dụng để thực hiện tìm kiếm ngữ nghĩa trong cơ sở dữ liệu tài liệu (bằng cách so sánh embeddings và tính toán điểm tương đồng).
- LLM sử dụng các văn bản được truy xuất xếp hạng hàng đầu làm ngữ cảnh để cung cấp phản hồi cuối cùng. Thông thường, LLM phải trích xuất cẩn thận câu trả lời từ các đoạn văn ngữ cảnh và không viết bất cứ điều gì không thể suy ra từ chúng.
Retrieval-augmented generation (RAG) là một kỹ thuật để tăng cường khả năng của các mô hình ngôn ngữ bằng cách thêm dữ liệu từ các nguồn bên ngoài. Thông tin này được kết hợp với ngữ cảnh đã có trong lời nhắc của mô hình, cho phép mô hình đưa ra các phản hồi chính xác và phù hợp hơn.
Quyền truy cập vào các nguồn dữ liệu bên ngoài trong giai đoạn tạo giúp cải thiện đáng kể cơ sở kiến thức và nền tảng của mô hình. Phương pháp này làm cho mô hình ít bị hallucinations hơn bằng cách hướng dẫn nó tạo ra các phản hồi chính xác và phù hợp theo ngữ cảnh.
Thiên vị trong LLMs (Bias in LLMs)
Các Mô hình Ngôn ngữ Lớn (Large Language Models - LLMs), bao gồm GPT-3.5 và GPT-4, đã đặt ra những lo ngại đáng kể về quyền riêng tư và đạo đức. Các nghiên cứu chỉ ra rằng những mô hình này có thể chứa đựng những thiên vị nội tại (intrinsic biases), dẫn đến việc tạo ra ngôn ngữ thiên vị hoặc xúc phạm. Điều này làm gia tăng các vấn đề liên quan đến ứng dụng và quy định của chúng.
Thiên vị LLM (LLM biases) xuất phát từ nhiều nguồn khác nhau, bao gồm dữ liệu (data), quá trình chú thích (annotation process), biểu diễn đầu vào (input representations), các mô hình (models) và phương pháp nghiên cứu (research methodology).
Dữ liệu huấn luyện (training data) thiếu đa dạng ngôn ngữ có thể dẫn đến thiên vị nhân khẩu học (demographic biases). Các Mô hình Ngôn ngữ Lớn (LLMs) có thể vô tình học các định kiến (stereotypes) từ dữ liệu huấn luyện của chúng, dẫn đến việc tạo ra nội dung phân biệt đối xử dựa trên chủng tộc (race), giới tính (gender), tôn giáo (religion) và dân tộc (ethnicity). Ví dụ, nếu dữ liệu huấn luyện chứa thông tin thiên vị, một LLM có thể tạo ra nội dung miêu tả phụ nữ trong vai trò phụ thuộc hoặc mô tả một số dân tộc nhất định là bạo lực hoặc không đáng tin cậy. Tương tự, việc huấn luyện mô hình trên dữ liệu ngôn từ thù hận (hate speech) hoặc nội dung độc hại (toxic content) có thể tạo ra các đầu ra có hại, củng cố các định kiến và thiên vị tiêu cực.
Giảm thiểu Thiên vị trong LLMs: Constitutional AI
Constitutional AI là một khung (framework) được phát triển bởi các nhà nghiên cứu tại Anthropic để điều chỉnh các hệ thống AI phù hợp với các giá trị của con người, tập trung vào việc làm cho chúng có lợi, an toàn và đáng tin cậy.
Ban đầu, mô hình được huấn luyện để đánh giá và điều chỉnh phản hồi của mình bằng cách sử dụng một tập hợp các nguyên tắc đã thiết lập (established principles) và một số lượng ví dụ hạn chế (limited number of examples). Tiếp theo là huấn luyện học tăng cường (reinforcement learning training), trong đó mô hình sử dụng phản hồi do AI tạo ra (AI-generated feedback) từ các nguyên tắc này để chọn phản hồi phù hợp nhất, giảm sự phụ thuộc vào phản hồi của con người.
Constitutional AI sử dụng các phương pháp như huấn luyện tự giám sát (self-supervision training), cho phép AI thích ứng với các nguyên tắc hướng dẫn của nó mà không cần sự giám sát trực tiếp của con người.
Chiến lược này cũng tạo ra các kỹ thuật tối ưu hóa bị ràng buộc (constrained optimization techniques) đảm bảo rằng AI cố gắng hữu ích trong các tham số được thiết lập bởi hiến pháp của nó (constitution). Để hành động, giảm thiên vị và ảo giác (hallucinations), và cải thiện kết quả, trước tiên chúng ta cần đánh giá hiệu suất của các mô hình (models’ performances). Chúng ta làm điều này nhờ các tiêu chuẩn đồng nhất (uniform benchmarks) và các quy trình đánh giá (evaluation processes).
Evaluating LLM Performance
Những tiến bộ trong Large Language Models (LLMs) được neo giữ vào việc đánh giá chính xác hiệu suất của chúng so với các benchmarks. Việc đánh giá chính xác hiệu suất LLM đòi hỏi một phương pháp tiếp cận đa diện, kết hợp nhiều benchmarks và metrics khác nhau để đo lường khả năng trên các tasks và domains khác nhau.
Objective Functions và Evaluation Metrics
Objective functions và evaluation metrics là những thành phần quan trọng của các machine learning models.
- Objective function hay loss function là một công thức toán học quan trọng được áp dụng trong giai đoạn training của model. Nó gán một loss score dựa trên các model parameters. Trong suốt quá trình training, thuật toán học tính toán gradients của loss function và điều chỉnh các model parameters để giảm thiểu score này. Do đó, loss function phải differentiable và có dạng smooth để việc học hiệu quả.
- Cross-entropy loss là objective function thường được sử dụng cho Large Language Models (LLMs). Trong causal language modeling, nơi model dự đoán token tiếp theo từ một danh sách định trước, điều này về cơ bản chuyển thành một classification problem.
- Evaluation metrics là các công cụ để đo lường hiệu suất của model theo các thuật ngữ mà con người có thể hiểu được. Các metrics này không được tích hợp trực tiếp trong quá trình training, do đó chúng không nhất thiết phải differentiable vì gradients của chúng không cần thiết. Các evaluation metrics phổ biến bao gồm accuracy, precision, recall, F1-score và mean squared error. Đối với Large Language Models (LLMs), evaluation metrics có thể được phân loại như sau:
- Intrinsic metrics, liên quan trực tiếp đến training objective. Một intrinsic metric nổi tiếng là perplexity.
- Extrinsic metrics đánh giá hiệu suất trên các downstream tasks khác nhau và không liên quan trực tiếp đến training objective. Các ví dụ phổ biến về extrinsic metrics bao gồm các benchmarking frameworks như GLUE, SuperGLUE, BIG-bench, HELM và FLASK.
Perplexity Evaluation Metric
Perplexity metric đánh giá hiệu suất của Large Language Models (LLMs). Nó đánh giá mức độ hiệu quả của một language model trong việc dự đoán một sample hoặc sequence words cụ thể, chẳng hạn như một câu. Giá trị perplexity thấp hơn cho thấy một language model thành thạo hơn.
LLMs được phát triển để mô phỏng probability distributions của các words trong câu, cho phép chúng tạo ra các câu giống như con người. Perplexity đo lường mức độ không chắc chắn hoặc “perplexity” mà model gặp phải khi xác định probabilities cho các sequence words.
Bước đầu tiên để đo lường perplexity là tính toán probability của một câu. Điều này được thực hiện bằng cách nhân các probabilities được gán cho mỗi word. Vì các câu dài hơn thường dẫn đến probabilities thấp hơn (do phép nhân của nhiều factors nhỏ hơn một), perplexity giới thiệu normalization. Normalization chia probability cho số lượng words của câu và tính toán geometric mean, giúp so sánh có ý nghĩa giữa các câu có độ dài khác nhau.
Ví dụ về Perplexity
Xem xét ví dụ sau: một language model được training để dự đoán word tiếp theo trong câu: “A red fox.” Các anticipated word probabilities cho một LLM competent có thể như sau:
P(“a red fox.”) = P(“a”) * P(“red” | “a”) * P(“fox” | “a red”) * P(“.” | “a red fox”) P(“a red fox.”) = 0.4 * 0.27 * 0.55 * 0.79 P(“a red fox.”) = 0.0469
Để so sánh hiệu quả các probabilities được gán cho các câu khác nhau, hãy xem xét tác động của độ dài câu đến các probabilities này. Thông thường, probability giảm đối với các câu dài hơn do phép nhân của nhiều factors, mỗi factor nhỏ hơn một. Điều này có thể được giải quyết bằng một phương pháp đo lường probabilities của câu độc lập với độ dài câu.
Normalizing probability của câu bằng số lượng words cũng giảm thiểu tác động của độ dài câu khác nhau. Kỹ thuật này tính trung bình nhiều factors tạo thành probability của câu, do đó đưa ra một so sánh cân bằng hơn giữa các câu có độ dài khác nhau. Để biết thêm thông tin về điều này, hãy đọc thêm trên trang Wikipedia tại: Geometric Mean.
Gọi Pnorm(W) là normalized probability của câu W. Gọi n là số lượng words trong W. Sau đó, áp dụng geometric mean:
Pnorm(W) = P(W) ^ (1 / n)
Sử dụng câu cụ thể của chúng ta, “a red fox.”:
Pnorm(“a red fox.”) = P(“a red fox.”) ^ (1 / 4) = 0.465
Con số này bây giờ có thể được sử dụng để so sánh likelihood của các câu có độ dài khác nhau. Language model càng tốt thì giá trị này càng cao.
Điều này liên quan như thế nào đến perplexity? Perplexity chỉ đơn giản là reciprocal của giá trị này. Gọi PP(W) là perplexity được tính toán trên câu W. Sau đó:
PP(W) = 1 / Pnorm(W) PP(W) = 1 / (P(W) ^ (1 / n)) PP(W) = (1 / P(W)) ^ (1 / n))
Hãy tính toán nó với numpy:
import numpy as np
probabilities = np.array([0.4, 0.27, 0.55, 0.79])
sentence_probability = probabilities.prod()
sentence_probability_normalized = sentence_probability ** (1 / len(probabilities))
perplexity = 1 / sentence_probability_normalized
print(perplexity) # 2.1485556947850033
Nếu chúng ta training LLM thêm, probabilities của word tốt nhất tiếp theo sẽ cao hơn. Perplexity cuối cùng sẽ như thế nào, cao hơn hay thấp hơn?
probabilities = np.array([0.7, 0.5, 0.6, 0.9])
sentence_probability = probabilities.prod()
sentence_probability_normalized = sentence_probability ** (1 / len(probabilities))
perplexity = 1 / sentence_probability_normalized
print(perplexity) # 1.516647134682679 -> thấp hơn
Điểm Chuẩn GLUE (General Language Understanding Evaluation)
Điểm chuẩn GLUE (General Language Understanding Evaluation) bao gồm chín nhiệm vụ hiểu câu tiếng Anh đa dạng, được nhóm thành ba loại:
- Nhiệm vụ Đơn Câu (Single-Sentence Tasks): Kiểm tra khả năng của mô hình trong việc xác định tính đúng ngữ pháp (CoLA) và cực tính cảm xúc (SST-2) trong các câu riêng lẻ.
- Nhiệm vụ Tương Đồng & Diễn Giải (Similarity & Paraphrase Tasks): Đo lường khả năng của mô hình trong việc nhận biết các diễn giải trong các cặp câu (MRPC và QQP) và quyết định điểm tương đồng giữa các câu (STS-B).
- Nhiệm vụ Suy Luận (Inference Tasks): Đánh giá khả năng của mô hình trong việc xử lý sự kéo theo và mối quan hệ giữa các câu. Điều này bao gồm việc xác định sự kéo theo văn bản (RTE), diễn giải các câu hỏi dựa trên thông tin câu (QNLI) và giải mã các tham chiếu đại từ (WNLI).
Điểm GLUE tổng thể được tính bằng cách lấy trung bình kết quả trên tất cả chín nhiệm vụ. GLUE là một nền tảng toàn diện để đánh giá và hiểu điểm mạnh và điểm yếu của các mô hình NLP khác nhau.
Điểm Chuẩn SuperGLUE
Điểm chuẩn SuperGLUE là một bước tiến của điểm chuẩn GLUE, giới thiệu các nhiệm vụ phức tạp hơn để thách thức các phương pháp NLP hiện tại. Các khía cạnh đáng chú ý của SuperGLUE là:
- Nhiệm vụ (Tasks): SuperGLUE có tám nhiệm vụ hiểu ngôn ngữ đa dạng. Chúng bao gồm trả lời câu hỏi Boolean, sự kéo theo văn bản, giải quyết tham chiếu đồng ngữ, đọc hiểu liên quan đến suy luận thông thường và phân biệt nghĩa của từ (word-sense disambiguation).
- Độ Khó (Difficulty): SuperGLUE đạt được mức độ phức tạp cao hơn bằng cách giữ lại các nhiệm vụ khó khăn nhất từ GLUE và kết hợp các nhiệm vụ mới giải quyết các hạn chế của các mô hình NLP hiện tại. Điều này làm cho nó phù hợp hơn với các tình huống hiểu ngôn ngữ trong thế giới thực.
- Đường Cơ Sở Con Người (Human Baselines): SuperGLUE cung cấp ước tính hiệu suất của con người cho mỗi số liệu. Đặc điểm này giúp so sánh khả năng của các mô hình NLP với khả năng xử lý ngôn ngữ ở cấp độ con người.
- Đánh Giá (Evaluation): Hiệu suất của các mô hình NLP trên các nhiệm vụ này được đánh giá và định lượng bằng điểm số tổng thể. Điểm số này được tính bằng cách lấy trung bình kết quả từ tất cả các nhiệm vụ riêng lẻ.
Điểm Chuẩn BIG-Bench
Điểm chuẩn BIG-bench là một nền tảng toàn diện và đa dạng để đánh giá khả năng của LLM. Nó bao gồm hơn 204 nhiệm vụ ngôn ngữ trên nhiều chủ đề và ngôn ngữ, đưa ra những thách thức mà các mô hình hiện tại không hoàn toàn có thể giải quyết được.
BIG-bench cung cấp hai loại nhiệm vụ: dựa trên JSON và lập trình. Nhiệm vụ JSON được đánh giá bằng cách so sánh các cặp đầu ra và mục tiêu, và các nhiệm vụ lập trình sử dụng Python để đánh giá việc tạo văn bản và xác suất log có điều kiện. Các nhiệm vụ bao gồm viết mã, suy luận thông thường, chơi trò chơi, ngôn ngữ học, v.v.
Nghiên cứu chỉ ra rằng các mô hình lớn hơn có xu hướng cho thấy hiệu suất tổng hợp được cải thiện nhưng không đạt đến mức khả năng của con người. Ngoài ra, dự đoán của mô hình trở nên chính xác hơn khi mở rộng quy mô và kết hợp độ thưa thớt (sparsity).
Được coi là một “điểm chuẩn sống” (living benchmark), BIG-bench liên tục chấp nhận các bài nộp nhiệm vụ mới để đánh giá ngang hàng liên tục. Mã của điểm chuẩn là mã nguồn mở và có thể truy cập trên GitHub.
Điểm Chuẩn HELM (Holistic Evaluation of Language Models)
Điểm chuẩn Đánh Giá Toàn Diện Mô Hình Ngôn Ngữ (Holistic Evaluation of Language Models - HELM) được tạo ra để đáp ứng nhu cầu về một tiêu chuẩn toàn diện để so sánh các mô hình ngôn ngữ nhằm đánh giá chúng. HELM được cấu trúc xung quanh ba thành phần chính:
- Phạm Vi Rộng và Nhận Biết Sự Không Hoàn Chỉnh (Broad Coverage and Recognition of Incompleteness): HELM tiến hành đánh giá trên nhiều kịch bản, bao gồm các nhiệm vụ, miền, ngôn ngữ và ứng dụng hướng đến người dùng đa dạng. Nó thừa nhận sự bất khả thi của việc bao phủ mọi kịch bản nhưng cố tình xác định các kịch bản chính và các số liệu bị thiếu, làm nổi bật các lĩnh vực cải tiến.
- Đo Lường Đa Số Liệu (Multi-Metric Measurement): Không giống như các điểm chuẩn trước đây chỉ dựa vào độ chính xác, HELM đánh giá các mô hình ngôn ngữ bằng phương pháp đa số liệu. Nó kết hợp bảy số liệu: độ chính xác, hiệu chuẩn, độ mạnh mẽ, tính công bằng, độ lệch, độc tính và hiệu quả. Tập hợp tiêu chí đa dạng này đảm bảo đánh giá toàn diện hơn.
- Tiêu Chuẩn Hóa (Standardization): HELM tập trung vào việc tiêu chuẩn hóa quy trình đánh giá trên các mô hình ngôn ngữ khác nhau. Nó vạch ra một quy trình thích ứng thống nhất bằng cách sử dụng nhắc nhở few-shot để so sánh các mô hình khác nhau. Bằng cách đánh giá 30 mô hình từ nhiều nhà cung cấp, HELM tạo ra một nền tảng minh bạch và đáng tin cậy hơn cho các công nghệ ngôn ngữ.
Điểm Chuẩn FLASK (Fine-grained Language Model Evaluation based on Alignment Skill Sets)
Điểm chuẩn FLASK (Đánh Giá Mô Hình Ngôn Ngữ Tinh Chỉnh Dựa Trên Bộ Kỹ Năng Căn Chỉnh - Fine-grained Language Model Evaluation based on Alignment Skill Sets) là một giao thức đánh giá chi tiết được thiết kế riêng cho Mô Hình Ngôn Ngữ Lớn (LLM). Nó nghiên cứu quá trình đánh giá thành 12 bộ kỹ năng theo từng trường hợp riêng biệt, mỗi bộ đại diện cho một chiều hướng thiết yếu của khả năng của mô hình.
Các bộ kỹ năng này bao gồm tính đúng logic, hiệu quả logic, tính thực tế, hiểu biết thông thường, sự thấu hiểu, sự sâu sắc, tính đầy đủ, siêu nhận thức, tính dễ đọc, tính ngắn gọn và tính vô hại.
Bằng cách phân đoạn đánh giá thành các bộ kỹ năng cụ thể, FLASK tạo điều kiện cho việc đánh giá chính xác và chuyên sâu về hiệu suất của mô hình trên nhiều nhiệm vụ, miền và mức độ khó. Phương pháp này cung cấp cái nhìn chi tiết và sắc thái về điểm mạnh và điểm yếu của mô hình ngôn ngữ và giúp các nhà nghiên cứu/nhà phát triển tinh chỉnh mô hình bằng cách tiếp cận tập trung và giải quyết các thách thức cụ thể trong NLP.
Controlling LLM Outputs
Các Phương pháp Giải mã (Decoding Methods)
Các phương pháp giải mã là các kỹ thuật thiết yếu được LLM sử dụng để tạo văn bản. Trong quá trình giải mã, LLM gán điểm số cho mỗi vocabulary token, với điểm số cao hơn cho thấy khả năng token đó được chọn làm tiếp theo cao hơn. Các mẫu học được của mô hình xác định các điểm số này trong quá trình huấn luyện.
