Introduction to Deep Learning with PyTorch
Learn how to build your first neural network, adjust hyperparameters, and tackle classification and regression problems in PyTorch.
Table of contents
- Introduction to PyTorch, a Deep Learning Library
- Creating Our First Neural Network with PyTorch
- Discovering activation functions
- Training Our First Neural Network with PyTorch
- Neural Network Architecture and Hyperparameters
- Evaluating and Improving Models
1. Introduction to PyTorch, a Deep Learning Library
1.1. 1. Học sâu (Deep Learning) là gì?
Tưởng tượng học sâu như một đứa trẻ đang học cách nhận biết con mèo. Ban đầu, bé chỉ có thể phân biệt dựa trên những đặc điểm đơn giản như “có lông”, “4 chân”. Nhưng khi tiếp xúc nhiều hơn, bé sẽ học được những đặc điểm phức tạp hơn như hình dạng tai, mắt, mũi…
Học sâu cũng tương tự như vậy. Nó là một nhánh của trí tuệ nhân tạo (AI), cho phép máy tính “học” từ lượng dữ liệu khổng lồ. Máy tính sẽ tự động tìm ra các đặc trưng từ dữ liệu, từ đơn giản đến phức tạp, để thực hiện các nhiệm vụ như nhận dạng hình ảnh, dịch thuật ngôn ngữ, hay thậm chí là chơi game.
Ví dụ: Bạn có thể “huấn luyện” một mô hình học sâu để nhận biết các loại trái cây khác nhau. Bằng cách cung cấp cho mô hình hàng ngàn bức ảnh về táo, chuối, cam…, mô hình sẽ tự động học cách phân biệt chúng dựa trên màu sắc, hình dạng, kích thước…
1.2. 2. PyTorch: Nền tảng cho học sâu
Để xây dựng các mô hình học sâu, chúng ta cần một công cụ. PyTorch chính là một trong những công cụ phổ biến nhất hiện nay. Nó giống như một “bộ Lego” cho phép bạn lắp ghép các thành phần khác nhau để tạo ra mô hình học sâu của riêng mình.
PyTorch được phát triển bởi Facebook và có những ưu điểm sau:
- Dễ sử dụng: PyTorch sử dụng ngôn ngữ Python, một ngôn ngữ lập trình rất phổ biến và dễ học.
- Linh hoạt: PyTorch cho phép bạn thay đổi mô hình một cách dễ dàng trong quá trình huấn luyện.
- Mạnh mẽ: PyTorch hỗ trợ tính toán trên GPU, giúp tăng tốc quá trình huấn luyện mô hình.
1.3. 3. Tensor: Khối xây dựng của mạng nơ-ron
Trong PyTorch, dữ liệu được lưu trữ và xử lý dưới dạng Tensor. Bạn có thể hiểu Tensor như một mảng nhiều chiều.
- Scalar: là một Tensor 0 chiều, ví dụ như số 5.
- Vector: là một Tensor 1 chiều, ví dụ như [1, 2, 3].
- Ma trận: là một Tensor 2 chiều, ví dụ như một bảng gồm các số.
Ví dụ: Trong bài toán nhận dạng trái cây, mỗi bức ảnh sẽ được biểu diễn dưới dạng một Tensor 3 chiều, với chiều cao, chiều rộng và số kênh màu.
1.4. 4. Thuộc tính của Tensor
Mỗi Tensor đều có những thuộc tính quan trọng:
- shape: Kích thước của Tensor (ví dụ: một Tensor 2x3 có 2 hàng và 3 cột).
- dtype: Kiểu dữ liệu của Tensor (ví dụ: int, float).
- device: Thiết bị lưu trữ Tensor (CPU hoặc GPU).