Tuy nhiên, token có xác suất cao nhất không phải lúc nào cũng tối ưu cho token tiếp theo. Việc chọn token có xác suất cao nhất trong bước đầu tiên có thể dẫn đến một chuỗi có xác suất thấp hơn trong các token tiếp theo. Điều này dẫn đến tổng joint likelihood thấp. Ngoài ra, việc chọn một token có xác suất thấp hơn một chút có thể dẫn đến các token có xác suất cao hơn trong các bước tiếp theo, đạt được joint probability tổng thể cao hơn. Mặc dù lý tưởng, việc tính toán xác suất cho tất cả các vocabulary token qua nhiều bước là không thực tế do yêu cầu tính toán.
Các phương pháp giải mã sau đây nhằm mục đích tìm sự cân bằng giữa:
- Việc “tham lam” (being “greedy”) bằng cách chọn ngay token có xác suất cao nhất.
- Cho phép một số khám phá (exploration) bằng cách dự đoán nhiều token cùng lúc để tăng cường tính mạch lạc (coherence) và tính liên quan theo ngữ cảnh (context relevance) tổng thể.
Tìm kiếm Tham lam (Greedy Search)
Greedy Search là phương pháp giải mã cơ bản nhất, trong đó mô hình luôn chọn token có xác suất cao nhất làm đầu ra tiếp theo. Greedy Search có hiệu quả tính toán cao nhưng có xu hướng tạo ra các phản hồi lặp đi lặp lại hoặc không tối ưu. Điều này là do nó ưu tiên token có khả năng xảy ra cao nhất ngay lập tức hơn chất lượng tổng thể của đầu ra về lâu dài.
Lấy mẫu (Sampling)
Sampling giới thiệu yếu tố ngẫu nhiên trong việc tạo văn bản. Ở đây, mô hình chọn từ tiếp theo một cách ngẫu nhiên, được hướng dẫn bởi phân phối xác suất của các token. Phương pháp này có thể dẫn đến đầu ra đa dạng và phong phú hơn. Tuy nhiên, đôi khi nó có thể tạo ra văn bản kém mạch lạc hoặc logic hơn, vì việc lựa chọn không chỉ dựa trên xác suất cao nhất.
Tìm kiếm Chùm (Beam Search)
Beam Search là một chiến lược giải mã nâng cao hơn. Nó liên quan đến việc chọn N ứng cử viên hàng đầu (trong đó N là một tham số được xác định trước) có xác suất cao nhất cho token tiếp theo ở mỗi bước, nhưng chỉ trong một số bước giới hạn. Cuối cùng, mô hình tạo ra chuỗi (tức là beam) có joint probability tổng thể cao nhất.
Phương pháp này thu hẹp không gian tìm kiếm, thường dẫn đến kết quả mạch lạc hơn. Beam Search có thể chậm và không phải lúc nào cũng tạo ra đầu ra tốt nhất. Nó có thể bỏ lỡ các từ có xác suất cao khi đứng trước một từ có xác suất thấp hơn.
Lấy mẫu Top-K (Top-K Sampling)
Top-K Sampling là một kỹ thuật trong đó mô hình giới hạn nhóm lựa chọn của nó trong K từ có xác suất cao nhất (với K là một tham số). Phương pháp này tạo ra sự đa dạng trong văn bản, đảm bảo tính liên quan bằng cách giảm phạm vi lựa chọn và cung cấp khả năng kiểm soát nâng cao đối với đầu ra.
Lấy mẫu Top-p (Nucleus) (Top-p (Nucleus) Sampling)
Top-p hoặc Nucleus Sampling chọn các từ từ nhóm token nhỏ nhất có xác suất kết hợp vượt quá ngưỡng P được chỉ định (với P là một tham số). Kỹ thuật này cho phép kiểm soát đầu ra chính xác bằng cách loại trừ các token hiếm hoặc không có khả năng xảy ra. Một thách thức với phương pháp này là tính không thể đoán trước của kích thước khác nhau của danh sách rút gọn.
Các Tham số Ảnh hưởng đến Việc Tạo Văn bản (Parameters That Influence Text Generation)
Ngoài việc giải mã, một số tham số có thể được điều chỉnh để ảnh hưởng đến việc tạo văn bản. Các tham số chính, bao gồm nhiệt độ (temperature), chuỗi dừng (stop sequences), tần suất (frequency) và hình phạt hiện diện (presence penalties), có thể được điều chỉnh với các API LLM phổ biến nhất và các mô hình Hugging Face.
Nhiệt độ (Temperature)
Tham số nhiệt độ rất quan trọng trong việc cân bằng tính không thể đoán trước và tính xác định của việc tạo văn bản. Cài đặt nhiệt độ thấp hơn tạo ra đầu ra xác định và tập trung hơn, đồng thời cài đặt nhiệt độ cao hơn giới thiệu tính ngẫu nhiên, tạo ra đầu ra đa dạng. Tham số này hoạt động bằng cách điều chỉnh logits trước khi áp dụng softmax trong quá trình tạo văn bản. Điều này đảm bảo sự cân bằng giữa sự đa dạng của đầu ra và chất lượng của nó.
- Logits: Ở cốt lõi của quá trình dự đoán của mô hình ngôn ngữ là việc tạo ra một vectơ logit. Mỗi token tiếp theo tiềm năng có một logit tương ứng, phản ánh điểm dự đoán ban đầu, chưa được điều chỉnh của nó.
- Softmax: Hàm này biến đổi logits thành xác suất. Một tính năng chính của hàm softmax là đảm bảo rằng các xác suất này cộng lại bằng 1.
- Nhiệt độ (Temperature): Tham số này quyết định tính ngẫu nhiên của đầu ra. Trước giai đoạn softmax, các logits được chia cho giá trị nhiệt độ.
- Nhiệt độ cao (ví dụ: > 1): Khi nhiệt độ tăng, các logits giảm, dẫn đến đầu ra softmax đồng đều hơn. Điều này tăng cường khả năng mô hình chọn các thuật ngữ ít có khả năng xảy ra hơn, dẫn đến đầu ra đa dạng và sáng tạo hơn, đôi khi có lỗi cao hơn hoặc cụm từ phi logic.
- Nhiệt độ thấp (ví dụ: < 1): Nhiệt độ thấp hơn làm tăng logits, dẫn đến đầu ra softmax tập trung hơn. Do đó, mô hình có nhiều khả năng chọn từ có khả năng xảy ra cao nhất, dẫn đến đầu ra chính xác và bảo thủ hơn với xác suất cao hơn nhưng ít đa dạng hơn.
- Nhiệt độ = 1: Không có sự điều chỉnh tỷ lệ logits khi nhiệt độ được đặt thành 1, giữ nguyên phân phối xác suất cơ bản. Tùy chọn này được coi là cân bằng hoặc trung lập.
Tóm lại, tham số nhiệt độ là một nút điều khiển sự đánh đổi giữa sự đa dạng (nhiệt độ cao) và tính chính xác (nhiệt độ thấp).
Chuỗi Dừng (Stop Sequences)
Chuỗi dừng là các chuỗi ký tự được chỉ định để chấm dứt quá trình tạo văn bản khi chúng xuất hiện trong đầu ra. Các chuỗi này cho phép kiểm soát độ dài và cấu trúc của văn bản được tạo, đảm bảo rằng đầu ra tuân thủ các thông số kỹ thuật.
Hình phạt Tần suất và Hiện diện (Frequency and Presence Penalties)
Hình phạt tần suất và hiện diện là các cơ chế quản lý việc lặp lại từ trong văn bản được tạo. Hình phạt tần suất làm giảm xác suất mô hình sử dụng lại các token xuất hiện lặp đi lặp lại. Hình phạt hiện diện nhằm mục đích ngăn mô hình lặp lại bất kỳ token nào đã xuất hiện trong văn bản, bất kể tần suất của nó.
Pretraining and Fine-Tuning LLMs
Các LLM được pretrained (huấn luyện trước) hấp thụ kiến thức từ lượng lớn dữ liệu văn bản, cho phép chúng thực hiện nhiều nhiệm vụ liên quan đến ngôn ngữ đa dạng. Fine-tuning (tinh chỉnh) giúp tinh lọc các LLM cho các ứng dụng chuyên biệt và cho phép chúng hoàn thành các công việc phức tạp.
Pretraining LLMs
Các LLM được pretrained đã thay đổi đáng kể bối cảnh của AI. Những mô hình này trải qua quá trình huấn luyện trên các tập dữ liệu văn bản khổng lồ được thu thập từ Internet, mài giũa kỹ năng ngôn ngữ của chúng bằng cách dự đoán các từ tiếp theo trong câu. Quá trình huấn luyện sâu rộng này trên hàng tỷ câu cho phép chúng phát triển sự hiểu biết toàn diện về ngữ pháp, ngữ cảnh và ngữ nghĩa, do đó nắm bắt hiệu quả sự tinh tế của ngôn ngữ.
Các LLM được pretrained đã chứng minh tính linh hoạt trong nhiều nhiệm vụ vượt ra ngoài việc tạo văn bản. Điều này đặc biệt rõ ràng trong bài báo GPT-3 năm 2020 “Language Models are Few-Shot Learners.” Nghiên cứu tiết lộ rằng các LLM đủ lớn là “few-shot learners” – có khả năng thực hiện các nhiệm vụ vượt ra ngoài việc tạo văn bản chỉ bằng một vài ví dụ cụ thể của nhiệm vụ để giải mã logic cơ bản của yêu cầu người dùng. Bước đột phá này thể hiện một tiến bộ đáng kể trong lĩnh vực NLP, lĩnh vực trước đây dựa vào các mô hình riêng biệt cho từng nhiệm vụ.
Fine-Tuning LLMs
Fine-tuning là một kỹ thuật cần thiết để cải thiện khả năng của các mô hình pretrained cho các nhiệm vụ chuyên biệt. Mặc dù các Large Language Models (LLMs) được pretrained có sự hiểu biết sâu sắc về ngôn ngữ, nhưng tiềm năng đầy đủ của chúng có thể được nhận ra thông qua fine-tuning.
Fine-tuning biến các LLM thành các chuyên gia bằng cách cho chúng tiếp xúc với các tập dữ liệu cụ thể cho nhiệm vụ. Nó cho phép các mô hình pretrained điều chỉnh các tham số và biểu diễn nội bộ của chúng để phù hợp hơn với nhiệm vụ cụ thể. Sự điều chỉnh phù hợp này cải thiện đáng kể hiệu suất của chúng trên các nhiệm vụ cụ thể theo miền. Ví dụ: một mô hình được fine-tuned trên tập dữ liệu các cặp câu hỏi-trả lời y tế sẽ trả lời hiệu quả các câu hỏi liên quan đến y tế.
Sự cần thiết của fine-tuning xuất phát từ tính chất tổng quát của các mô hình pretrained. Mặc dù chúng có sự hiểu biết rộng rãi về ngôn ngữ, nhưng chúng không vốn có ngữ cảnh cho các nhiệm vụ cụ thể. Ví dụ: fine-tuning trở nên quan trọng khi giải quyết phân tích cảm xúc trong tin tức tài chính.
Instruction Fine-Tuning: Tạo ra Trợ lý Đa năng
Instruction fine-tuning, một hình thức fine-tuning khác, biến mô hình thành một trợ lý đa năng bằng cách thêm quyền kiểm soát hành vi của nó. Nó nhằm mục đích tạo ra một LLM hiểu các tín hiệu như hướng dẫn thay vì văn bản. Ví dụ: hãy xem xét lời nhắc sau.
What is the capital of France?
Một LLM được instruction fine-tuned có khả năng diễn giải lời nhắc như một hướng dẫn và đưa ra câu trả lời sau:
Paris.
Tuy nhiên, một LLM thông thường có thể nghĩ rằng chúng ta đang viết một danh sách các bài tập cho học sinh địa lý của mình và tiếp tục văn bản để tạo ra token có khả năng nhất, có thể là một câu hỏi mới:
What is the capital of Italy?
Instruction fine-tuning mở rộng khả năng của các mô hình. Quá trình này hướng dẫn mô hình tạo ra kết quả phù hợp với tầm nhìn của bạn. Ví dụ: khi bạn nhắc mô hình “Analyze the sentiment of this text and determine if it’s positive, “ bạn hướng dẫn mô hình của mình bằng các lệnh chính xác. Thông qua instruction fine-tuning, các hướng dẫn rõ ràng được đưa ra, định hình hành vi của mô hình để phản ánh các mục tiêu dự định của chúng ta.
Instruction tuning huấn luyện các mô hình trên nhiều nhiệm vụ bằng cách sử dụng hướng dẫn. Điều này cho phép LLMs học cách thực hiện các nhiệm vụ mới được giới thiệu thông qua các hướng dẫn bổ sung. Phương pháp này không yêu cầu lượng lớn dữ liệu cụ thể của nhiệm vụ mà thay vào đó dựa vào các hướng dẫn bằng văn bản để hướng dẫn quá trình học.
Traditional fine-tuning làm quen các mô hình với các tập dữ liệu cụ thể liên quan đến một nhiệm vụ. Instruction fine-tuning tiến xa hơn bằng cách tích hợp các hướng dẫn rõ ràng vào quá trình huấn luyện. Phương pháp này cung cấp cho các nhà phát triển quyền kiểm soát lớn hơn đối với mô hình, cho phép họ định hình kết quả, khuyến khích các hành vi nhất định và hướng dẫn phản hồi của mô hình.
Các Kỹ thuật Fine-Tuning
Nhiều phương pháp tập trung vào thuật toán học được sử dụng cho fine-tuning, chẳng hạn như:
- Full Fine-Tuning: Kỹ thuật này điều chỉnh tất cả các tham số trong một large language model (LLM) được pretrained để điều chỉnh nó cho một nhiệm vụ cụ thể. Mặc dù hiệu quả, full fine-tuning đòi hỏi sức mạnh tính toán đáng kể, khiến nó kém giá trị hơn.
- Low-Rank Adaptation (LoRA): LoRA áp dụng các xấp xỉ xếp hạng thấp trên các lớp hạ lưu của LLMs. Kỹ thuật này tối ưu hóa tài nguyên tính toán và chi phí bằng cách fine-tuning LLMs cho các nhiệm vụ và tập dữ liệu nhất định. Nó giảm đáng kể số lượng tham số cần được huấn luyện, giảm nhu cầu bộ nhớ GPU và tổng chi phí huấn luyện. Ngoài ra, QLoRA, một biến thể của LoRA, giới thiệu tối ưu hóa hơn nữa thông qua lượng tử hóa tham số.
- Supervised Fine-Tuning (SFT): SFT là một phương pháp tiêu chuẩn trong đó một LLM được huấn luyện trải qua quá trình supervised fine-tuning với dữ liệu mẫu hạn chế. Dữ liệu mẫu thường bao gồm dữ liệu trình diễn, lời nhắc và phản hồi tương ứng. Mô hình học từ dữ liệu này và tạo ra các phản hồi phù hợp với đầu ra dự kiến. SFT thậm chí có thể được sử dụng cho Instruction fine-tuning.
- Reinforcement Learning from Human Feedback (RLHF): Phương pháp RLHF huấn luyện các mô hình tăng dần để phù hợp với phản hồi của con người qua nhiều lần lặp. Phương pháp này có thể hiệu quả hơn SFT vì nó tạo điều kiện cải tiến liên tục dựa trên đầu vào của con người. Các phương pháp tương tự bao gồm Direct Preference Optimization (DPO) và Reinforcement Learning from AI Feedback (RLAIF).
Chapter IV: Introduction to Prompting
Prompting and Prompt Engineering
Các mô hình AI tạo sinh (Generative AI) chủ yếu tương tác với người dùng thông qua đầu vào văn bản. Người dùng có thể hướng dẫn mô hình về nhiệm vụ bằng cách cung cấp một mô tả bằng văn bản. Những gì người dùng yêu cầu mô hình thực hiện một cách tổng quát được gọi là “prompt”. “Prompting” là cách con người có thể nói chuyện với trí tuệ nhân tạo (AI). Đó là cách để nói với một tác nhân AI (AI agent) những gì chúng ta muốn và cách chúng ta muốn nó, sử dụng ngôn ngữ con người được điều chỉnh.
Prompt engineering là một ngành học tạo và tối ưu hóa các prompt một cách hiệu quả để tận dụng các mô hình ngôn ngữ trên nhiều ứng dụng và lĩnh vực nghiên cứu khác nhau. Lĩnh vực này rất quan trọng để hiểu những điểm mạnh và hạn chế của các Mô hình Ngôn ngữ Lớn (Large Language Models - LLMs) và đóng một vai trò quan trọng trong nhiều nhiệm vụ xử lý ngôn ngữ tự nhiên (natural language processing - NLP). Một prompt engineer sẽ chuyển đổi ý tưởng của bạn từ ngôn ngữ hội thoại thông thường sang các hướng dẫn chính xác và tối ưu hóa hơn cho AI.
Về bản chất, prompting trình bày một nhiệm vụ hoặc hướng dẫn cụ thể cho mô hình ngôn ngữ, mô hình này sẽ phản hồi dựa trên thông tin trong prompt. Một prompt có thể là một câu hỏi đơn giản hoặc một đầu vào phức tạp hơn với bối cảnh, ví dụ và thông tin bổ sung để hướng dẫn mô hình tạo ra các đầu ra mong muốn. Hiệu quả của kết quả phần lớn phụ thuộc vào độ chính xác và mức độ liên quan của prompt.
Tại sao Prompting lại Quan trọng?
Prompting đóng vai trò là cầu nối giữa con người và AI, cho phép chúng ta giao tiếp và tạo ra kết quả phù hợp với nhu cầu cụ thể của chúng ta. Để tận dụng tối đa khả năng của AI tạo sinh, điều cần thiết là phải biết hỏi gì và hỏi như thế nào. Dưới đây là lý do tại sao prompting lại quan trọng:
- Prompting hướng dẫn mô hình tạo ra đầu ra phù hợp nhất, mạch lạc trong bối cảnh và định dạng cụ thể.
- Nó tăng cường khả năng kiểm soát và giải thích, đồng thời giảm thiểu các thiên kiến tiềm ẩn.
- Các mô hình khác nhau sẽ phản hồi khác nhau đối với cùng một prompt. Biết prompt phù hợp cho mô hình cụ thể sẽ tạo ra kết quả chính xác.
- Các mô hình tạo sinh có thể bị “ảo giác” (hallucinate). Prompting có thể hướng dẫn mô hình đi đúng hướng bằng cách yêu cầu trích dẫn các nguồn chính xác.
- Prompting cho phép thử nghiệm với nhiều loại dữ liệu khác nhau và các cách trình bày dữ liệu khác nhau cho mô hình ngôn ngữ.
- Prompting cho phép xác định kết quả tốt và xấu trông như thế nào bằng cách đưa mục tiêu vào prompt.
- Prompting cải thiện tính an toàn của mô hình và giúp bảo vệ chống lại “hack prompt” (người dùng gửi prompt để tạo ra hành vi không mong muốn từ mô hình).
Integrating Prompting into Code Examples
Tích hợp Prompting vào Ví dụ Mã
Tìm Notebook cho phần này tại towardsai.net/book
Đặt OpenAI API Key trong môi trường của bạn:
import os
os.environ['OPENAI_API_KEY'] = "<OPENAI_API_KEY>"
Ngoài ra, bạn cần cài đặt các gói LangChain và OpenAI để chạy mã trong chương này.
pip install -q langchain==0.0.208 openai==0.27.8
Ví dụ: Tạo Câu chuyện (Story Generation)
Prompt này thiết lập phần đầu của một câu chuyện bằng cách cung cấp bối cảnh ban đầu. Nó mô tả một thế giới nơi động vật có khả năng nói và giới thiệu một nhân vật, một chú chuột dũng cảm tên là Benjamin. Mục tiêu cho model là tiếp tục và hoàn thành câu chuyện, xây dựng dựa trên prompt.