1.5. 5. Bắt đầu với các phép toán Tensor
PyTorch cung cấp rất nhiều hàm để thực hiện các phép toán trên Tensor, ví dụ như cộng, trừ, nhân, chia, chuyển vị…
Example:
import torch
# Tạo 2 Tensor
x = torch.tensor([1, 2, 3])
y = torch.tensor([4, 5, 6])
# Cộng 2 Tensor
z = x + y # z sẽ là [5, 7, 9]
# Import PyTorch
import torch
temperatures = [[72, 75, 78], [70, 73, 76]]
# Create a tensor from temperatures
temp_tensor = torch.tensor(temperatures)
temperatures = torch.tensor([[72, 75, 78], [70, 73, 76]])
adjustment = torch.tensor([[2, 2, 2], [2, 2, 2]])
# Check the shape of the temperatures tensor
temp_shape = temperatures.shape
print("Shape of temperatures:", temp_shape)
# Check the type of the temperatures tensor
temp_type = temperatures.dtype
print("Data type of temperatures:", temp_type)
# Adjust the temperatures by adding the adjustment tensor
corrected_temperatures = temperatures + adjustment
print("Corrected temperatures:", corrected_temperatures)
2. Creating Our First Neural Network with PyTorch
Bây giờ chúng ta sẽ cùng nhau xây dựng một mạng nơ-ron (neural network) đơn giản bằng PyTorch. Hãy tưởng tượng mạng nơ-ron như một cỗ máy với nhiều tầng lớp, mỗi tầng sẽ xử lý thông tin và truyền cho tầng tiếp theo.
2.1. 1. Tầng Linear (Linear Layer)
Linear layer là một trong những tầng cơ bản nhất trong mạng nơ-ron. Nó thực hiện một phép biến đổi tuyến tính trên dữ liệu đầu vào. Hãy tưởng tượng nó như một hàm số đơn giản y = ax + b, với:
- x: dữ liệu đầu vào
- a: trọng số (weight)
- b: độ lệch (bias)
- y: dữ liệu đầu ra
Mỗi linear layer có một tập hợp các weight và bias riêng. Trong quá trình huấn luyện, mạng nơ-ron sẽ tự động điều chỉnh các weight và bias này để đạt được kết quả tốt nhất.
Ví dụ: Ta có một linear layer với 2 đầu vào và 3 đầu ra. Khi đó, weight sẽ là một ma trận 2x3 và bias sẽ là một vector 3 chiều.
2.2. 2. Xếp chồng các tầng với nn.Sequential()
Để xây dựng một mạng nơ-ron phức tạp hơn, ta cần xếp chồng nhiều layer lên nhau. PyTorch cung cấp hàm nn.Sequential() để làm điều này.
nn.Sequential() cho phép bạn định nghĩa một chuỗi các layer. Dữ liệu sẽ đi qua các layer theo thứ tự bạn đã định nghĩa.
Ví dụ:
import torch.nn as nn
# Định nghĩa một mạng nơ-ron với 2 tầng linear
model = nn.Sequential(
nn.Linear(2, 5), # Tầng 1: 2 đầu vào, 5 đầu ra
nn.Linear(5, 1) # Tầng 2: 5 đầu vào, 1 đầu ra
)
Trong ví dụ trên, dữ liệu đầu vào sẽ đi qua tầng linear thứ nhất, sau đó đi qua tầng linear thứ hai để tạo ra kết quả cuối cùng.
Tóm lại:
- Mạng nơ-ron là một tập hợp các layer xếp chồng lên nhau.
- Linear layer là một tầng cơ bản thực hiện phép biến đổi tuyến tính.
nn.Sequential()giúp bạn xếp chồng các layer một cách dễ dàng.
Bằng cách kết hợp các layer khác nhau, bạn có thể xây dựng những mạng nơ-ron mạnh mẽ để giải quyết nhiều bài toán phức tạp.
Example:
import torch
import torch.nn as nn
input_tensor = torch.Tensor([[2, 3, 6, 7, 9, 3, 2, 1]])
# Implement a small neural network with two linear layers
model = nn.Sequential(nn.Linear(8, 8),
nn.Linear(8, 1)
)
output = model(input_tensor)
print(output)
3. Discovering activation functions
3.1. 1. Các phép toán tuyến tính xếp chồng (Stacked linear operations)
Như đã biết, linear layer thực hiện phép biến đổi tuyến tính. Vậy nếu ta xếp chồng nhiều linear layer lên nhau thì sao? Thực chất, kết quả vẫn chỉ là một phép biến đổi tuyến tính!
Hãy tưởng tượng bạn có 2 hàm số tuyến tính: y = 2x + 3 và z = 5y - 1. Nếu ta thay y từ phương trình thứ nhất vào phương trình thứ hai, ta sẽ được z = 5(2x + 3) - 1 = 10x + 14, vẫn là một hàm số tuyến tính.