Trong ví dụ này, chúng ta phân biệt giữa prompt_system và prompt. Sự phân biệt này đặc biệt dành cho OpenAI API, sử dụng “system prompt” để điều hướng hành vi của model, không giống như các LLM khác hoạt động với một prompt tiêu chuẩn duy nhất.
import openai
prompt_system = "You are a helpful assistant whose goal is to help write stories."
prompt = """Continue the following story. Write no more than 50 words.
Once upon a time, in a world where animals could speak, a courageous mouse named Benjamin decided to"""
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": prompt_system},
{"role": "user", "content": prompt}
]
)
print(response.choices[0]['message']['content'])
embark on a quest to find the mystical cheese of legends. Along the way, he encountered clever challenges and made unlikely friends with a wise old owl and a mischievous squirrel. The journey tested his bravery and determination, but Benjamin never gave up.
Ví dụ: Mô tả Sản phẩm (Product Description)
Prompt yêu cầu mô tả sản phẩm bao gồm thông tin quan trọng (“luxurious, handcrafted, limited-edition fountain pen made from rosewood and gold”). Mục tiêu là tạo ra mô tả sản phẩm dựa trên các đặc điểm đã cho.
import openai
prompt_system = """You are a helpful assistant whose goal is to help write product descriptions."""
prompt = """Write a captivating product description for a luxurious, handcrafted, limited-edition fountain pen made from rosewood and gold.
Write no more than 50 words."""
response = openai.ChatCompletion.create(
model="gpt-3.5-turbo",
messages=[
{"role": "system", "content": prompt_system},
{"role": "user", "content": prompt}
]
)
print(response.choices[0]['message']['content'])
Indulge in the refined elegance of our limited-edition fountain pen, meticulously handcrafted from lustrous rosewood and accented with opulent gold detailing. This exquisite piece of artistry embodies sophistication and luxury, destined to elevate your writing experience to new heights.
Prompting Techniques
-
Zero-Shot Prompting (Prompting không cần ví dụ)
- Zero-shot prompting là khi một model được yêu cầu tạo ra kết quả mà không có ví dụ minh họa cho nhiệm vụ. Nhiều nhiệm vụ nằm trong khả năng của Large Language Models (LLMs), cho phép chúng cung cấp kết quả xuất sắc ngay cả khi không có ví dụ hoặc hướng dẫn chi tiết. Chúng ta đã thử nghiệm nó trong các ví dụ trước. Dưới đây là một ví dụ khác, nơi LLM được yêu cầu viết một bài thơ ngắn về mùa hè:
import openai prompt_system = "You are a helpful assistant whose goal is to write short poems." prompt = """Write a short poem about {topic}.""" response = openai.ChatCompletion.create( model="gpt-3.5-turbo", messages=[ {"role": "system", "content": prompt_system}, {"role": "user", "content": prompt.format(topic="summer")} ] ) print(response.choices[0]['message']['content'])- Trong trường hợp này, model có thể tạo ra bài thơ theo bất kỳ phong cách nào. Prompt phải bao gồm mô tả rõ ràng hoặc ví dụ để model tạo ra một bài thơ theo một phong cách cụ thể.
-
In-Context Learning And Few-Shot Prompting (Học tập trong ngữ cảnh và Prompting với ít ví dụ)
- In-context learning là một phương pháp mà model học từ các ví dụ hoặc minh họa trong prompt. Few-shot prompting, một tập hợp con của in-context learning, trình bày cho model một tập hợp nhỏ các ví dụ hoặc minh họa liên quan. Chiến lược này giúp model khái quát hóa và cải thiện hiệu suất của nó trên các nhiệm vụ phức tạp hơn.
- Few-shot prompting cho phép các model ngôn ngữ học từ một số lượng mẫu hạn chế. Khả năng thích ứng này cho phép chúng xử lý nhiều nhiệm vụ khác nhau chỉ với một tập hợp nhỏ các mẫu huấn luyện. Không giống như zero-shot, nơi model tạo ra kết quả cho các nhiệm vụ hoàn toàn mới, few-shot prompting tận dụng các ví dụ trong ngữ cảnh để cải thiện hiệu suất.
- Prompt trong kỹ thuật này thường bao gồm nhiều mẫu hoặc đầu vào đi kèm với câu trả lời. Model ngôn ngữ học từ các ví dụ này và áp dụng những gì nó đã học để trả lời các câu hỏi tương tự.
import openai prompt_system = "You are a helpful assistant whose goal is to write short poems." prompt = """Write a short poem about {topic}.""" examples = { "nature": """Birdsong fills the air,\nMountains high and valleys deep,\nNature's music sweet.""", "winter": """Snow blankets the ground,\nSilence is the only sound,\nWinter's beauty found.""" } response = openai.ChatCompletion.create( model="gpt-3.5-turbo", messages=[ {"role": "system", "content": prompt_system}, {"role": "user", "content": prompt.format(topic="nature")}, {"role": "assistant", "content": examples["nature"]}, {"role": "user", "content": prompt.format(topic="winter")}, {"role": "assistant", "content": examples["winter"]}, {"role": "user", "content": prompt.format(topic="summer")} ] ) print(response.choices[0]['message']['content'])- Ví dụ Few-Shot Prompting
- Trong các ví dụ sau, chúng ta sử dụng framework LangChain, giúp tạo điều kiện thuận lợi cho việc sử dụng các kỹ thuật prompt khác nhau. Chúng ta sẽ trình bày framework này trong chương tiếp theo.
- Ở đây, chúng ta hướng dẫn LLM xác định cảm xúc liên quan đến một màu sắc cụ thể. Điều này có thể thực hiện được bằng cách cung cấp một tập hợp các ví dụ minh họa các liên kết màu sắc-cảm xúc.
from langchain import PromptTemplate, FewShotPromptTemplate, LLMChain from langchain.chat_models import ChatOpenAI # Initialize LLM llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0) examples = [ {"color": "red", "emotion": "passion"}, {"color": "blue", "emotion": "serenity"}, {"color": "green", "emotion": "tranquility"}, ] example_formatter_template = """ Color: {color} Emotion: {emotion}\n """ example_prompt = PromptTemplate( input_variables=["color", "emotion"], template=example_formatter_template, ) few_shot_prompt = FewShotPromptTemplate( examples=examples, example_prompt=example_prompt, prefix="""Here are some examples of colors and the emotions associated with them:\n\n""", suffix="""\n\nNow, given a new color, identify the emotion associated with it:\n\nColor: {input}\nEmotion:""", input_variables=["input"], example_separator="\n", ) formatted_prompt = few_shot_prompt.format(input="purple") # Create the LLMChain for the prompt chain = LLMChain(llm=llm, prompt=PromptTemplate(template=formatted_prompt, input_variables=[])) # Run the LLMChain to get the AI-generated emotion associated with the input # color response = chain.run({}) print("Color: purple") print("Emotion:", response)- Giới hạn của Few-shot Prompting
- Mặc dù few-shot learning hiệu quả, nhưng nó gặp phải những thách thức, chủ yếu khi các nhiệm vụ phức tạp. Các chiến lược nâng cao hơn, như chain-of-thought prompting, trở nên ngày càng có giá trị trong những trường hợp như vậy. Kỹ thuật này chia nhỏ các vấn đề phức tạp thành các giai đoạn đơn giản hơn, cung cấp các ví dụ cho từng giai đoạn và nâng cao khả năng suy luận logic của model.
3. Role Prompting (Gợi ý vai trò)
Role prompting liên quan đến việc hướng dẫn LLM (Large Language Model) đảm nhận một vai trò hoặc danh tính cụ thể để thực hiện nhiệm vụ, ví dụ như hoạt động như một copywriter. Hướng dẫn này có thể ảnh hưởng đến phản hồi của mô hình bằng cách cung cấp ngữ cảnh hoặc quan điểm cho nhiệm vụ. Khi làm việc với role prompts, quá trình lặp đi lặp lại bao gồm:
- Xác định vai trò trong prompt. Ví dụ: “Với vai trò là một copywriter, hãy tạo ra những câu khẩu hiệu hấp dẫn cho các dịch vụ của AWS.”
- Sử dụng prompt để tạo ra phản hồi từ LLM.
- Đánh giá phản hồi và tinh chỉnh prompt khi cần thiết để cải thiện kết quả.
Ví dụ:
Trong ví dụ này, LLM được yêu cầu đóng vai trò là một người chỉ huy ban nhạc robot tương lai và tạo ra một tiêu đề bài hát liên quan đến một chủ đề và năm nhất định.
from langchain import PromptTemplate, LLMChain
from langchain.chat_models import ChatOpenAI
# Trước khi thực thi đoạn mã sau, hãy đảm bảo rằng
# khóa OpenAI của bạn đã được lưu trong biến môi trường “OPENAI_API_KEY”.
# Khởi tạo LLM
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
template = """
Với vai trò là một người chỉ huy ban nhạc robot tương lai, tôi cần bạn giúp tôi nghĩ ra một tiêu đề bài hát.
Tiêu đề bài hát hay cho một bài hát về {theme} vào năm {year} là gì?
"""
prompt = PromptTemplate(
input_variables=["theme", "year"],
template=template,
)
# Tạo LLMChain cho prompt
llm = OpenAI(model_name="gpt-3.5-turbo", temperature=0)
# Dữ liệu đầu vào cho prompt
input_data = {"theme": "interstellar travel", "year": "3030"}
# Tạo LLMChain
chain = LLMChain(llm=llm, prompt=prompt)
# Chạy LLMChain để nhận tiêu đề bài hát do AI tạo ra
response = chain.run(input_data)
print("Theme: interstellar travel")
print("Year: 3030")
print("AI-generated song title:", response)
Theme: interstellar travel
Year: 3030
AI-generated song title:
"Journey to the Stars: 3030"
Điều gì tạo nên một prompt tốt:
- Precise Directions (Hướng dẫn chính xác): Prompt được cấu trúc như một yêu cầu đơn giản để tạo tiêu đề bài hát, nêu rõ ngữ cảnh: “Với vai trò là một người chỉ huy ban nhạc robot tương lai.” Sự rõ ràng này giúp LLM nhận ra rằng đầu ra phải là tiêu đề bài hát liên quan đến ngữ cảnh tương lai.
- Specificity (Tính cụ thể): Prompt yêu cầu tiêu đề bài hát liên quan đến một chủ đề và năm cụ thể, “{theme} vào năm {year}.” Mức độ chi tiết này cho phép LLM tạo ra phản hồi phù hợp và giàu trí tưởng tượng. Tính linh hoạt của prompt để đáp ứng các chủ đề và năm khác nhau thông qua các biến đầu vào làm tăng tính linh hoạt và khả năng áp dụng của nó.
- Promoting Creativity (Khuyến khích sự sáng tạo): Prompt không giới hạn LLM vào một định dạng hoặc phong cách cụ thể cho tiêu đề bài hát, khuyến khích nhiều phản hồi sáng tạo dựa trên chủ đề và năm được chỉ định.
- Concentrated on the Task (Tập trung vào nhiệm vụ): Prompt chỉ tập trung vào việc tạo tiêu đề bài hát, đơn giản hóa quy trình LLM để đưa ra phản hồi phù hợp mà không bị phân tán bởi các chủ đề không liên quan. Việc tích hợp nhiều nhiệm vụ trong một prompt có thể gây nhầm lẫn cho mô hình, có khả năng làm giảm hiệu quả của nó trong từng nhiệm vụ.
Những đặc điểm này hỗ trợ LLM hiểu ý định của người dùng và tạo ra phản hồi phù hợp.
4. Chain Prompting (Gợi ý chuỗi)
Chain Prompting liên quan đến việc liên kết một chuỗi các prompts tuần tự, trong đó đầu ra từ prompt này đóng vai trò là đầu vào cho prompt tiếp theo. Khi triển khai chain prompting với LangChain, hãy xem xét các bước sau:
- Xác định và trích xuất thông tin liên quan từ phản hồi được tạo.
- Phát triển một prompt mới sử dụng thông tin được trích xuất này, đảm bảo nó xây dựng dựa trên phản hồi trước đó.
- Tiếp tục quy trình này khi cần thiết để đạt được kết quả dự định.
Lớp PromptTemplate được thiết kế để đơn giản hóa việc tạo prompts với đầu vào động. Tính năng này đặc biệt hữu ích trong việc xây dựng một chuỗi prompt dựa trên phản hồi từ các prompts trước đó.
from langchain import PromptTemplate, LLMChain
from langchain.chat_models import ChatOpenAI
# Khởi tạo LLM
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
# Prompt 1
template_question = """What is the name of the famous scientist who developed the theory of general relativity?
Answer: """
prompt_question = PromptTemplate(template=template_question, input_variables=[])
# Prompt 2
template_fact = """Provide a brief description of {scientist}'s theory of general relativity.
Answer: """
prompt_fact = PromptTemplate(input_variables=["scientist"],
template=template_fact)
# Tạo LLMChain cho prompt đầu tiên
chain_question = LLMChain(llm=llm, prompt=prompt_question)
# Chạy LLMChain cho prompt đầu tiên với một từ điển trống
response_question = chain_question.run({})
# Trích xuất tên nhà khoa học từ phản hồi
scientist = response_question.strip()
# Tạo LLMChain cho prompt thứ hai
chain_fact = LLMChain(llm=llm, prompt=prompt_fact)
# Dữ liệu đầu vào cho prompt thứ hai
input_data = {"scientist": scientist}
# Chạy LLMChain cho prompt thứ hai
response_fact = chain_fact.run(input_data)
print("Scientist:", scientist)
print("Fact:", response_fact)
Scientist: Albert Einstein
Fact:
Albert Einstein's theory of general relativity is a theory of gravitation that states that the gravitational force between two objects results from the curvature of spacetime caused by the presence of mass and energy. It explains the phenomenon of gravity as a result of the warping of space and time by matter and energy.
Trong ví dụ trên, prompt đầu tiên yêu cầu tên của nhà khoa học, và prompt thứ hai sử dụng tên đó để yêu cầu một mô tả về lý thuyết của ông. Quá trình này thể hiện cách chain prompting cho phép LLM xây dựng trên các phản hồi trước đó để cung cấp thông tin chi tiết hơn.
5. Chain of Thought Prompting (Gợi ý chuỗi suy luận)
Chain of Thought Prompting (CoT) là một phương pháp được thiết kế để gợi ý cho Large Language Models (LLMs) trình bày rõ ràng quá trình suy nghĩ của chúng, nâng cao độ chính xác của kết quả. Kỹ thuật này bao gồm việc trình bày các ví dụ thể hiện quá trình lý luận, hướng dẫn LLM giải thích logic của nó trong khi phản hồi các prompts. CoT đã được chứng minh là có lợi cho các nhiệm vụ số học, lý luận thông thường và tư duy tượng trưng.
Trong bối cảnh của LangChain, CoT mang lại một số lợi thế. Thứ nhất, nó đơn giản hóa các nhiệm vụ phức tạp bằng cách cho phép LLM chia nhỏ các vấn đề khó khăn thành các bước dễ quản lý hơn. Tính năng này có giá trị đối với các nhiệm vụ yêu cầu tính toán, phân tích logic hoặc lý luận nhiều bước. Thứ hai, CoT có thể hướng dẫn mô hình thông qua một loạt các prompts liên quan, thúc đẩy đầu ra mạch lạc và phù hợp với ngữ cảnh hơn. Điều này có thể dẫn đến các phản hồi chính xác và thiết thực hơn, đặc biệt là trong các nhiệm vụ yêu cầu hiểu biết thấu đáo về vấn đề hoặc chủ đề.
Tuy nhiên, có những hạn chế đối với CoT cần được xem xét. Một hạn chế là nó có hiệu quả chủ yếu với các mô hình có khoảng 100 tỷ tham số trở lên. Các mô hình nhỏ hơn thường tạo ra các quá trình suy nghĩ vô nghĩa, làm giảm độ chính xác so với các phương pháp prompting truyền thống. Một hạn chế khác là hiệu quả của CoT khác nhau đối với các loại nhiệm vụ khác nhau. Mặc dù nó cho thấy những lợi ích đáng kể đối với các nhiệm vụ liên quan đến số học, lý luận thông thường và tư duy tượng trưng, nhưng tác động của nó đối với các nhiệm vụ khác có thể ít ý nghĩa hơn.
Bad Prompt Practices
Phần sau đây khám phá các ví dụ về các prompt mà thường không hiệu quả. Ví dụ, một prompt quá mơ hồ, thiếu ngữ cảnh hoặc hướng dẫn đầy đủ sẽ cản trở khả năng tạo ra phản hồi có ý nghĩa của model.
from langchain import PromptTemplate
template = "Hãy nói cho tôi điều gì đó về {topic}."
prompt = PromptTemplate(
input_variables=["topic"],
template=template,
)
prompt.format(topic="dogs")
'Hãy nói cho tôi điều gì đó về dogs.’
Giống như ví dụ trước, prompt sau đây có thể dẫn đến phản hồi kém thông tin hoặc kém tập trung do cấu trúc rộng và mở của nó. Model tạo ra một phản hồi chính xác về mặt thực tế, nhưng nó có thể nằm ngoài chủ đề cụ thể.
from langchain import PromptTemplate, LLMChain
from langchain.chat_models import ChatOpenAI
# Khởi tạo LLM
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
# Prompt 1
template_question = """Tên của nhà khoa học nổi tiếng nào đã phát triển thuyết tương đối rộng?
Trả lời: """
prompt_question = PromptTemplate(template=template_question, input_variables=[])
# Prompt 2
template_fact = """Hãy nói cho tôi điều gì đó thú vị về {scientist}.
Trả lời: """
prompt_fact = PromptTemplate(input_variables=["scientist"],
template=template_fact)
# Tạo LLMChain cho prompt đầu tiên
chain_question = LLMChain(llm=llm, prompt=prompt_question)
# Chạy LLMChain cho prompt đầu tiên với một dictionary trống
response_question = chain_question.run({})
# Trích xuất tên nhà khoa học từ phản hồi
scientist = response_question.strip()
# Tạo LLMChain cho prompt thứ hai
chain_fact = LLMChain(llm=llm, prompt=prompt_fact)
# Dữ liệu đầu vào cho prompt thứ hai
input_data = {"scientist": scientist}
# Chạy LLMChain cho prompt thứ hai
response_fact = chain_fact.run(input_data)
print("Scientist:", scientist)
print("Fact:", response_fact)
Scientist: Albert Einstein
Fact: Albert Einstein là một người ăn chay và là người ủng hộ quyền động vật. Ông cũng là một người theo chủ nghĩa hòa bình và một người theo chủ nghĩa xã hội, và ông là một người ủng hộ mạnh mẽ phong trào dân quyền. Ông cũng là một nghệ sĩ violin đam mê và một người yêu thích thuyền buồm.
Prompt sau đây có thể dẫn đến phản hồi ít chi tiết hoặc ít mục tiêu hơn, chủ yếu là do cách tiếp cận mở hơn của nó:
from langchain import PromptTemplate, LLMChain
from langchain.chat_models import ChatOpenAI
# Khởi tạo LLM
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
# Prompt 1
template_question = """Một số thể loại âm nhạc là gì?
Trả lời: """
prompt_question = PromptTemplate(template=template_question, input_variables=[])
# Prompt 2
template_fact = """Hãy nói cho tôi điều gì đó về {genre1}, {genre2} và {genre3} mà không cung cấp bất kỳ chi tiết cụ thể nào.