Điều này có nghĩa là dù có xếp chồng bao nhiêu linear layer đi nữa, mạng nơ-ron của chúng ta cũng chỉ có thể học được các mối quan hệ tuyến tính. Vậy làm sao để mô hình học được những mối quan hệ phức tạp hơn? Câu trả lời chính là hàm kích hoạt (activation functions).
3.2. 2. Tại sao cần hàm kích hoạt?
Hàm kích hoạt giúp đưa phi tuyến tính vào mạng nơ-ron. Nói cách khác, chúng giúp mô hình học được những mối quan hệ phức tạp, không chỉ đơn thuần là đường thẳng.
Ví dụ: Hãy tưởng tượng bạn muốn huấn luyện một mô hình để phân loại ảnh là “mèo” hoặc “không phải mèo”. Nếu chỉ dùng linear layer, mô hình sẽ gặp khó khăn trong việc phân biệt những trường hợp phức tạp, ví dụ như con mèo đang nằm cuộn tròn hay bị che khuất một phần.
3.3. 3. Hàm Sigmoid
Sigmoid là một hàm kích hoạt phổ biến. Nó biến đổi đầu vào thành một giá trị nằm trong khoảng từ 0 đến 1.
Ví dụ: Sigmoid thường được dùng trong các bài toán phân loại nhị phân (2 lớp), ví dụ như phân loại “spam” / “không phải spam”. Giá trị đầu ra của Sigmoid có thể được hiểu là xác suất thuộc về một lớp nào đó.

3.4. 4. Hàm Softmax
Softmax cũng là một hàm kích hoạt thường được dùng trong các bài toán phân loại. Tuy nhiên, nó được sử dụng cho các bài toán phân loại nhiều lớp.
Ví dụ: Trong bài toán nhận dạng trái cây, Softmax sẽ tính toán xác suất để bức ảnh thuộc về mỗi loại trái cây (táo, chuối, cam…). Lớp có xác suất cao nhất sẽ là kết quả dự đoán của mô hình.
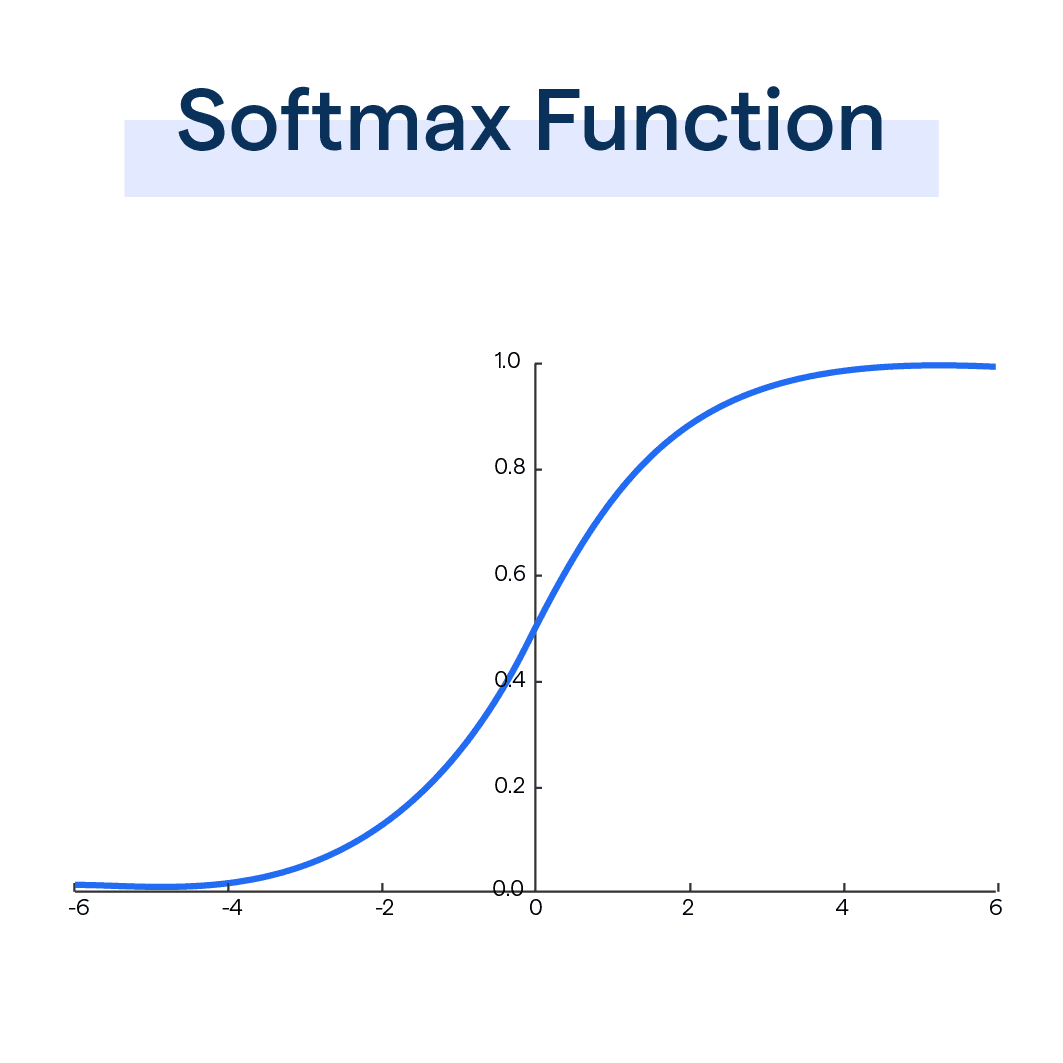
Tóm lại:
- Hàm kích hoạt đưa phi tuyến tính vào mạng nơ-ron, giúp mô hình học được những mối quan hệ phức tạp.
- Sigmoid thường được dùng trong phân loại nhị phân.
- Softmax thường được dùng trong phân loại nhiều lớp.
Bằng cách kết hợp các layer và hàm kích hoạt khác nhau, bạn có thể xây dựng những mạng nơ-ron mạnh mẽ để giải quyết nhiều bài toán trong thực tế.
3.5. Sự khác nhau về mặt toán học giữa Sigmoid và Softmax
Cả Sigmoid và Softmax đều là những hàm kích hoạt quan trọng trong học sâu, nhưng chúng có những điểm khác biệt rõ rệt về mặt toán học và ứng dụng.
1. Công thức toán học:
- Sigmoid:
- Áp dụng cho mỗi đầu vào z riêng biệt.
- Công thức:
- Đầu ra: Một giá trị trong khoảng từ 0 đến 1.
- Softmax:
- Áp dụng cho một vector đầu vào z = [z1, z2, …, zC] với C là số lớp.
- Công thức cho mỗi phần tử zi:
- Đầu ra: Một vector C chiều với các giá trị trong khoảng từ 0 đến 1, và tổng các giá trị bằng 1.


2. Ứng dụng:
- Sigmoid: Thường được dùng trong bài toán phân loại nhị phân (hai lớp). Đầu ra của Sigmoid có thể được hiểu là xác suất dữ liệu thuộc về lớp “1”. Ví dụ:
- Phân loại email spam/không spam.
- Phát hiện gian lận trong giao dịch tài chính.
- Chẩn đoán bệnh dựa trên hình ảnh y tế.
- Softmax: Thường được dùng trong bài toán phân loại nhiều lớp. Đầu ra của Softmax là một vector xác suất, mỗi giá trị tương ứng với xác suất dữ liệu thuộc về một lớp. Ví dụ:
- Nhận dạng chữ số viết tay (0 đến 9).
- Phân loại ảnh (chó, mèo, chim,…).
- Dịch máy (dịch một câu sang nhiều ngôn ngữ khác nhau).
Tại sao có sự khác biệt này?
-
Sigmoid hoạt động độc lập trên từng đầu vào, nên nó phù hợp với việc đưa ra xác suất cho mỗi lớp một cách riêng biệt. Trong phân loại nhị phân, ta chỉ cần biết xác suất dữ liệu thuộc về một lớp (lớp còn lại sẽ có xác suất ngược lại).
-
Softmax xem xét tất cả các đầu vào cùng lúc và chuẩn hóa chúng để tổng các xác suất bằng 1. Điều này rất quan trọng trong phân loại nhiều lớp, vì ta cần so sánh xác suất của dữ liệu thuộc về tất cả các lớp để đưa ra dự đoán chính xác.