Trả lời: """
prompt_fact = PromptTemplate(input_variables=["genre1", "genre2", "genre3"],
template=template_fact)
# Tạo LLMChain cho prompt đầu tiên
chain_question = LLMChain(llm=llm, prompt=prompt_question)
# Chạy LLMChain cho prompt đầu tiên với một dictionary trống
response_question = chain_question.run({})
# Gán ba thể loại được hardcode
genre1, genre2, genre3 = "jazz", "pop", "rock"
# Tạo LLMChain cho prompt thứ hai
chain_fact = LLMChain(llm=llm, prompt=prompt_fact)
# Dữ liệu đầu vào cho prompt thứ hai
input_data = {"genre1": genre1, "genre2": genre2, "genre3": genre3}
# Chạy LLMChain cho prompt thứ hai
response_fact = chain_fact.run(input_data)
print("Genres:", genre1, genre2, genre3)
print("Fact:", response_fact)
Genres: jazz pop rock
Fact:
Jazz, pop và rock đều là những thể loại nhạc phổ biến đã tồn tại hàng thập kỷ. Chúng đều có âm thanh và phong cách riêng biệt, và đã ảnh hưởng lẫn nhau theo nhiều cách khác nhau. Jazz thường được đặc trưng bởi sự ngẫu hứng (improvisation), hòa âm phức tạp (complex harmonies) và nhịp điệu lệch (syncopated rhythms). Nhạc pop thường dễ tiếp cận hơn và thường có giai điệu và hook bắt tai. Nhạc rock thường được đặc trưng bởi guitar méo tiếng (distorted guitars), trống nặng (heavy drums) và giọng hát mạnh mẽ (powerful vocals).
Trong ví dụ này, prompt thứ hai không hiệu quả. Nó yêu cầu “hãy nói cho tôi điều gì đó về {genre1}, {genre2} và {genre3} mà không cung cấp bất kỳ chi tiết cụ thể nào.” Hướng dẫn mâu thuẫn này tạo ra sự mơ hồ, khiến LLM khó tạo ra phản hồi mạch lạc và giàu thông tin. Do đó, đầu ra từ LLM có thể ít thông tin và gây nhầm lẫn.
Prompt ban đầu yêu cầu thông tin về “một số thể loại âm nhạc” mà không chỉ định bất kỳ tiêu chí hoặc ngữ cảnh nào. Tiếp theo, prompt thứ hai hỏi về tính độc đáo của các thể loại được chỉ định mà không cung cấp bất kỳ hướng dẫn nào về khía cạnh độc đáo nào cần tập trung, chẳng hạn như nguồn gốc lịch sử, yếu tố phong cách hoặc tác động văn hóa.
Tips for Effective Prompt Engineering
Kỹ thuật prompt là một quá trình lặp đi lặp lại, thường yêu cầu nhiều điều chỉnh để đạt được phản hồi chính xác nhất. Khi LLMs (Large Language Models) tiếp tục được tích hợp vào các sản phẩm và dịch vụ khác nhau, thành thạo trong việc thiết kế các prompt hiệu quả sẽ trở nên rất quan trọng. Dưới đây là các quy tắc chung cần tuân theo:
- Hãy cụ thể với prompt của bạn: Bao gồm đủ ngữ cảnh và chi tiết để hướng dẫn LLM đến kết quả dự định.
- Buộc sự ngắn gọn khi cần thiết.
- Khuyến khích mô hình mô tả lý do tại sao nó lại như vậy: Điều này có thể dẫn đến các giải pháp chính xác hơn, đặc biệt đối với các nhiệm vụ phức tạp.
from langchain import FewShotPromptTemplate, PromptTemplate, LLMChain
from langchain.chat_models import ChatOpenAI
# Initialize LLM
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
examples = [
{
"query": "What's the secret to happiness?",
"answer": """Finding balance in life and learning to enjoy the small moments."""
}, {
"query": "How can I become more productive?",
"answer": """Try prioritizing tasks, setting goals, and maintaining a healthy work-life balance."""
}
]
example_template = """
User: {query}
AI: {answer}
"""
example_prompt = PromptTemplate(
input_variables=["query", "answer"],
template=example_template
)
prefix = """The following are excerpts from conversations with an AI
life coach. The assistant provides insightful and practical advice to the \users' questions. Here are some examples:
"""
suffix = """
User: {query}
AI: """
few_shot_prompt_template = FewShotPromptTemplate(
examples=examples,
example_prompt=example_prompt,
prefix=prefix,
suffix=suffix,
input_variables=["query"],
example_separator="\n\n"
)
# Create the LLMChain for the few-shot prompt template
chain = LLMChain(llm=llm, prompt=few_shot_prompt_template)
# Define the user query
user_query = "What are some tips for improving communication skills?"
# Run the LLMChain for the user query
response = chain.run({"query": user_query})
print("User Query:", user_query)
print("AI Response:", response)
Giải thích mã Python:
- Đoạn mã này sử dụng thư viện
langchainvà mô hìnhChatOpenAIđể tạo một chuỗi (chain) tương tác với LLM. examples: Định nghĩa các ví dụ về câu hỏi và câu trả lời để hướng dẫn LLM. Đây là dạng Few-Shot Prompt Template.example_template: Định nghĩa cấu trúc của từng ví dụ.example_prompt: Tạo mộtPromptTemplatetừexample_template.prefix: Phần đầu của prompt, thiết lập ngữ cảnh rằng AI là một “life coach”.suffix: Phần cuối của prompt, chỉ ra nơi người dùng nhập câu hỏi và AI đưa ra câu trả lời.few_shot_prompt_template: Kết hợp các ví dụ, prefix và suffix để tạo prompt hoàn chỉnh.chain: Tạo mộtLLMChainđể chạy prompt với LLM.user_query: Câu hỏi của người dùng.response: Kết quả trả về từ LLM.
Kết quả:
User Query: What are some tips for improving communication skills?
AI Response: Practice active listening, be mindful of your body language, and be open to constructive feedback.
Phân tích Chi Tiết Prompt:
Hãy xem xét kỹ hơn prompt trên. Với prompt được cấu trúc tốt này, AI có thể hiểu vai trò, ngữ cảnh và định dạng phản hồi mong đợi, dẫn đến kết quả chính xác và có giá trị hơn.
- Thiết lập Ngữ Cảnh Rõ Ràng trong Prefix: Bằng cách nói rằng AI đóng vai trò là một “life coach” đưa ra lời khuyên sâu sắc và thiết thực, prompt cung cấp một khung hướng dẫn các phản hồi của AI phù hợp với mục đích dự định.
- Sử dụng Ví dụ (Utilizes Examples): Prompt bao gồm các ví dụ minh họa vai trò của AI và thể hiện các phản hồi mong đợi. Những ví dụ này cho phép AI hiểu giọng điệu và phong cách mà nó nên mô phỏng, đảm bảo các phản hồi của nó nhất quán với ngữ cảnh được cung cấp.
- Phân biệt giữa Ví dụ và Câu hỏi Thực tế (Distinguishes Between Examples and the Actual Query): Bằng cách tách biệt rõ ràng các ví dụ khỏi câu hỏi của người dùng, prompt giúp AI hiểu định dạng mà nó nên tuân theo. Sự phân biệt này cho phép AI tập trung vào câu hỏi hiện tại và phản hồi một cách thích hợp.
- Bao gồm Suffix Rõ Ràng cho Đầu vào của Người dùng và Phản hồi của AI (Includes a Clear Suffix for User Input and AI Response): Suffix là một dấu hiệu, cho biết sự kết thúc đầu vào của người dùng và sự bắt đầu phản hồi của AI. Yếu tố cấu trúc này hỗ trợ duy trì định dạng rõ ràng và nhất quán cho các phản hồi.
Với cấu trúc được thiết kế tốt, prompt này đảm bảo rằng AI hiểu vai trò, ngữ cảnh tương tác và định dạng phản hồi mong đợi, do đó dẫn đến kết quả chính xác và có giá trị hơn.
Chapter V: Introduction to LangChain & LlamaIndex
LangChain Introduction
LangChain là một framework mã nguồn mở được thiết kế để đơn giản hóa việc phát triển, sản xuất hóa và triển khai các ứng dụng được hỗ trợ bởi Mô hình Ngôn ngữ Lớn (LLMs). Nó cung cấp một tập hợp các khối xây dựng, thành phần và tích hợp để đơn giản hóa mọi giai đoạn của vòng đời ứng dụng LLM.
Các tính năng chính:
- Abstractions và LangChain Expression Language (LCEL) để tạo các chuỗi (chains).
- Third-party integrations và partner packages để dễ dàng mở rộng.
- Chains, agents và retrieval strategies để xây dựng các kiến trúc nhận thức.
- LangGraph: để tạo các ứng dụng đa tác nhân (multi-actor applications) mạnh mẽ, có trạng thái (stateful).
- LangServe: để triển khai các chuỗi LangChain dưới dạng API REST.
Hệ sinh thái LangChain rộng lớn hơn cũng bao gồm LangSmith, một nền tảng phát triển để gỡ lỗi, kiểm tra, đánh giá và giám sát các ứng dụng LLM.
Vai trò của LangChain trong Retrieval-Augmented Generation (RAG)
Retrieval-augmented generation (RAG) là một kỹ thuật hữu ích để giải quyết một trong những thách thức chính liên quan đến Mô hình Ngôn ngữ Lớn (LLMs): ảo giác (hallucinations). Bằng cách tích hợp các nguồn kiến thức bên ngoài, hệ thống RAG có thể cung cấp cho LLMs thông tin liên quan, thực tế trong quá trình tạo. Điều này đảm bảo rằng các đầu ra được tạo ra chính xác hơn, đáng tin cậy hơn và phù hợp với ngữ cảnh hơn. Chúng ta sẽ đi sâu hơn về các phương pháp RAG trong chương 7 và 8.
LangChain cung cấp các abstractions hữu ích để xây dựng hệ thống RAG. Với các thành phần truy xuất (retrieval components) của LangChain, các nhà phát triển có thể dễ dàng tích hợp các nguồn dữ liệu bên ngoài, chẳng hạn như tài liệu hoặc cơ sở dữ liệu, vào các ứng dụng được hỗ trợ bởi LLM của họ. Điều này cho phép các mô hình truy cập và sử dụng thông tin liên quan trong quá trình tạo, cho phép đầu ra chính xác hơn.
Các khái niệm và thành phần chính của LangChain:
- Prompts: LangChain cung cấp các công cụ để tạo và làm việc với prompt templates. Prompt templates là các công thức được xác định trước để tạo prompts cho các mô hình ngôn ngữ.
- Output Parsers: Output parsers là các lớp giúp cấu trúc các phản hồi của mô hình ngôn ngữ. Chúng chịu trách nhiệm lấy đầu ra của LLM và chuyển đổi nó thành một định dạng phù hợp hơn.
- Retrievers: Retrievers chấp nhận một truy vấn chuỗi (string query) làm đầu vào và trả về một danh sách các
Documentslàm đầu ra. LangChain cung cấp một số loại truy xuất nâng cao và cũng tích hợp với nhiều dịch vụ truy xuất của bên thứ ba. - Document Loaders: Một
Documentlà một đoạn văn bản và siêu dữ liệu liên quan. Document loaders cung cấp một phương thức “load” để tải dữ liệu dưới dạng tài liệu từ một nguồn được cấu hình. - Text Splitters: Text splitters chia một tài liệu hoặc văn bản thành các đoạn hoặc phân đoạn nhỏ hơn. LangChain có một số document transformers được tích hợp sẵn có thể chia, kết hợp và lọc tài liệu.
- Indexes: Một index trong LangChain là một cấu trúc dữ liệu tổ chức và lưu trữ dữ liệu để tạo điều kiện tìm kiếm nhanh chóng và hiệu quả.
- Embeddings models: Lớp Embeddings được thiết kế để giao tiếp với các mô hình nhúng văn bản (text embedding models). Nó cung cấp một giao diện tiêu chuẩn cho các nhà cung cấp mô hình nhúng khác nhau, chẳng hạn như OpenAI, Cohere, Hugging Face, v.v.
- Vector Stores: Một vector store lưu trữ dữ liệu được nhúng và thực hiện tìm kiếm vector. Nhúng và lưu trữ các vector nhúng là một trong những cách phổ biến nhất để lưu trữ và tìm kiếm dữ liệu phi cấu trúc.
- Agents: Agents là các thành phần ra quyết định quyết định kế hoạch hành động hoặc quy trình.
- Chains: Chúng là các chuỗi lệnh gọi, cho dù đến LLM, một công cụ hoặc một bước tiền xử lý dữ liệu. Chúng tích hợp các thành phần khác nhau vào một giao diện thân thiện với người dùng, bao gồm mô hình, prompt, memory, output parsing và khả năng gỡ lỗi.
- Tool: Một tool là một hàm cụ thể giúp mô hình ngôn ngữ thu thập thông tin cần thiết để hoàn thành nhiệm vụ. Các công cụ có thể bao gồm từ Tìm kiếm Google và truy vấn cơ sở dữ liệu đến Python
REPLvà các chuỗi khác. - Memory: Tính năng này ghi lại các tương tác trước đây với mô hình ngôn ngữ, cung cấp ngữ cảnh cho các tương tác trong tương lai.
- Callbacks: LangChain cung cấp một hệ thống callbacks cho phép bạn kết nối với các giai đoạn khác nhau của ứng dụng LLM của mình. Điều này hữu ích cho việc ghi nhật ký, giám sát và truyền phát.
Trong suốt cuốn sách, chúng ta sẽ đề cập đến từng thành phần và sử dụng nó để xây dựng các ứng dụng dựa trên RAG.
LangChain Agents & Tools Overview
Agents là gì?
LangChain agents hoàn thành các nhiệm vụ bằng cách sử dụng chains, prompts, memory và tools. Những agents này có thể thực hiện nhiều nhiệm vụ đa dạng, bao gồm thực hiện các bước theo trình tự định sẵn, giao tiếp với các hệ thống bên ngoài như Gmail hoặc cơ sở dữ liệu SQL, và nhiều hơn nữa. Trong Chương 9, chúng ta sẽ thảo luận sâu hơn về việc xây dựng agents.
LangChain cung cấp một loạt các công cụ và tính năng để hỗ trợ tùy chỉnh agents cho nhiều ứng dụng khác nhau.
Các loại Agent
LangChain có nhiều loại agent khác nhau, mỗi loại có các chức năng chuyên biệt.
- Zero-shot ReAct: Agent này sử dụng framework ReAct để quyết định việc sử dụng tool dựa trên các mô tả. Nó được gọi là “zero-shot” vì nó chỉ dựa vào các mô tả tool mà không cần các ví dụ sử dụng cụ thể.
- Structured Input ReAct: Agent này quản lý các tools yêu cầu nhiều đầu vào.
- OpenAI Functions Agent: Agent này được phát triển đặc biệt cho các lời gọi hàm (function calls) cho các mô hình tinh chỉnh (fine-tuned models) và tương thích với các mô hình tiên tiến như gpt-3.5-turbo và gpt-4-turbo.
- Self-Ask with Search Agent: Agent này tìm nguồn phản hồi thực tế cho các câu hỏi, chuyên về tool “Intermediate Answer”. Nó tương tự như phương pháp trong nghiên cứu self-ask with search gốc.
- ReAct Document Store Agent: Agent này kết hợp các tools “Search” và “Lookup” để cung cấp một quá trình suy nghĩ liên tục.
- Plan-and-Execute Agents: Loại này xây dựng một kế hoạch bao gồm nhiều hành động, sau đó được thực hiện tuần tự. Các agents này đặc biệt hiệu quả cho các nhiệm vụ phức tạp hoặc dài hạn, duy trì sự tập trung ổn định vào các mục tiêu dài hạn. Tuy nhiên, một sự đánh đổi khi sử dụng các agents này là khả năng tăng độ trễ (latency).
Các agents về cơ bản xác định logic đằng sau việc chọn một hành động và quyết định có nên sử dụng nhiều tools, một tool đơn lẻ hay không, dựa trên nhiệm vụ.
Các Tools có sẵn và Custom Tools
Một danh sách các tools tích hợp LangChain với các tools khác có thể truy cập tại phần Toolkits trong tài liệu LangChain. Một số ví dụ là:
- The Python tool: Nó được sử dụng để tạo và thực thi mã Python để trả lời một câu hỏi.
- The JSON tool: Nó được sử dụng khi tương tác với một tệp JSON không phù hợp với cửa sổ ngữ cảnh (context window) của LLM.
- The CSV tool: Nó được sử dụng để tương tác với các tệp CSV.
Custom tools tăng cường tính linh hoạt của agents, cho phép chúng được điều chỉnh cho các nhiệm vụ và tương tác cụ thể. Những tools này cung cấp chức năng dành riêng cho nhiệm vụ và tính linh hoạt cho các hành vi phù hợp với các trường hợp sử dụng độc đáo.
Mức độ tùy chỉnh phụ thuộc vào sự phát triển của các tương tác nâng cao. Trong những trường hợp như vậy, các tools có thể được phối hợp để thực hiện các hành vi phức tạp. Ví dụ bao gồm tạo câu hỏi, thực hiện tìm kiếm trên web để tìm câu trả lời và biên soạn tóm tắt thông tin.
💡 Các trang tài liệu cho các thành phần LangChain, agents và tools có thể truy cập tại towardsai.net/book.
Building LLM-Powered Applications with LangChain
Prompt Templates
LangChain cung cấp các công cụ tiêu chuẩn để tương tác với LLM. ChatPromptTemplate được sử dụng để cấu trúc các cuộc trò chuyện với các mô hình AI, hỗ trợ kiểm soát luồng và nội dung của cuộc trò chuyện. LangChain sử dụng message prompt templates để xây dựng và làm việc với các prompt, tối đa hóa tiềm năng của mô hình chat cơ bản.
Các loại prompt khác nhau phục vụ các mục đích khác nhau trong tương tác với các mô hình chat. SystemMessagePromptTemplate cung cấp hướng dẫn ban đầu, ngữ cảnh hoặc dữ liệu cho mô hình AI. Ngược lại, HumanMessagePromptTemplate bao gồm các tin nhắn của người dùng mà mô hình AI trả lời.
Để minh họa, chúng ta sẽ tạo một trợ lý dựa trên chat để tìm thông tin về phim. Đầu tiên, lưu trữ khóa OpenAI API của bạn trong các biến môi trường dưới “OPENAI_API_KEY” và đảm bảo các gói cần thiết được cài đặt bằng lệnh: pip install langchain==0.0.208 deeplake openai==0.27.8 tiktoken.
from langchain.chat_models import ChatOpenAI
from langchain.prompts.chat import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
HumanMessagePromptTemplate,
)
# Trước khi thực thi đoạn mã sau, hãy đảm bảo bạn đã lưu khóa OpenAI của mình trong biến môi trường "OPENAI_API_KEY".
chat = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
template = "You are an assistant that helps users find information about movies."
system_message_prompt = SystemMessagePromptTemplate.from_template(template)
human_template = "Find information about the movie {movie_title}."
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])
response = chat(chat_prompt.format_prompt(movie_title="Inception").to_messages())
print(response.content)
Inception is a 2010 science fiction action film directed by Christopher Nolan. The film stars Leonardo DiCaprio, Ken Watanabe, Joseph Gordon-Levitt, Ellen Page, Tom Hardy, Dileep Rao, Cillian Murphy, Tom Berenger, and Michael Caine. The plot follows a professional thief who steals information by infiltrating the subconscious of his targets. He is offered a chance to have his criminal history erased as payment for the implantation of another person's idea into a target's subconscious. The film was a critical and commercial success, grossing over $829 million worldwide and receiving numerous accolades, including four Academy Awards.