Tóm lại:
Sự khác biệt về mặt toán học giữa Sigmoid và Softmax dẫn đến sự khác biệt trong ứng dụng của chúng. Sigmoid phù hợp với phân loại nhị phân, trong khi Softmax phù hợp với phân loại nhiều lớp.
3.6. Example:
input_tensor = torch.tensor([[0.8]])
# Create a sigmoid function and apply it on input_tensor
sigmoid = nn.Sigmoid()
probability = sigmoid(input_tensor)
print(probability)
# tensor([[0.6900]])
input_tensor = torch.tensor([[1.0, -6.0, 2.5, -0.3, 1.2, 0.8]])
# Create a softmax function and apply it on input_tensor
softmax = nn.Softmax()
probabilities = softmax(input_tensor)
print(probabilities)
# tensor([[1.2828e-01, 1.1698e-04, 5.7492e-01, 3.4961e-02, 1.5669e-01, 1.0503e-01]])
4. Training Our First Neural Network with PyTorch
4.1. Running a forward pass
1. Lượt truyền xuôi (Forward Pass) là gì?
Hãy tưởng tượng mạng nơ-ron như một nhà máy với nhiều công đoạn. Dữ liệu đầu vào sẽ đi qua từng công đoạn (layer) để được xử lý và biến đổi, cuối cùng tạo ra sản phẩm đầu ra. Lượt truyền xuôi chính là quá trình dữ liệu đi từ đầu vào đến đầu ra của mạng nơ-ron.
Ví dụ: Trong bài toán nhận dạng trái cây, ảnh đầu vào sẽ đi qua các layer của mạng nơ-ron, mỗi layer sẽ trích xuất các đặc trưng khác nhau (màu sắc, hình dạng,…) để cuối cùng đưa ra dự đoán loại trái cây.
2. Có lượt truyền ngược (Backward Pass) không?
Câu trả lời là có! Lượt truyền ngược là quá trình tính toán gradient của hàm mất mát (loss function) theo các weight của mạng nơ-ron. Gradient cho biết hướng và độ lớn cần điều chỉnh weight để giảm thiểu loss. Nói cách khác, lượt truyền ngược giúp mạng nơ-ron “học” từ dữ liệu.
3. Phân loại nhị phân (Binary Classification): Lượt truyền xuôi
Trong phân loại nhị phân, đầu ra của mạng nơ-ron thường là một giá trị trong khoảng từ 0 đến 1, biểu thị xác suất dữ liệu thuộc về lớp “1”. Ta thường sử dụng hàm sigmoid ở layer cuối cùng để đảm bảo điều này.
Ví dụ: Xây dựng một mô hình phân loại email spam/không spam. Đầu vào là nội dung email, đầu ra là xác suất email là spam.
4. Phân loại nhiều lớp (Multi-class Classification): Lượt truyền xuôi
Trong phân loại nhiều lớp, đầu ra của mạng nơ-ron thường là một vector xác suất, mỗi giá trị tương ứng với xác suất dữ liệu thuộc về một lớp. Ta thường sử dụng hàm softmax ở layer cuối cùng để đảm bảo tổng các xác suất bằng 1.
Ví dụ: Xây dựng một mô hình nhận dạng chữ số viết tay (0 đến 9). Đầu vào là ảnh chữ số, đầu ra là một vector 10 chiều biểu thị xác suất chữ số thuộc về mỗi lớp.
5. Hồi quy (Regression): Lượt truyền xuôi
Trong bài toán hồi quy, đầu ra của mạng nơ-ron là một giá trị liên tục. Ta thường không sử dụng hàm kích hoạt ở layer cuối cùng hoặc sử dụng các hàm như ReLU để đảm bảo đầu ra không bị giới hạn.
Ví dụ: Xây dựng một mô hình dự đoán giá nhà dựa trên các đặc trưng như diện tích, số phòng ngủ,… Đầu vào là các đặc trưng của ngôi nhà, đầu ra là giá trị dự đoán.
Tóm lại:
- Lượt truyền xuôi là quá trình dữ liệu đi từ đầu vào đến đầu ra của mạng nơ-ron.
- Lượt truyền ngược giúp mạng nơ-ron “học” từ dữ liệu.
- Tùy vào bài toán cụ thể (phân loại nhị phân, phân loại nhiều lớp, hồi quy) mà ta sẽ sử dụng các hàm kích hoạt và kiến trúc mạng nơ-ron khác nhau.