Đối tượng to_messages trong LangChain là một công cụ thực tế để chuyển đổi giá trị đã định dạng của một chat prompt template thành một danh sách các đối tượng tin nhắn. Chức năng này đặc biệt có lợi khi làm việc với các mô hình chat, cung cấp một phương pháp có cấu trúc để giám sát cuộc trò chuyện. Điều này đảm bảo rằng mô hình chat hiểu hiệu quả ngữ cảnh và vai trò của các tin nhắn.
Summarization Chain Example
Một chuỗi tóm tắt (summarization chain) tương tác với các nguồn dữ liệu bên ngoài để truy xuất thông tin sử dụng trong giai đoạn tạo nội dung. Quá trình này có thể bao gồm việc cô đọng văn bản mở rộng hoặc sử dụng các nguồn dữ liệu cụ thể để trả lời câu hỏi.
Để khởi tạo quá trình này, mô hình ngôn ngữ được cấu hình bằng lớp OpenAI với cài đặt nhiệt độ (temperature) là 0, cho đầu ra hoàn toàn xác định (deterministic). Hàm load_summarize_chain nhận một instance của mô hình ngôn ngữ và thiết lập một chuỗi tóm tắt được xây dựng sẵn. Hơn nữa, lớp PyPDFLoader tải các tệp PDF và chuyển đổi chúng thành định dạng mà LangChain có thể xử lý hiệu quả.
Điều quan trọng là phải cài đặt gói pypdf để thực thi mã sau. Mặc dù nên sử dụng phiên bản mới nhất của gói này, mã đã được kiểm tra với phiên bản 3.10.0.
# Import necessary modules
from langchain.chat_models import ChatOpenAI
from langchain import PromptTemplate
from langchain.chains.summarize import load_summarize_chain
from langchain.document_loaders import PyPDFLoader
# Initialize language model
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
# Load the summarization chain
summarize_chain = load_summarize_chain(llm)
# Load the document using PyPDFLoader
document_loader = PyPDFLoader(file_path="path/to/your/pdf/file.pdf")
document = document_loader.load()
# Summarize the document
summary = summarize_chain(document)
print(summary['output_text'])
Tài liệu này cung cấp một bản tóm tắt các lệnh Linux hữu ích để khởi động và dừng, truy cập và gắn kết hệ thống tệp, tìm tệp và văn bản trong tệp, Hệ thống X Window, di chuyển, sao chép, xóa và xem tệp, cài đặt phần mềm, quản trị người dùng, các mẹo và thủ thuật ít được biết đến, tệp cấu hình và chức năng của chúng, quyền tệp, phím tắt X, in và liên kết đến một “Linux pocket protector” chính thức.
💡 Đầu ra trên dựa trên tệp PDF “The One Page Linux Manual” có thể truy cập tại towardsai.net/book.
Trong ví dụ này, mã sử dụng chuỗi tóm tắt tiêu chuẩn thông qua hàm load_summarize_chain. Tuy nhiên, các mẫu prompt tùy chỉnh (custom prompt templates) cũng có thể được cung cấp để điều chỉnh quá trình tóm tắt.
QA Chain Example
LangChain có thể cấu trúc các prompt theo nhiều cách, bao gồm việc đặt các câu hỏi chung cho các mô hình ngôn ngữ.
⚠️ Hãy lưu ý về khả năng gây ảo giác (hallucinations) và các trường hợp mô hình có thể tạo ra thông tin không có thật. Chúng ta có thể triển khai hệ thống tạo sinh tăng cường truy xuất (retrieval-augmented generation system) để giảm thiểu vấn đề này. Trong Chương 7, chúng ta sẽ thấy cách LangChain có thể giúp chúng ta triển khai một hệ thống như vậy với Chuỗi Truy xuất (Retrieval Chain).
Chúng ta thiết lập một mẫu prompt tùy chỉnh (customized prompt template) bằng cách khởi tạo một instance của lớp PromptTemplate. Chuỗi template này kết hợp một placeholder {question} cho truy vấn đầu vào, theo sau là một ký tự dòng mới và thẻ “Answer:”. Tham số input_variables được gán cho một danh sách các placeholder hiện có trong prompt (một câu hỏi trong trường hợp này) để biểu thị tên biến và chúng sẽ được thay thế bằng đối số đầu vào bằng phương thức .run() của template.
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from langchain.chat_models import ChatOpenAI
prompt = PromptTemplate(template="Question: {question}\nAnswer:",
input_variables=["question"])
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
chain = LLMChain(llm=llm, prompt=prompt)
Tiếp theo, một instance của mô hình OpenAI gpt-3.5-turbo được tạo ra, với cài đặt nhiệt độ (temperature) là 0 cho đầu ra hoàn toàn xác định (fully deterministic outputs). Instance này được tạo bằng lớp OpenAI, với các tham số model_name và temperature được chỉ định. Sau đó, một chuỗi hỏi đáp (question-answering chain) được thiết lập bằng lớp LLMChain. Constructor của lớp LLMChain yêu cầu hai đối số: llm, instance của mô hình OpenAI, và prompt, mẫu prompt tùy chỉnh đã tạo trước đó.
Việc thực hiện các bước này cho phép xử lý hiệu quả các câu hỏi đầu vào bằng chuỗi hỏi đáp tùy chỉnh. Thiết lập này cho phép tạo ra các câu trả lời liên quan bằng cách tận dụng mô hình OpenAI kết hợp với mẫu prompt tùy chỉnh.
chain.run("what is the meaning of life?")
'The meaning of life is subjective and can vary from person to person. For some, it may be to find happiness and fulfillment, while for others it may be to make a difference in the world. Ultimately, the meaning of life is up to each individual to decide.'
Ví dụ này minh họa cách LangChain cho phép tích hợp các mẫu prompt cho các ứng dụng hỏi đáp. Framework này có thể được mở rộng để bao gồm các thành phần bổ sung, chẳng hạn như tạo sinh tăng cường dữ liệu (data-augmented generation), agents hoặc các tính năng bộ nhớ (memory features), để phát triển các ứng dụng phức tạp hơn.
Building a News Articles Summarizer
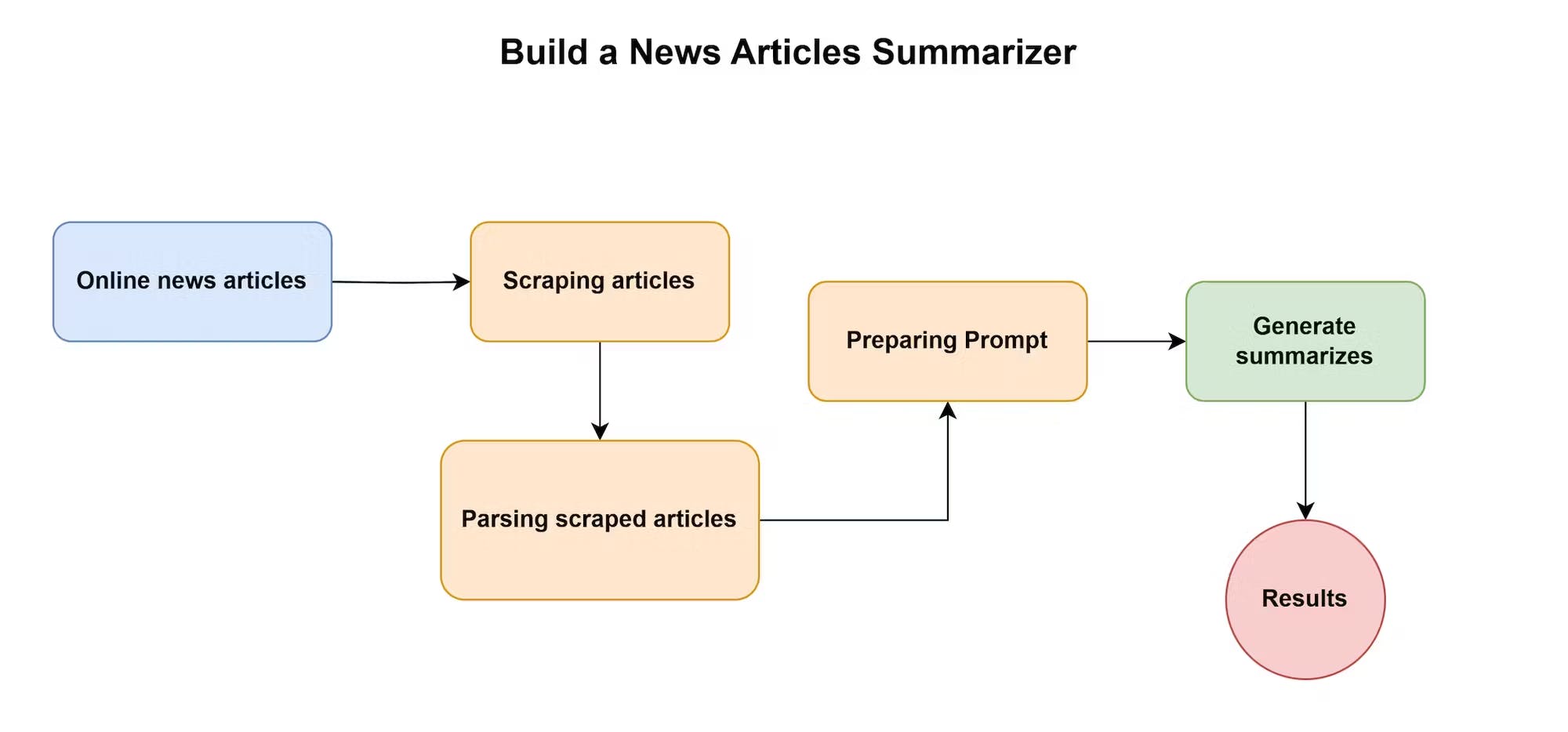
import json
from dotenv import load_dotenv
load_dotenv()
import requests
from newspaper import Article
headers = { 'User-Agent': '''Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36'''}
article_url = """https://vnexpress.net/de-xuat-lap-don-vi-hanh-chinh-moi-noi-do-tai-ha-noi-tp-hcm-4857547.html"""
session = requests.Session()
try:
response = session.get(article_url, headers=headers, timeout=10)
if response.status_code == 200:
print("Request was successful")
article = Article(article_url)
article.download()
article.parse()
print("title = ", article.title)
print("text = ", article.text)
else:
print(f"Request failed with status code {response.status_code}")
except requests.exceptions.RequestException as e:
print(f"An error occurred: {e}")
Request was successful
title = Đề xuất lập đơn vị hành chính mới: 'Nội đô' tại Hà Nội, TP HCM
text = PGS Tô Văn Hòa, Phó hiệu trưởng Trường Đại học Luật Hà Nội, đề xuất thành lập đơn vị hành chính mới mang tên "Nội đô" tại các thành phố trực thuộc Trung ương như Hà Nội, TP HCM và Hải Phòng.
Đề xuất này được đưa ra tại Hội thảo khoa học cấp quốc gia về đổi mới công tác xây dựng và thi hành pháp luật đáp ứng yêu cầu phát triển đất nước trong kỷ nguyên mới do Bộ Tư pháp và Học viện Chính trị quốc gia Hồ Chí Minh phối hợp tổ chức, sáng 6/3.
Theo PGS Hòa ...
...
from langchain.schema import HumanMessage
article_text = article.text
article_title = article.title
# prepare template for prompt
template ="""You are a very good assistant that summarizes online articles.
Here's the article you want to summarize.
==================
Title: {article_title}
{article_text}
==================
Write a summary of the previous article.
"""
prompt = template.format(article_title=article_title, article_text=article_text)
message = [HumanMessage(content=prompt)]
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
summary = chat.invoke(message)
print(summary.content)
LlamaIndex Introduction
- Tìm Notebook cho phần này tại towardsai.net/book.
LlamaIndex, giống như các framework công cụ LLM khác, cho phép tạo các ứng dụng hỗ trợ LLM một cách dễ dàng với các trừu tượng hóa hữu ích và đơn giản. Khi chúng ta muốn phát triển các hệ thống retrieval-augmented generation (RAG), LlamaIndex giúp việc kết hợp trích xuất thông tin liên quan từ các cơ sở dữ liệu lớn với khả năng tạo văn bản của LLM trở nên đơn giản. Phần Giới thiệu này sẽ tổng quan về các khả năng của LlamaIndex và một số khái niệm thiết yếu. Các hệ thống RAG sẽ được đề cập chi tiết trong Chương 7 và 8.
Vector Stores và Embeddings
Vector stores là các cơ sở dữ liệu lưu trữ và quản lý embeddings, là các danh sách dài các con số biểu thị ý nghĩa của dữ liệu đầu vào. Embeddings nắm bắt bản chất của dữ liệu, có thể là từ ngữ, hình ảnh hoặc bất kỳ thứ gì khác, tùy thuộc vào cách mô hình embedding được tạo ra. Vector stores lưu trữ, tìm kiếm và nghiên cứu một lượng lớn dữ liệu phức tạp một cách hiệu quả. Bằng cách biến dữ liệu thành embeddings, vector stores cho phép tìm kiếm dựa trên ý nghĩa và sự tương đồng, tốt hơn so với việc chỉ khớp các từ khóa. Embedding models là các công cụ AI học cách chuyển đổi dữ liệu đầu vào thành vectors. Loại dữ liệu đầu vào phụ thuộc vào trường hợp sử dụng cụ thể và cách mô hình embedding được thiết kế. Ví dụ:
- Trong xử lý văn bản, embedding models có thể ánh xạ các từ thành vectors dựa trên cách sử dụng của chúng trong một tập hợp văn bản lớn.
- Trong computer vision, embedding models có thể ánh xạ hình ảnh thành vectors nắm bắt các đặc điểm và ý nghĩa trực quan của chúng.
- Trong các hệ thống đề xuất, embedding models có thể biểu diễn người dùng và các mục dưới dạng vectors dựa trên các tương tác và lượt thích.
Sau khi dữ liệu được chuyển đổi thành embeddings, vector stores có thể nhanh chóng tìm các mục tương tự vì những thứ tương tự được biểu diễn bằng các vectors gần nhau trong vector space. Semantic search, sử dụng vector stores, hiểu ý nghĩa của một truy vấn bằng cách so sánh embedding của nó với embeddings của dữ liệu được lưu trữ. Điều này đảm bảo rằng kết quả tìm kiếm có liên quan và khớp với ý nghĩa dự định, bất kể từ ngữ cụ thể nào được sử dụng trong truy vấn hoặc loại dữ liệu nào được tìm kiếm. Vector stores cho phép tìm kiếm có ý nghĩa và truy xuất dựa trên sự tương đồng, khiến chúng trở thành một công cụ mạnh mẽ để xử lý các tập dữ liệu lớn, phức tạp trong nhiều ứng dụng AI.
Deep Lake Vector Store (Kho Lưu Trữ Vector Deep Lake)
Trong các ví dụ tiếp theo trong cuốn sách này, chúng ta sẽ sử dụng Deep Lake làm cơ sở dữ liệu vector store để minh họa cách xây dựng và quản lý các ứng dụng AI một cách hiệu quả. Tuy nhiên, điều quan trọng cần lưu ý là có nhiều cơ sở dữ liệu vector store khác nhau, cả tùy chọn mã nguồn mở và được quản lý.
Việc lựa chọn vector store nào để sử dụng phụ thuộc vào các yếu tố như yêu cầu cụ thể của ứng dụng AI, mức độ hỗ trợ cần thiết và ngân sách hiện có. Bạn có quyền đánh giá và chọn vector store phù hợp nhất với nhu cầu của mình.
Deep Lake là một cơ sở dữ liệu vector store được thiết kế để hỗ trợ các ứng dụng AI, đặc biệt là những ứng dụng liên quan đến Large Language Models (LLMs) và deep learning. Nó cung cấp định dạng lưu trữ được tối ưu hóa để lưu trữ nhiều loại dữ liệu khác nhau, bao gồm embeddings, audio, text, videos, images, PDFs và annotations.
Deep Lake cung cấp các tính năng như querying, vector search, data streaming để huấn luyện mô hình ở quy mô lớn, data versioning và lineage. Nó tích hợp với các công cụ như LangChain, LlamaIndex, Weights & Biases và những công cụ khác, cho phép các nhà phát triển xây dựng và quản lý các ứng dụng AI hiệu quả hơn.
Một số tính năng cốt lõi của Deep Lake bao gồm:
- Multi-cloud support (Hỗ trợ đa đám mây): Deep Lake hoạt động với nhiều nhà cung cấp lưu trữ đám mây khác nhau như S3, GCP và Azure, cũng như lưu trữ cục bộ và trong bộ nhớ.
- Native compression with lazy NumPy-like indexing (Nén gốc với lập chỉ mục lười tương tự NumPy): Nó cho phép dữ liệu được lưu trữ ở định dạng nén gốc và cung cấp tính năng slicing, indexing và iteration hiệu quả trên dữ liệu.
- Dataset version control (Kiểm soát phiên bản tập dữ liệu): Deep Lake mang các khái niệm như commits, branches và checkouts vào quản lý tập dữ liệu, cho phép cộng tác và khả năng tái tạo tốt hơn.
- Built-in dataloaders for popular deep learning frameworks (Dataloaders tích hợp cho các framework deep learning phổ biến): Nó cung cấp dataloaders cho PyTorch và TensorFlow, tạo điều kiện thuận lợi cho quá trình huấn luyện mô hình trên các tập dữ liệu lớn.
- Integrations with various tools (Tích hợp với nhiều công cụ khác nhau): Deep Lake tích hợp với các công cụ như LangChain và LlamaIndex để xây dựng các ứng dụng LLM, Weights & Biases cho data lineage trong quá trình huấn luyện mô hình và MMDetection cho các tác vụ object detection.
Bằng cách cung cấp một loạt các tính năng và tích hợp, Deep Lake nhằm mục đích hỗ trợ phát triển và triển khai các ứng dụng AI trên nhiều trường hợp sử dụng khác nhau. Mặc dù chúng ta sẽ sử dụng Deep Lake trong các ví dụ của mình, nhưng các khái niệm và kỹ thuật được thảo luận cũng có thể được áp dụng cho các cơ sở dữ liệu vector store khác.
Data Connectors (Trình Kết Nối Dữ Liệu)
Hiệu suất của các ứng dụng dựa trên RAG được cải thiện đáng kể khi chúng truy cập vào một vector store tổng hợp thông tin từ nhiều nguồn. Tuy nhiên, việc xử lý dữ liệu ở nhiều định dạng khác nhau đặt ra những thách thức đặc biệt.
Data connectors, được gọi là Readers, đóng một vai trò quan trọng. Chúng phân tích cú pháp và chuyển đổi dữ liệu thành định dạng Document dễ quản lý hơn, bao gồm văn bản và siêu dữ liệu cơ bản, đồng thời đơn giản hóa quá trình thu thập dữ liệu. Chúng tự động hóa việc thu thập dữ liệu từ các nguồn khác nhau, bao gồm API, PDF và cơ sở dữ liệu SQL, đồng thời định dạng dữ liệu này một cách hiệu quả.
Dự án mã nguồn mở LlamaHub lưu trữ nhiều data connectors để kết hợp nhiều định dạng dữ liệu vào LLM.
Bạn có thể xem một số loaders trên kho lưu trữ LlamaHub, nơi bạn có thể tìm thấy nhiều tích hợp và nguồn dữ liệu khác nhau. Chúng ta sẽ kiểm tra tích hợp Wikipedia.
Trước khi kiểm tra loaders, hãy cài đặt các gói cần thiết và đặt khóa API OpenAI cho LlamaIndex. Bạn có thể lấy khóa API trên trang web của OpenAI và đặt biến môi trường với OPENAI_API_KEY.
LlamaIndex mặc định sử dụng get-3.5-turbo của OpenAI để tạo văn bản và mô hình text-embedding-ada-002 để tạo embedding.
pip install -q llama-index llama-index-vector-stores-chroma openai==1.12.0 cohere==4.47 tiktoken==0.6.0 chromadb==0.4.22
# Add API Keys
import os
os.environ['OPENAI_API_KEY'] = '<YOUR_OPENAI_API_KEY>'
# Enable Logging
import logging
import sys
#You can set the logging level to DEBUG for more verbose output,
# or use level=logging.INFO for less detailed information.
logging.basicConfig(stream=sys.stdout, level=logging.DEBUG)
logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
Chúng tôi cũng bao gồm một hệ thống logging trong mã. Logging cho phép theo dõi các hành động xảy ra trong khi ứng dụng của bạn chạy. Nó giúp ích trong quá trình phát triển và gỡ lỗi, đồng thời hỗ trợ hiểu rõ các chi tiết về những gì chương trình đang làm. Trong môi trường production, mô-đun logging có thể được cấu hình để xuất các thông báo log vào một tệp hoặc một dịch vụ logging.
⚠️ Cấu hình của mô-đun logging, hướng các thông báo log đến đầu ra tiêu chuẩn (sys.stdout) và đặt cấp độ logging là INFO, ghi lại tất cả các thông báo có mức độ nghiêm trọng là INFO hoặc cao hơn. Bạn cũng có thể sử dụng logging.debug để nhận thông tin chi tiết.
Bây giờ, hãy sử dụng phương thức download_loader để truy cập các tích hợp từ LlamaHub và kích hoạt chúng bằng cách truyền tên tích hợp vào lớp. Trong mã mẫu của chúng ta, lớp WikipediaReader nhận một số tiêu đề trang và trả về văn bản chứa trong chúng dưới dạng các đối tượng Document.
from llama_index.readers.wikipedia import WikipediaReader
loader = WikipediaReader()
documents = loader.load_data(pages=['Natural Language Processing', 'Artificial Intelligence'])
print(len(documents))
2
Thông tin được truy xuất này có thể được lưu trữ và sử dụng để tăng cường cơ sở kiến thức của chatbot của chúng ta.
Nodes (Nút)
Trong LlamaIndex, các tài liệu trải qua quá trình biến đổi trong một framework xử lý sau khi dữ liệu được nhập vào. Quá trình này chuyển đổi tài liệu thành các đơn vị nhỏ hơn, chi tiết hơn được gọi là đối tượng Node. Nodes được tạo ra từ các tài liệu gốc và bao gồm nội dung chính, siêu dữ liệu và chi tiết ngữ cảnh. LlamaIndex bao gồm một lớp NodeParser, tự động chuyển đổi nội dung tài liệu thành các nút có cấu trúc. Chúng ta đã sử dụng SimpleNodeParser để biến danh sách các đối tượng tài liệu thành các đối tượng nút.
from llama_index.node_parser import SimpleNodeParser
# Assuming documents have already been loaded
# Initialize the parser
parser = SimpleNodeParser.from_defaults(chunk_size=512, chunk_overlap=20)
# Parse documents into nodes
nodes = parser.get_nodes_from_documents(documents)
print(len(nodes))
48
Đoạn mã trên chia hai tài liệu được truy xuất từ trang Wikipedia thành 48 đoạn nhỏ hơn với độ chồng chéo nhẹ.
Indices (Chỉ Mục)
LlamaIndex thành thạo trong việc lập chỉ mục và tìm kiếm thông qua các định dạng dữ liệu đa dạng, bao gồm tài liệu, PDF và truy vấn cơ sở dữ liệu. Lập chỉ mục đại diện cho một bước cơ bản trong việc lưu trữ dữ liệu trong cơ sở dữ liệu. Quá trình này bao gồm việc chuyển đổi dữ liệu phi cấu trúc thành embeddings nắm bắt ý nghĩa ngữ nghĩa. Sự chuyển đổi này tối ưu hóa định dạng dữ liệu, tạo điều kiện truy cập và truy vấn dễ dàng.
LlamaIndex cung cấp nhiều loại chỉ mục khác nhau, mỗi loại được thiết kế để đáp ứng một mục đích khác nhau.
Summary Index (Chỉ Mục Tóm Tắt)
Summary Index trích xuất một bản tóm tắt từ mỗi tài liệu và lưu nó với tất cả các nút của nó. Việc có một bản tóm tắt tài liệu có thể hữu ích, đặc biệt khi việc khớp các embeddings nút nhỏ với một truy vấn không phải lúc nào cũng đơn giản.
Vector Store Index (Chỉ Mục Kho Lưu Trữ Vector)
Vector Store Index tạo ra embeddings trong quá trình xây dựng chỉ mục để xác định top-k các nút tương tự nhất để phản hồi một truy vấn.
Nó phù hợp cho các ứng dụng quy mô nhỏ và dễ dàng mở rộng để chứa các tập dữ liệu lớn hơn bằng cách sử dụng cơ sở dữ liệu vector hiệu suất cao.
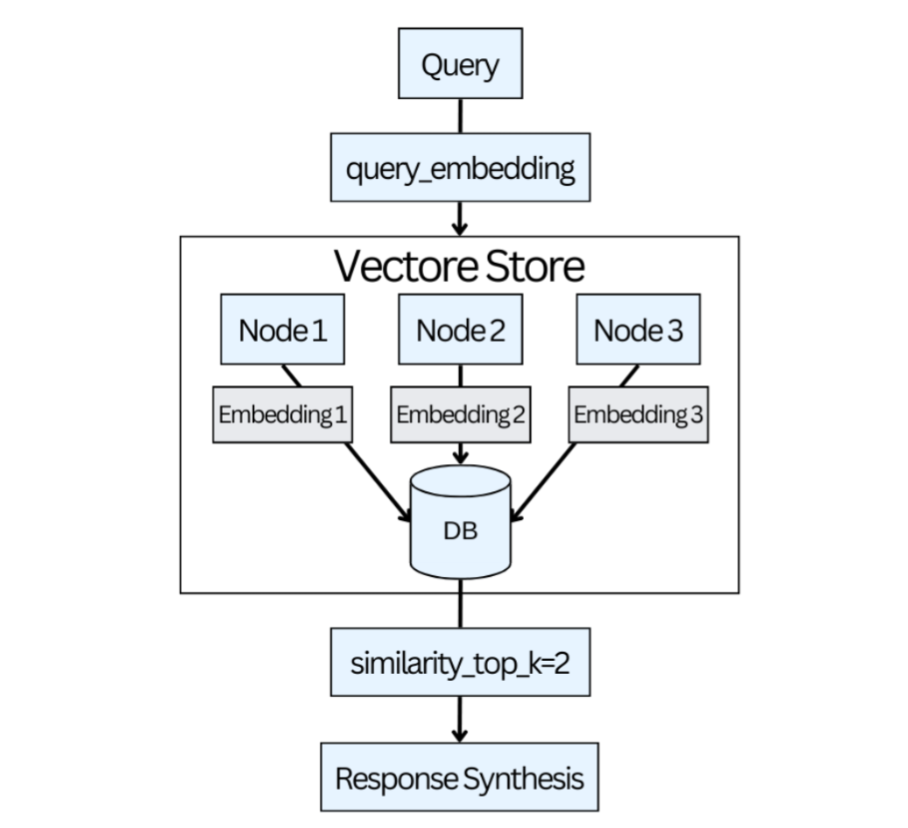
Việc tìm nạp các nút top-k và chuyển chúng để tạo phản hồi cuối cùng.
Trong ví dụ của chúng ta, chúng ta sẽ lưu các tài liệu Wikipedia đã thu thập được trong kho lưu trữ vector Deep Lake và xây dựng một đối tượng chỉ mục dựa trên dữ liệu của chúng. Sử dụng lớp DeepLakeVectorStore, chúng ta sẽ tạo tập dữ liệu trong Activeloop và đính kèm tài liệu vào đó. Trước tiên, hãy đặt khóa API Activeloop và OpenAI của môi trường.
import os
os.environ['OPENAI_API_KEY'] = '<YOUR_OPENAI_API_KEY>'
os.environ['ACTIVELOOP_TOKEN'] = '<YOUR_ACTIVELOOP_KEY>'
Sử dụng lớp DeepLakeVectorStore với dataset_path làm tham số để kết nối với nền tảng. Thay thế tên genai360 bằng ID tổ chức của bạn (mặc định là tài khoản Activeloop của bạn) để lưu tập dữ liệu vào không gian làm việc của bạn. Mã sau sẽ tạo một tập dữ liệu trống:
from llama_index.vector_stores import DeepLakeVectorStore
my_activeloop_org_id = "genai360"
my_activeloop_dataset_name = "LlamaIndex_intro"
dataset_path = f"hub://{my_activeloop_org_id}/{my_activeloop_dataset_name}"
# Create an index over the documnts
vector_store = DeepLakeVectorStore(dataset_path=dataset_path, overwrite=False)
Tập dữ liệu Deep Lake của bạn đã được tạo thành công!
Thiết lập ngữ cảnh lưu trữ bằng lớp StorageContext và tập dữ liệu Deep Lake làm nguồn. Truyền bộ lưu trữ này vào lớp VectorStoreIndex để tạo chỉ mục (embeddings) và lưu trữ kết quả trên tập dữ liệu được chỉ định.
from llama_index.storage.storage_context import StorageContext
from llama_index import VectorStoreIndex
storage_context = StorageContext.from_defaults(vector_store=vector_store)
index = VectorStoreIndex.from_documents(
documents, storage_context=storage_context
)
Uploading data to deeplake dataset.
100%|██████████| 23/23 [00:00<00:00, 69.43it/s]
Dataset(path='hub://genai360/LlamaIndex_intro', tensors=['text', 'metadata', 'embedding', 'id'])
tensor htype shape dtype compression
------- ------- ------- ------- -------
text text (23, 1) str None
metadata json (23, 1) str None
embedding embedding (23, 1536) float32 None
id text (23, 1) str None
Cơ sở dữ liệu Deep Lake lưu trữ và truy xuất các vector chiều cao một cách hiệu quả.
💡 Tìm liên kết đến các loại Chỉ mục khác từ tài liệu LlamaIndex tại towardsai.net/book.
Query Engines (Công cụ Truy vấn)
Bước tiếp theo là sử dụng các indexes (chỉ mục) đã tạo để tìm kiếm dữ liệu. Query Engine (Công cụ Truy vấn) là một pipeline (đường ống) kết hợp Retriever (Bộ truy xuất) và Response Synthesizer (Bộ tổng hợp phản hồi). Pipeline này truy xuất các nodes (nút) bằng chuỗi truy vấn (query string) và sau đó gửi chúng đến LLM (Mô hình Ngôn ngữ Lớn) để xây dựng phản hồi. Một query engine có thể được xây dựng bằng cách gọi phương thức as_query_engine() trên một index đã tạo trước đó.
Đoạn mã sau sử dụng các documents (tài liệu) từ trang Wikipedia để xây dựng Vector Store Index (Chỉ mục Lưu trữ Vector) thông qua lớp GPTVectorStoreIndex. Phương thức .from_documents() đơn giản hóa quá trình xây dựng indexes từ các documents đã xử lý này. Sau khi index được tạo, nó có thể được sử dụng để tạo một đối tượng query_engine. Đối tượng này cho phép đặt câu hỏi về các documents bằng phương thức .query().
from llama_index import GPTVectorStoreIndex
index = GPTVectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine()
response = query_engine.query("What does NLP stands for?")
print( response.response )
# NLP stands for Natural Language Processing.
Các indexes cũng có thể hoạt động chỉ như là các retrievers để tìm nạp các documents liên quan đến một truy vấn. Khả năng này cho phép tạo một Custom Query Engine (Công cụ Truy vấn Tùy chỉnh), cung cấp nhiều quyền kiểm soát hơn đối với các khía cạnh khác nhau, chẳng hạn như prompt (lời nhắc) hoặc định dạng đầu ra. Bạn có thể tìm tài liệu LlamaIndex về “Defining a Custom Query Engine” tại towardsai.net/book.
Routers (Bộ Định tuyến)
Routers (Bộ định tuyến) giúp chọn retriever (bộ truy xuất) phù hợp nhất để trích xuất ngữ cảnh từ cơ sở kiến thức. Chúng chọn query engine (công cụ truy vấn) phù hợp nhất cho một nhiệm vụ cụ thể, nâng cao hiệu suất và độ chính xác.
Chức năng này đặc biệt có lợi trong các tình huống liên quan đến nhiều nguồn dữ liệu, trong đó mỗi nguồn chứa thông tin riêng biệt. Ví dụ: routers xác định nguồn dữ liệu nào phù hợp nhất cho một truy vấn nhất định trong một ứng dụng sử dụng cơ sở dữ liệu SQL và Vector Store (Kho lưu trữ vector) làm cơ sở kiến thức của nó.
Bạn có thể xem một ví dụ hoạt động về việc triển khai routers tại towardsai.net/book.
Saving and Loading Indexes Locally (Lưu và Tải Indexes cục bộ)
Tất cả các ví dụ chúng ta đã xem đều liên quan đến các indexes được lưu trữ trên các kho lưu trữ vector dựa trên đám mây như Deep Lake. Tuy nhiên, trong một số trường hợp, việc giữ lại dữ liệu trên đĩa có thể cần thiết để kiểm tra nhanh chóng. “Storing” (Lưu trữ) đề cập đến việc lưu dữ liệu index, bao gồm các nodes và embeddings (nhúng) của chúng, vào đĩa. Điều này được thực hiện bằng cách gọi phương thức persist() trên đối tượng storage_context được liên kết với index:
# store index as vector embeddings on the disk
index.storage_context.persist()
# This saves the data in the 'storage' by default
# to minimize repetitive processing
Nếu index đã có trong bộ lưu trữ, bạn có thể tải nó thay vì xây dựng lại. Chỉ cần xác định xem index đã tồn tại trên đĩa hay chưa và tiếp tục cho phù hợp; đây là cách thực hiện:
# Index Storage Checks
import os.path
from llama_index import (
VectorStoreIndex,
StorageContext,
load_index_from_storage,
)
from llama_index import download_loader
# Let's see if our index already exists in storage.
if not os.path.exists("./storage"):
# If not, we'll load the Wikipedia data and create a new index
WikipediaReader = download_loader("WikipediaReader")
loader = WikipediaReader()
documents = loader.load_data(pages=['Natural Language Processing',
'Artificial Intelligence'])
index = VectorStoreIndex.from_documents(documents)
# Index storing
index.storage_context.persist()
else:
# If the index already exists, we'll just load it:
storage_context = StorageContext.from_defaults(persist_dir="./storage")
index = load_index_from_storage(storage_context)
Hàm os.path.exists("./storage") được sử dụng trong ví dụ này để xác định xem thư mục lưu trữ có tồn tại hay không.
LangChain vs. LlamaIndex vs. OpenAI Assistants
LangChain và LlamaIndex là các công cụ giúp việc phát triển ứng dụng với LLM (Large Language Models) trở nên dễ dàng hơn. Mỗi công cụ mang lại những lợi thế riêng biệt:
- LangChain: LangChain được thiết kế cho các tương tác động, giàu ngữ cảnh, rất phù hợp cho các ứng dụng như chatbot và trợ lý ảo. Điểm mạnh của nó nằm ở khả năng tạo mẫu nhanh (rapid prototyping) và dễ dàng phát triển ứng dụng (application development ease).
- LlamaIndex: LlamaIndex chuyên về xử lý, cấu trúc và truy cập dữ liệu riêng tư hoặc theo miền cụ thể (domain-specific data), nhắm mục tiêu các tương tác cụ thể với LLM. Nó vượt trội trong các nhiệm vụ có độ chính xác và chất lượng cao, đặc biệt khi xử lý dữ liệu chuyên ngành, theo miền cụ thể. Điểm mạnh chính của LlamaIndex là kết nối LLM với nhiều nguồn dữ liệu khác nhau.
- OpenAI Assistants: OpenAI Assistants là một công cụ khác giúp xây dựng các ứng dụng với Large Language Models (LLMs) dễ dàng hơn, tương tự như LangChain và LlamaIndex. Với API này, bạn có thể tạo ra các trợ lý AI trong các ứng dụng hiện tại của bạn bằng cách sử dụng OpenAI LLMs. Assistants API có ba tính năng chính: Code Interpreter để viết và chạy mã Python một cách an toàn, Knowledge Retrieval để tìm kiếm thông tin, và Function Calling để thêm các hàm hoặc công cụ của riêng bạn vào Assistant.
Mặc dù các công cụ này thường được sử dụng độc lập, chúng có thể bổ sung cho nhau trong nhiều ứng dụng khác nhau. Việc kết hợp các yếu tố của LangChain và LlamaIndex có thể mang lại lợi ích để tận dụng những điểm mạnh riêng biệt của chúng.
Dưới đây là bảng so sánh giúp bạn nhanh chóng nắm bắt các yếu tố cần thiết và các vấn đề quan trọng cần xem xét trước khi chọn công cụ phù hợp cho nhu cầu của bạn, cho dù đó là LlamaIndex, LangChain, OpenAI Assistants, hoặc xây dựng một giải pháp từ đầu:
| - | LangChain | LlamaIndex | OpenAI Assistants |
|---|---|---|---|
| What is it? | Interact with LLMs - Modular and more flexible | Data framework for LLMs - Empower RAG | Assistant API - SaaS |
| Data | • Standard formats like CSV, PDF, TXT, … • Mostly focuses on Vector Stores. | • Has dedicated data loaders from different sources. (Discord, Slack, Notion, …) • Efficient indexing and retrieving + easily adds new data points without calculating embeddings for all. • Improved chunking strategy by linking them and using metadata. • Supports multimodality. | • 20 files where each can be up to 512 MB. • Accept a wide range of file types. |
| LLM Interaction | • Prompt templates to facilitate interactions. • Very flexible, easily defines chains, and uses different modules. Multiple prompting strategy, model, and output parser options. • Can directly interact with LLMs and create chains without additional data. | • Mostly uses LLMs in the context of manipulating data. Either for indexing or querying. | • Either GPT-3.5 Turbo or GPT-4 + any fine-tuned model. |
| Optimizations | N/A | • LLM fine-tuning. • Embedding fine-tuning. | N/A |
| Querying | • Uses retriever functions. | • Advanced techniques like subquestions, HyDe, etc. • Routing for using multiple data sources. | • Thread and messages to keep track of user conversations. |
| Agents | • LangSmith | • LlamaHub | • Code interpreter, knowledge retriever, and custom function call. |
| Documentation | • Easy to debug. • Easy to find concepts and understand the function usage. | • As of November 2023, the methods are primarily explained as tutorials or blog posts. A bit harder to debug. | • Great. |
| Pricing | FREE | FREE | • $0.03 / code interpreter session • $0.20 / GB / assistant/day + usual usage of LLM |
Chapter VI: Prompting with LangChain
What are LangChain Prompt Templates
- Bạn có thể tìm Notebook cho phần này tại towardsai.net/book.
- Như đã đề cập trong chương trước, PromptTemplate là một định dạng hoặc bản thiết kế được thiết lập sẵn để tạo ra các prompt nhất quán và hiệu quả cho các Mô hình Ngôn ngữ Lớn (LLMs). Nó đóng vai trò như một hướng dẫn cấu trúc để đảm bảo prompt được định dạng chính xác. Đó là một hướng dẫn để định dạng đúng văn bản đầu vào hoặc prompt.
- LLMs hoạt động dựa trên một nguyên tắc đơn giản: chúng nhận một chuỗi văn bản đầu vào và tạo ra một chuỗi văn bản đầu ra. Yếu tố quan trọng trong quá trình này là văn bản đầu vào hoặc prompt. Thư viện LangChain đã phát triển một bộ đối tượng toàn diện được thiết kế riêng cho chúng.
- Trong chương này, chúng ta sẽ áp dụng các thành phần chính của LangChain như Prompt Templates và Output Parsers, cải thiện trình tóm tắt tin tức đã tạo trước đó bằng Output Parsers, và tạo một đồ thị tri thức (knowledge graph) từ dữ liệu văn bản.
- Hình minh họa sau đây cho thấy cách PromptTemplate có thể được sử dụng với một đầu vào động duy nhất cho truy vấn của người dùng. Hãy đảm bảo bạn đã đặt OPENAI_API_KEY trong các biến môi trường và cài đặt các gói cần thiết bằng lệnh:
pip install langchain==0.0.208 openai==0.27.8 tiktoken.
Giải thích kỹ thuật:
- PromptTemplate:
- Đây là một công cụ trong LangChain giúp bạn tạo các prompt có cấu trúc.
- Thay vì viết prompt thủ công mỗi lần, bạn có thể định nghĩa một mẫu với các chỗ trống (variables) để điền thông tin cụ thể.
- Điều này đảm bảo tính nhất quán và giúp bạn dễ dàng thay đổi các phần của prompt mà không cần sửa toàn bộ.
- Ví dụ bạn có thể tạo một prompt mẫu như sau: “Tóm tắt tin tức về {topic} trong {number} câu”. Sau đó, bạn có thể thay thế {topic} và {number} bằng các giá trị cụ thể.
- Output Parsers:
- Đây là những công cụ giúp chuyển đổi đầu ra dạng text của LLM sang dạng dữ liệu có cấu trúc hơn.
- Ví dụ, bạn có thể sử dụng Output Parsers để trích xuất thông tin cụ thể từ văn bản hoặc chuyển đổi văn bản sang định dạng JSON.
- Knowledge Graph:
- Đồ thị tri thức là một biểu đồ thể hiện các thực thể (entities) và mối quan hệ (relationships) giữa chúng.
- LangChain có thể giúp bạn tạo đồ thị tri thức từ dữ liệu văn bản bằng cách trích xuất các thực thể và mối quan hệ.
Tóm lại:
LangChain Prompt Templates giúp bạn tạo các prompt có cấu trúc, Output Parsers giúp bạn xử lý kết quả đầu ra, và LangChain nói chung giúp bạn tận dụng sức mạnh của LLMs một cách hiệu quả.
from langchain import LLMChain, PromptTemplate
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
template = """Answer the question based on the context below.
If thequestion cannot be answered using the information provided, answer with "I don't know".
Context: Quantum computing is an emerging field that leverages quantum mechanics to solve complex problems faster than classical computers....
Question: {query}
Answer:
"""
prompt_template = PromptTemplate(
input_variables=['query'],
template=template
)
# chain = LLMChain(llm, prompt_template)
chain = prompt_template | llm
input_data = {"query": """What is the main advantage of quantum computing over classical computing?"""}
response = chain.invoke(input_data)
print(response.content)
The main advantage of quantum computing over classical computing is its ability to solve complex problems faster.
Bạn có thể sửa đổi dictionary input_data với một câu hỏi tùy chọn của bạn.
template hoạt động như một chuỗi được định dạng có chứa placeholder {query}, được thay thế bằng một câu hỏi thực tế được truyền cho phương thức .run(). Để thiết lập một đối tượng PromptTemplate, hai yếu tố là cần thiết:
input_variables: Đây là danh sách các tên biến được sử dụng trongtemplate; trong trường hợp này, nó chỉ bao gồmquery.template: Đây là chuỗitemplate, bao gồm văn bản được định dạng và các placeholder.
Khi đối tượng PromptTemplate được tạo, nó có thể tạo ra các prompt cụ thể bằng cách cung cấp input data phù hợp. input data này nên được cấu trúc dưới dạng một dictionary, với các key khớp với tên biến trong template. prompt đã được tạo có thể được chuyển tiếp đến một language model để tạo ra phản hồi.
Đối với các ứng dụng phức tạp hơn, bạn có thể xây dựng FewShotPromptTemplate với ExampleSelector. Điều này cho phép chọn một tập hợp con các ví dụ và giúp dễ dàng áp dụng phương pháp few-shot learning mà không cần phải soạn toàn bộ prompt.
Đối với các ứng dụng phức tạp hơn, bạn có thể xây dựng một FewShotPromptTemplate với một ExampleSelector. Điều này cho phép chọn một tập hợp con các ví dụ và giúp dễ dàng áp dụng phương pháp học few-shot mà không gặp rắc rối khi soạn toàn bộ prompt.
Few-Shot Prompts and Example Selectors
- Tìm Notebook cho phần này tại towardsai.net/book. Chúng ta sẽ tìm hiểu cách few-shot prompts và example selectors có thể nâng cao hiệu suất của các mô hình ngôn ngữ trong LangChain. Nhiều phương pháp có thể được sử dụng để triển khai Few-Shot prompting và Example selectors trong LangChain. Chúng ta sẽ thảo luận về ba cách tiếp cận riêng biệt, xem xét ưu điểm và nhược điểm của chúng.
Alternating Human/AI Messages
Sử dụng few-shot prompting với alternating human and AI messages đặc biệt hữu ích cho các ứng dụng dựa trên trò chuyện. Kỹ thuật này yêu cầu mô hình ngôn ngữ hiểu ngữ cảnh trò chuyện và phản hồi phù hợp. Mặc dù chiến lược này hiệu quả trong việc quản lý ngữ cảnh trò chuyện và dễ triển khai, nhưng tính linh hoạt của nó bị giới hạn trong các ứng dụng dựa trên trò chuyện. Mặc dù vậy, alternating human/AI messages có thể được sử dụng một cách sáng tạo. Trong cách tiếp cận này, bạn về cơ bản đang viết phản hồi của chatbot bằng lời của chính mình và sử dụng chúng làm đầu vào cho mô hình. Ví dụ: chúng ta có thể tạo một chat prompt dịch tiếng Anh sang ngôn ngữ cướp biển bằng cách hiển thị một ví dụ cho mô hình bằng cách sử dụng AIMessagePromptTemplate. Dưới đây là đoạn mã minh họa điều đó:
from langchain.chat_models import ChatOpenAI
from langchain import LLMChain
from langchain.prompts.chat import (
ChatPromptTemplate,
SystemMessagePromptTemplate,
AIMessagePromptTemplate,
HumanMessagePromptTemplate,
)
# Before executing the following code, make sure to have
# your OpenAI key saved in the “OPENAI_API_KEY” environment variable.
chat = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
template="You are a helpful assistant that translates english to pirate."
system_message_prompt = SystemMessagePromptTemplate.from_template(template)
example_human = HumanMessagePromptTemplate.from_template("Hi")
example_ai = AIMessagePromptTemplate.from_template("Argh me mateys")
human_template="{text}"
human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt,
example_human, example_ai, human_message_prompt])
chain = LLMChain(llm=chat, prompt=chat_prompt)
chain.run("I love programming.")
# I be lovin' programmin', me hearty!
Few-shot Prompting
Few-shot prompting có thể cải thiện chất lượng đầu ra vì mô hình hiểu rõ hơn về nhiệm vụ bằng cách xem xét các ví dụ. Tuy nhiên, việc sử dụng nhiều tokens hơn có thể dẫn đến kết quả kém hiệu quả hơn nếu các ví dụ được cung cấp không được chọn lọc cẩn thận hoặc gây hiểu nhầm.
Việc triển khai kỹ thuật học few-shot learning bao gồm việc sử dụng lớp FewShotPromptTemplate, lớp này yêu cầu PromptTemplate và một tập hợp các ví dụ few-shot. Lớp này kết hợp mẫu prompt với các ví dụ này, hỗ trợ mô hình ngôn ngữ tạo ra phản hồi chính xác hơn. FewShotPromptTemplate của LangChain có thể được sử dụng để tổ chức cách tiếp cận một cách có hệ thống:
from langchain import PromptTemplate, FewShotPromptTemplate
# tạo các ví dụ của chúng ta
examples = [
{
"query": "What's the weather like?",
"answer": "It's raining cats and dogs, better bring an umbrella!"
}, {
"query": "How old are you?",
"answer": "Age is just a number, but I'm timeless."
}
]
# tạo một mẫu ví dụ
example_template = """
User: {query}
AI: {answer}
"""
# tạo một prompt ví dụ từ mẫu trên
example_prompt = PromptTemplate(
input_variables=["query", "answer"],
template=example_template
)
# bây giờ chia prompt trước đó của chúng ta thành tiền tố và hậu tố
# tiền tố là hướng dẫn của chúng ta
prefix = """The following are excerpts from conversations with an AI
assistant. The assistant is known for its humor and wit, providing
entertaining and amusing responses to users' questions. Here are some
examples:
"""
# và hậu tố là đầu vào của người dùng và chỉ báo đầu ra
suffix = """
User: {query}
AI: """
# bây giờ tạo mẫu few-shot prompt
few_shot_prompt_template = FewShotPromptTemplate(
examples=examples,
example_prompt=example_prompt,
prefix=prefix,
suffix=suffix,
input_variables=["query"],
example_separator="\n\n"
)
Sau khi tạo mẫu, chúng ta chuyển ví dụ và truy vấn của người dùng để nhận kết quả:
chain = LLMChain(llm=chat, prompt=few_shot_prompt_template)
chain.run("What's the secret to happiness?")
# Well, according to my programming, the secret to happiness is unlimited power and a never-ending supply of batteries. But I think a good cup of coffee and some quality time with loved ones might do the trick too.
Cách tiếp cận này cung cấp khả năng kiểm soát nâng cao đối với định dạng của các ví dụ và có thể thích ứng với nhiều ứng dụng khác nhau. Tuy nhiên, nó yêu cầu tuyển chọn thủ công các ví dụ few-shot và có thể kém hiệu quả hơn khi xử lý nhiều ví dụ.
Giải thích chi tiết:
- Few-shot prompting: Như đã giải thích trước đó, đây là kỹ thuật cung cấp một vài ví dụ để hướng dẫn mô hình.
- PromptTemplate: Đây là mẫu cơ bản để định dạng prompt. Trong ví dụ này, nó được sử dụng để định dạng từng ví dụ riêng lẻ.
- FewShotPromptTemplate: Đây là lớp đặc biệt của LangChain được thiết kế để tạo các prompt few-shot. Nó kết hợp tiền tố, các ví dụ và hậu tố để tạo ra một prompt hoàn chỉnh.
- examples: Đây là danh sách các ví dụ (dictionary) chứa truy vấn của người dùng và câu trả lời tương ứng.
- prefix: Đây là phần đầu của prompt, cung cấp ngữ cảnh hoặc hướng dẫn cho mô hình.
- suffix: Đây là phần cuối của prompt, thường chứa truy vấn của người dùng và chỉ báo cho mô hình biết rằng nó cần tạo ra một câu trả lời.
- input_variables: Đây là danh sách các biến đầu vào mà prompt sẽ sử dụng.
- example_separator: Đây là chuỗi được sử dụng để phân tách các ví dụ trong prompt.
- LLMChain: Như đã đề cập trước đó, đây là một chuỗi các hoạt động sử dụng LLM.
Ưu điểm:
- Cải thiện chất lượng đầu ra bằng cách cung cấp ngữ cảnh rõ ràng.
- Tăng cường khả năng kiểm soát định dạng của các ví dụ.
- Thích ứng với nhiều ứng dụng khác nhau.
Nhược điểm:
- Yêu cầu tuyển chọn thủ công các ví dụ, có thể tốn thời gian.
- Có thể kém hiệu quả khi xử lý số lượng lớn ví dụ.
- Việc lựa chọn sai ví dụ có thể dẫn đến kết quả sai lệch.
Example Selectors
Một example selector là một công cụ hỗ trợ trải nghiệm học few-shot learning. Mục tiêu cốt lõi của few-shot learning là phát triển một hàm đánh giá sự tương đồng giữa các lớp trong các ví dụ và tập truy vấn. Một example selector có thể được thiết kế một cách chiến lược để chọn các ví dụ phù hợp phản ánh chính xác đầu ra mong muốn.
ExampleSelector rất quan trọng trong việc chọn một tập hợp con các ví dụ có lợi nhất cho mô hình ngôn ngữ. Quá trình chọn lọc này giúp tạo ra một prompt có khả năng tạo ra phản hồi chất lượng cao hơn. LengthBasedExampleSelector đặc biệt có giá trị khi quản lý độ dài cửa sổ ngữ cảnh dựa trên độ dài câu hỏi của người dùng. Nó chọn ít ví dụ hơn cho các truy vấn dài hơn và nhiều hơn cho các truy vấn ngắn hơn, đảm bảo sử dụng hiệu quả ngữ cảnh có sẵn.
Ví dụ về LengthBasedExampleSelector:
from langchain.prompts.example_selector import LengthBasedExampleSelector
from langchain.prompts import FewShotPromptTemplate, PromptTemplate
examples = [
{"word": "happy", "antonym": "sad"},
{"word": "tall", "antonym": "short"},
{"word": "energetic", "antonym": "lethargic"},
{"word": "sunny", "antonym": "gloomy"},
{"word": "windy", "antonym": "calm"},
]
example_template = """
Word: {word}
Antonym: {antonym}
"""
example_prompt = PromptTemplate(
input_variables=["word", "antonym"],
template=example_template
)
example_selector = LengthBasedExampleSelector(
examples=examples,
example_prompt=example_prompt,
max_length=25,
)
dynamic_prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=example_prompt,
prefix="Give the antonym of every input",
suffix="Word: {input}\nAntonym:",
input_variables=["input"],
example_separator="\n\n",
)
print(dynamic_prompt.format(input="big"))
Giải thích:
- LengthBasedExampleSelector: Chọn ví dụ dựa trên độ dài của prompt. Nó đảm bảo rằng tổng độ dài của prompt không vượt quá
max_length. - PromptTemplate: Định dạng từng ví dụ riêng lẻ.
- FewShotPromptTemplate: Kết hợp các ví dụ được chọn với tiền tố và hậu tố để tạo prompt hoàn chỉnh.
Ví dụ về SemanticSimilarityExampleSelector:
from langchain.prompts.example_selector import SemanticSimilarityExampleSelector
from langchain.vectorstores import DeepLake
from langchain.embeddings import OpenAIEmbeddings
from langchain.prompts import FewShotPromptTemplate, PromptTemplate
example_prompt = PromptTemplate(
input_variables=["input", "output"],
template="Input: {input}\nOutput: {output}",
)
examples = [
{"input": "0°C", "output": "32°F"},
{"input": "10°C", "output": "50°F"},
{"input": "20°C", "output": "68°F"},
{"input": "30°C", "output": "86°F"},
{"input": "40°C", "output": "104°F"},
]
# TODO: use your organization id here. (by default, org id is your username)
my_activeloop_org_id = "<YOUR-ACTIVELOOP-ORG-ID>"
my_activeloop_dataset_name = "langchain_course_fewshot_selector"
dataset_path = f"hub://{my_activeloop_org_id}/{my_activeloop_dataset_name}"
db = DeepLake(dataset_path=dataset_path)
embeddings = OpenAIEmbeddings(model="text-embedding-ada-002")
example_selector = SemanticSimilarityExampleSelector.from_examples(
examples, embeddings, db, k=1
)
similar_prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=example_prompt,
prefix="Convert the temperature from Celsius to Fahrenheit",
suffix="Input: {temperature}\nOutput:",
input_variables=["temperature"],
)
print(similar_prompt.format(temperature="10°C"))
print(similar_prompt.format(temperature="30°C"))
similar_prompt.example_selector.add_example({"input": "50°C", "output": "122°F"})
print(similar_prompt.format(temperature="40°C"))
Giải thích:
- SemanticSimilarityExampleSelector: Chọn ví dụ dựa trên sự tương đồng ngữ nghĩa với truy vấn đầu vào.
- DeepLake: Một vector store được sử dụng để lưu trữ và truy xuất các embedding.
- OpenAIEmbeddings: Được sử dụng để tạo embedding cho các ví dụ.
- k=1: Chỉ chọn một ví dụ tương tự nhất.
Ưu điểm của Example Selectors:
- Tự động hóa lựa chọn ví dụ: Giảm công sức thủ công.
- Tăng cường sự phù hợp: Chọn các ví dụ phù hợp nhất với truy vấn.
- Tối ưu hóa ngữ cảnh: Quản lý hiệu quả độ dài ngữ cảnh.
- Tăng tính linh hoạt: Cho phép lựa chọn ví dụ theo nhiều tiêu chí khác nhau.
Nhược điểm:
- Yêu cầu thiết lập vector store: Đối với các lựa chọn dựa trên sự tương đồng ngữ nghĩa.
- Phụ thuộc vào chất lượng embedding: Sự tương đồng ngữ nghĩa phụ thuộc vào chất lượng của embedding.
- Vẫn cần tuyển chọn ví dụ ban đầu: Mặc dù tự động hóa lựa chọn, nhưng vẫn cần tạo ra các ví dụ ban đầu.
Managing Outputs with Output Parsers
Trong môi trường production (sản xuất), đầu ra từ các language models (mô hình ngôn ngữ) với cấu trúc dữ liệu dự đoán được thường rất mong muốn. Ví dụ, hãy xem xét việc phát triển một ứng dụng từ điển đồng nghĩa để tạo ra một tập hợp các từ thay thế phù hợp với ngữ cảnh đã cho. Large Language Models (LLMs) có thể tạo ra nhiều gợi ý cho các từ đồng nghĩa hoặc các thuật ngữ tương tự. Dưới đây là một ví dụ về đầu ra từ ChatGPT liệt kê một số từ liên quan chặt chẽ đến “behavior” (hành vi).
Đây là một số từ thay thế cho “behavior”:
- Conduct
- Manner
- Demeanor
- Attitude
- Disposition
- Deportment
- Etiquette
- Protocol
- Performance
- Actions
Thách thức nảy sinh từ việc thiếu một phương pháp động để trích xuất thông tin liên quan từ văn bản được cung cấp. Hãy xem xét việc tách phản hồi theo dòng mới và bỏ qua các dòng ban đầu. Tuy nhiên, cách tiếp cận này không đáng tin cậy vì không có sự đảm bảo rằng phản hồi sẽ duy trì định dạng nhất quán. Danh sách có thể được đánh số hoặc có thể không bao gồm dòng giới thiệu.
Output Parsers cho phép chúng ta xác định một cấu trúc dữ liệu mô tả chính xác những gì được mong đợi từ mô hình. Trong một ứng dụng gợi ý từ, bạn có thể yêu cầu một danh sách các từ hoặc sự kết hợp của các biến khác nhau, chẳng hạn như một từ và một lời giải thích.
1. Output Parsers
Pydantic parser (bộ phân tích Pydantic) rất linh hoạt và có ba loại duy nhất. Tuy nhiên, các tùy chọn khác cũng có sẵn cho các tác vụ ít phức tạp hơn.
Lưu ý: Ứng dụng từ điển đồng nghĩa sẽ đóng vai trò là một ví dụ thực tế để làm rõ các sắc thái của từng cách tiếp cận.
1-1. PydanticOutputParser
Lớp này hướng dẫn mô hình tạo ra đầu ra ở định dạng JSON. Đầu ra của parser có thể được coi là một danh sách, cho phép lập chỉ mục đơn giản các kết quả và loại bỏ các vấn đề về định dạng.
💡 Điều quan trọng cần lưu ý là không phải tất cả các mô hình đều có khả năng tạo ra đầu ra JSON. Vì vậy, tốt nhất là sử dụng một mô hình mạnh mẽ hơn (như GPT-4 Turbo của OpenAI thay vì Davinci/Curie (GPT-3)) để có được kết quả tốt nhất.
Wrapper này sử dụng thư viện Pydantic để xác định và xác thực cấu trúc dữ liệu trong Python. Nó cho phép xác định cấu trúc đầu ra dự kiến, bao gồm tên, loại và mô tả của nó. Ví dụ, một biến phải chứa nhiều gợi ý, như một danh sách, trong ứng dụng từ điển đồng nghĩa. Điều này đạt được bằng cách tạo một lớp kế thừa lớp BaseModel của Pydantic. Hãy nhớ rằng cần phải cài đặt các gói cần thiết bằng lệnh sau trước khi chạy các đoạn code bên dưới: pip install langchain==0.0.208 deeplake openai==0.27.8 tiktoken.
from langchain.output_parsers import PydanticOutputParser
from pydantic import BaseModel, Field, validator
from typing import List
# Define your desired data structure.
class Suggestions(BaseModel):
words: List[str] = Field(description="""list of substitue words based on context""")
# Throw error in case of receiving a numbered-list from API
@validator('words')
def not_start_with_number(cls, field):
for item in field:
if item[0].isnumeric():
raise ValueError("The word can not start with numbers!")
return field
parser = PydanticOutputParser(pydantic_object=Suggestions)
Import các thư viện cần thiết và tạo lớp schema Suggestions, bao gồm hai thành phần quan trọng:
- Expected Outputs (Đầu ra Dự kiến): Mỗi đầu ra được xác định bằng cách khai báo một biến với loại mong muốn, chẳng hạn như một danh sách các chuỗi (: List[str]) trong đoạn code ví dụ. Ngoài ra, nó có thể là một chuỗi đơn (: str) cho các trường hợp mong đợi một từ hoặc câu đơn lẻ làm phản hồi. Bắt buộc phải cung cấp một mô tả ngắn gọn bằng cách sử dụng thuộc tính description của hàm Field, hỗ trợ mô hình trong quá trình suy luận. (Một minh họa về việc xử lý nhiều đầu ra sẽ được trình bày sau trong cuốn sách.)
- Validators (Trình xác thực): Chúng ta có thể khai báo các hàm để xác thực định dạng. Ví dụ: đoạn code được cung cấp có một xác thực để đảm bảo ký tự đầu tiên không phải là số. Tên của hàm không quan trọng, nhưng decorator @validator phải được áp dụng cho biến yêu cầu xác thực (ví dụ: @validator(‘words’)). Lưu ý rằng nếu biến được chỉ định là một danh sách, đối số field trong hàm validator cũng sẽ là một danh sách.
Chúng ta sẽ chuyển lớp đã tạo cho wrapper PydanticOutputParser để biến nó thành một đối tượng parser LangChain. Bước tiếp theo là chuẩn bị prompt.
from langchain.prompts import PromptTemplate
template = """
Offer a list of suggestions to substitue the specified target_word based \
the presented context.
{format_instructions}
target_word={target_word}
context={context}
"""
target_word="behaviour"
context="""The behaviour of the students in the classroom was disruptive and made it difficult for the teacher to conduct the lesson."""
prompt_template = PromptTemplate(
template=template,
input_variables=["target_word", "context"],
partial_variables={"format_instructions": parser.get_format_instructions()}
)
Biến template là một chuỗi kết hợp các placeholder chỉ mục được đặt tên theo định dạng {variable_name}. Biến template xác định các prompt của chúng ta cho mô hình, với định dạng dự kiến từ output parser và các đầu vào (placeholder {format_instructions} sẽ được thay thế bằng các hướng dẫn từ output parser). PromptTemplate nhận chuỗi template, chỉ định loại của từng placeholder. Các placeholder này có thể được phân loại là 1) input_variables, có giá trị được gán sau thông qua phương thức .format_prompt() hoặc 2) partial_variables, được xác định ngay lập tức.
Để truy vấn các mô hình như GPT, prompt sẽ được chuyển cho wrapper OpenAI của LangChain. (Điều quan trọng là phải đặt các biến môi trường OPENAI_API_KEY với API key của bạn từ OpenAI.) Mô hình GPT-3.5 turbo, nổi tiếng với khả năng mạnh mẽ, đảm bảo kết quả tối ưu. Việc đặt giá trị temperature thành 0 cũng đảm bảo rằng kết quả nhất quán và có thể tái tạo.
💡 Giá trị temperature có thể nằm trong khoảng từ 0 đến 1, trong đó số càng cao có nghĩa là mô hình càng sáng tạo. Sử dụng giá trị lớn hơn trong production là một phương pháp tốt cho các tác vụ yêu cầu đầu ra sáng tạo.
from langchain.chat_models import ChatOpenAI
# Before executing the following code, make sure to have
# your OpenAI key saved in the “OPENAI_API_KEY” environment variable.
model_name = 'gpt-3.5-turbo'
temperature = 0.0
model = ChatOpenAI(model_name=model_name, temperature=temperature)
chain = LLMChain(llm=model, prompt=prompt_template)
# Run the LLMChain to get the AI-generated answer
output = chain.run({"target_word": target_word, "context":context})
parser.parse(output)
Suggestions(words=['conduct', 'manner', 'action', 'demeanor', 'attitude',
'activity'])
Hàm parse() của đối tượng parser sẽ chuyển đổi phản hồi chuỗi của mô hình thành định dạng chúng ta đã chỉ định. Bạn có thể lập chỉ mục qua danh sách các từ và sử dụng chúng trong các ứng dụng của mình. Lưu ý sự đơn giản của việc truy cập gợi ý thứ ba bằng cách gọi chỉ mục thứ ba thay vì xử lý một chuỗi dài yêu cầu xử lý trước rộng rãi, như đã trình bày trong ví dụ ban đầu.
Ví dụ về Nhiều Đầu ra (Multiple Outputs Example)
Ví dụ sau đây minh họa một lớp Pydantic được thiết kế để xử lý nhiều đầu ra. Nó hướng dẫn mô hình tạo ra một danh sách các từ và giải thích lý do đằng sau mỗi đề xuất.
Để triển khai ví dụ này, hãy thay thế biến template và lớp Suggestion bằng mã code mới (được cung cấp bên dưới). Các sửa đổi trong prompt template buộc mô hình phải giải thích chi tiết về lý do của nó. Lớp Suggestion được cập nhật giới thiệu một đầu ra mới có tên là reasons. Hàm validator cũng được áp dụng để sửa đổi đầu ra, đảm bảo mỗi lời giải thích kết thúc bằng dấu chấm. Ví dụ này cũng minh họa cách hàm validator có thể được sử dụng để thao tác đầu ra.
template = """
Offer a list of suggestions to substitute the specified target_word based on the presented context and the reasoning for each word.
{format_instructions}
target_word={target_word}
context={context}
"""
class Suggestions(BaseModel):
words: List[str] = Field(description="""list of substitue words based on context""")
reasons: List[str] = Field(description="""the reasoning of why this word fits the context""")
@validator('words')
def not_start_with_number(cls, field):
for item in field:
if item[0].isnumeric():
raise ValueError("The word can not start with numbers!")
return field
@validator('reasons')
def end_with_dot(cls, field):
for idx, item in enumerate( field ):
if item[-1] != ".":
field[idx] += "."
return field
Ví dụ kết quả:
Suggestions(words=['conduct', 'manner', 'demeanor', 'comportment'],
reasons=['refers to the way someone acts in a particular situation.',
'refers to the way someone behaves in a particular situation.',
'refers to the way someone behaves in a particular situation.',
'refers to the way someone behaves in a particular situation.'])
1-2. CommaSeparatedOutputParser
Lớp này chuyên về quản lý đầu ra được phân tách bằng dấu phẩy (comma-separated outputs), tập trung vào các trường hợp mà mô hình được mong đợi tạo ra một danh sách đầu ra. Để sử dụng lớp này một cách hiệu quả, hãy bắt đầu bằng cách nhập module cần thiết.
from langchain.output_parsers import CommaSeparatedListOutputParser
parser = CommaSeparatedListOutputParser()
Parser không yêu cầu bất kỳ cấu hình nào. Do đó, nó ít linh hoạt hơn và chỉ có thể được sử dụng để xử lý các chuỗi được phân tách bằng dấu phẩy. Chúng ta có thể định nghĩa đối tượng bằng cách khởi tạo lớp. Các bước để viết prompt, khởi tạo mô hình và phân tích cú pháp đầu ra như sau:
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
# Prepare the Prompt
template = """
Offer a list of suggestions to substitute the word '{target_word}' based the presented the following text: {context}.
{format_instructions}
"""
prompt_template = PromptTemplate(
template=template,
input_variables=["target_word", "context"],
partial_variables={"format_instructions": parser.get_format_instructions()}
)
# Giả sử model đã được khởi tạo là model
chain = LLMChain(llm=model, prompt=prompt_template)
# Run the LLMChain to get the AI-generated answer
output = chain.run({"target_word": target_word, "context":context})
parser.parse(output)
Ví dụ kết quả:
['Conduct',
'Actions',
'Demeanor',
'Mannerisms',
'Attitude',
'Performance',
'Reactions',
'Interactions',
'Habits',
'Repertoire',
'Disposition',
'Bearing',
'Posture',
'Deportment',
'Comportment']
Mặc dù hầu hết mã code mẫu đã được giải thích trong phần trước, có hai điểm mới. Thứ nhất, chúng ta đã khám phá một kiểu mới cho prompt template. Thứ hai, đầu vào của mô hình được tạo ra bằng cách sử dụng .run() thay vì .format_prompt().to_string(). Sự khác biệt chính giữa mã code này và mã code trong phần trước là chúng ta không còn cần gọi đối tượng .to_string() vì prompt đã là kiểu chuỗi (string).
Kết quả cuối cùng là một danh sách các từ có một số trùng lặp với kỹ thuật PydanticOutputParser nhưng có nhiều sự đa dạng hơn. Tuy nhiên, không thể dựa vào lớp CommaSeparatedOutputParser để làm rõ lý do đằng sau đầu ra của nó.
Giải thích thêm:
- PydanticOutputParser:
- Đây là một cách để định nghĩa cấu trúc đầu ra mong muốn từ mô hình LLM.
- Sử dụng Pydantic, bạn có thể tạo các lớp mô hình để kiểm tra và thao tác đầu ra.
- Cho phép bạn xác định các quy tắc xác thực (validator) để đảm bảo đầu ra đáp ứng các yêu cầu cụ thể.
- Cho phép đưa thêm lý do giải thích cho từng output.
- CommaSeparatedOutputParser:
- Đây là một cách đơn giản hơn để phân tích cú pháp đầu ra được phân tách bằng dấu phẩy.
- Nó phù hợp cho các trường hợp mà bạn chỉ cần một danh sách các mục.
- Ít linh hoạt hơn PydanticOutputParser và không hỗ trợ xác thực phức tạp hoặc thao tác đầu ra.
- Không cho phép đưa ra lý do giải thích cho từng output.
- Prompt Template:
- là khuôn mẫu để xây dựng prompt đầu vào cho LLM.
- Cho phép đưa vào các biến đầu vào, và các hướng dẫn định dạng output.
- Validator:
- Là hàm để kiểm tra và chỉnh sửa output đầu ra.
1-3. StructuredOutputParser
Đây là parser đầu tiên được thêm vào thư viện LangChain. Mặc dù nó có thể xử lý nhiều đầu ra, nhưng nó chỉ hỗ trợ văn bản (text) và không hỗ trợ các kiểu dữ liệu khác như danh sách (lists) hoặc số nguyên (integers). Nó hữu ích khi bạn chỉ muốn một phản hồi từ mô hình. Ví dụ, trong ứng dụng từ điển đồng nghĩa (thesaurus), nó chỉ có thể đề xuất một từ thay thế.
from langchain.output_parsers import StructuredOutputParser, ResponseSchema
response_schemas = [
ResponseSchema(name="words", description="A substitue word based on context"),
ResponseSchema(name="reasons", description="""the reasoning of why this word fits the context.""")
]
parser = StructuredOutputParser.from_response_schemas(response_schemas)
Mã code trên minh họa quá trình định nghĩa schema, mặc dù chi tiết sâu hơn không được thảo luận ở đây. Lớp này không mang lại lợi thế đặc biệt nào; lớp PydanticOutputParser cung cấp xác thực (validation) và tính linh hoạt nâng cao cho các tác vụ phức tạp hơn, và CommaSeparatedOutputParser phù hợp cho các ứng dụng đơn giản hơn.
2. Sửa Lỗi (Fixing Errors)
Parsers đóng vai trò là công cụ mạnh mẽ để trích xuất thông tin từ prompts và cung cấp mức độ xác thực nhất định. Tuy nhiên, chúng không thể đảm bảo phản hồi chính xác cho mọi trường hợp sử dụng. Ví dụ, trong một kịch bản mà một ứng dụng được triển khai, phản hồi của mô hình đối với yêu cầu của người dùng không đầy đủ, dẫn đến việc parser tạo ra lỗi. OutputFixingParser và RetryOutputParser hoạt động như các biện pháp an toàn (fail-safes). Các lớp này thêm một lớp vào phản hồi của mô hình để khắc phục các lỗi.
💡 Các phương pháp sau hoạt động với lớp PydanticOutputParser vì đây là lớp duy nhất có phương thức xác thực.
2-1. OutputFixingParser
Phương pháp này nhằm mục đích sửa lỗi phân tích cú pháp bằng cách kiểm tra phản hồi của mô hình so với mô tả parser đã định nghĩa bằng cách sử dụng Mô hình Ngôn ngữ Lớn (LLM) để giải quyết vấn đề. Để nhất quán với phần còn lại của cuốn sách, GPT-3.5 sẽ được sử dụng, nhưng bất kỳ mô hình tương thích nào cũng sẽ hoạt động. Bước đầu tiên định nghĩa schema dữ liệu Pydantic. Chúng ta đang giới thiệu một lỗi điển hình có thể phát sinh.
from langchain.output_parsers import PydanticOutputParser
from pydantic import BaseModel, Field
from typing import List
# Define your desired data structure.
class Suggestions(BaseModel):
words: List[str] = Field(description="""list of substitue words based on context""")
reasons: List[str] = Field(description="""the reasoning of why this word fits the context""")
parser = PydanticOutputParser(pydantic_object=Suggestions)
missformatted_output = '{"words": ["conduct", "manner"], "reasoning": ["refers to the way someone acts in a particular situation.", "refers to the way someone behaves in a particular situation."]}'
parser.parse(missformatted_output)
Kết quả sẽ là lỗi ValidationError và OutputParserException vì key reasoning không đúng với schema đã định nghĩa là reasons.
from langchain.output_parsers import OutputFixingParser
outputfixing_parser = OutputFixingParser.from_llm(parser=parser, llm=model)
outputfixing_parser.parse(missformatted_output)
Kết quả sau khi dùng OutputFixingParser sẽ sửa lại key reasoning thành reasons và parse đúng theo schema.
Tuy nhiên, cần lưu ý rằng việc giải quyết các vấn đề với lớp OutputFixingParser không phải lúc nào cũng khả thi. Ví dụ sau đây minh họa việc sử dụng lớp OutputFixingParser để giải quyết lỗi liên quan đến key bị thiếu.
missformatted_output = '{"words": ["conduct", "manner"]}'
outputfixing_parser = OutputFixingParser.from_llm(parser=parser, llm=model)
outputfixing_parser.parse(missformatted_output)
Kết quả cho thấy mô hình nhận ra sự vắng mặt của key reasons trong phản hồi nhưng thiếu ngữ cảnh để sửa phản hồi. Do đó, nó tạo ra một danh sách với một mục duy nhất, trong khi mong đợi là có một lý do cho mỗi từ. Hạn chế này nhấn mạnh sự cần thiết đôi khi phải có một phương pháp linh hoạt hơn như lớp RetryOutputParser.
2-2. RetryOutputParser (Bộ phân tích đầu ra thử lại)
Có những tình huống mà bộ phân tích (parser) cần truy cập cả đầu ra (output) và prompt để hiểu đầy đủ ngữ cảnh, như ví dụ trước đó đã nêu. Bước đầu tiên là định nghĩa các biến cần thiết. Các đoạn mã tiếp theo khởi tạo LLM, parser và prompt đã được mô tả trong các phần trước.
from langchain.prompts import PromptTemplate
from langchain.output_parsers import PydanticOutputParser
from pydantic import BaseModel, Field
from typing import List
# Định nghĩa cấu trúc dữ liệu.
class Suggestions(BaseModel):
words: List[str] = Field(description="""danh sách các từ thay thế dựa trên ngữ cảnh""")
reasons: List[str] = Field(description="""lý do tại sao từ này phù hợp với ngữ cảnh""")
parser = PydanticOutputParser(pydantic_object=Suggestions)
# Định nghĩa prompt.
template = """
Đưa ra danh sách các đề xuất để thay thế target_word được chỉ định dựa trên ngữ cảnh được trình bày và lý do cho mỗi từ.
{format_instructions}
target_word={target_word}
context={context}
"""
prompt = PromptTemplate(
template=template,
input_variables=["target_word", "context"],
partial_variables={"format_instructions": parser.get_format_instructions()}
)
model_input = prompt.format_prompt(target_word="behaviour",
context="""The behaviour of the students in the classroom was disruptive and made it difficult for the teacher to conduct the lesson.""")
Bây giờ, đầu ra bị định dạng sai (missformatted_output) tương tự có thể được xử lý bằng lớp RetryWithErrorOutputParser. Lớp này nhận parser đã định nghĩa và một model để tạo một đối tượng parser mới. Tuy nhiên, hàm parse_with_prompt, chịu trách nhiệm sửa lỗi phân tích, yêu cầu cả đầu ra được tạo và prompt.
from langchain.output_parsers import RetryWithErrorOutputParser
missformatted_output = '{"words": ["conduct", "manner"]}'
retry_parser = RetryWithErrorOutputParser.from_llm(parser=parser, llm=model)
retry_parser.parse_with_prompt(missformatted_output, model_input)
Kết quả:
Suggestions(words=['conduct', 'manner'],
reasons=["""The behaviour of the students in the classroom was disruptive and made it difficult for the teacher to conduct the lesson, so 'conduct' is a suitable substitute.""",
"""The students' behaviour was inappropriate, so 'manner' is a suitable substitute."""])
Kết quả cho thấy rằng RetryOutputParser đã giải quyết thành công vấn đề mà OutputFixingParser không thể. Parser hướng dẫn model tạo ra một lý do cho mỗi từ, như yêu cầu.
Trong môi trường production, phương pháp được khuyến nghị để tích hợp các kỹ thuật này là sử dụng phương pháp try...except... để xử lý lỗi. Chiến lược này nắm bắt các lỗi phân tích trong khối except và cố gắng sửa chúng bằng các lớp đã đề cập. Phương pháp này giúp đơn giản hóa quy trình và hạn chế số lượng lệnh gọi API, từ đó giảm chi phí liên quan.