Example
- Building a binary classifier in PyTorch
import torch
import torch.nn as nn
input_tensor = torch.Tensor([[3, 4, 6, 2, 3, 6, 8, 9]])
# Implement a small neural network for binary classification
model = nn.Sequential(
nn.Linear(8, 1),
nn.Sigmoid()
)
output = model(input_tensor)
print(output)
- Multi-class classification
import torch
import torch.nn as nn
input_tensor = torch.Tensor([[3, 4, 6, 7, 10, 12, 2, 3, 6, 8, 9]])
# Update network below to perform a multi-class classification with four labels
model = nn.Sequential(
nn.Linear(11, 20),
nn.Linear(20, 12),
nn.Linear(12, 6),
nn.Linear(6, 4),
nn.Softmax(-1)
)
output = model(input_tensor)
print(output)
4.2. Using loss functions to assess model predictions
1. Tại sao cần hàm mất mát (Loss Function)?
Trong quá trình huấn luyện mạng nơ-ron, mục tiêu của chúng ta là tìm ra bộ weight tốt nhất để mô hình đưa ra dự đoán chính xác. Vậy làm sao để biết bộ weight nào là “tốt”? Đó chính là lúc cần đến hàm mất mát (loss function).
Loss function đo lường sự khác biệt giữa dự đoán của mô hình và giá trị thực tế. Loss càng nhỏ thì mô hình dự đoán càng chính xác.
Ví dụ: Bạn đang huấn luyện một mô hình dự đoán giá nhà. Giá trị thực tế của một ngôi nhà là 5 tỷ đồng, nhưng mô hình dự đoán là 4 tỷ đồng. Loss function sẽ tính toán sự sai lệch này (1 tỷ đồng) để đánh giá độ chính xác của mô hình.
2. Khái niệm mã hóa one-hot (One-hot Encoding)
Trong các bài toán phân loại, nhãn (label) thường được biểu diễn dưới dạng số nguyên. Ví dụ, trong bài toán nhận dạng chữ số viết tay, nhãn sẽ là các số từ 0 đến 9. Tuy nhiên, để tính toán loss hiệu quả, ta thường sử dụng one-hot encoding để chuyển đổi nhãn thành dạng vector.
One-hot encoding biểu diễn mỗi nhãn bằng một vector có độ dài bằng số lượng lớp. Tất cả các giá trị trong vector đều bằng 0, ngoại trừ vị trí tương ứng với nhãn đó sẽ bằng 1.
Ví dụ: Trong bài toán nhận dạng chữ số, nhãn “3” sẽ được mã hóa thành vector [0, 0, 0, 1, 0, 0, 0, 0, 0, 0].
3. Chuyển đổi nhãn bằng one-hot encoding trong PyTorch
PyTorch cung cấp hàm torch.nn.functional.one_hot() để thực hiện one-hot encoding.
import torch.nn.functional as F
labels = torch.tensor([1, 0, 3]) # Các nhãn ban đầu
num_classes = 5 # Số lượng lớp
one_hot_labels = F.one_hot(labels, num_classes=num_classes)
# one_hot_labels sẽ là:
# tensor([[0, 1, 0, 0, 0],
# [1, 0, 0, 0, 0],
# [0, 0, 0, 1, 0]])
4. Hàm mất mát Cross Entropy Loss trong PyTorch
Cross entropy loss là một hàm mất mát phổ biến trong các bài toán phân loại. Nó đo lường sự khác biệt giữa phân phối xác suất dự đoán của mô hình và phân phối xác suất thực tế (one-hot encoding của nhãn).
PyTorch cung cấp hàm torch.nn.CrossEntropyLoss() để tính toán cross entropy loss.
import torch.nn as nn
criterion = nn.CrossEntropyLoss()
# ... (tính toán output của mô hình) ...
loss = criterion(output, labels) # labels là tensor chứa các nhãn
Tóm lại:
- Loss function giúp đánh giá độ chính xác của mô hình.
- One-hot encoding chuyển đổi nhãn thành dạng vector để tính toán loss hiệu quả.
- Cross entropy loss là một hàm mất mát phổ biến trong phân loại.
Bằng cách sử dụng loss function phù hợp, bạn có thể huấn luyện mạng nơ-ron hiệu quả và đạt được kết quả tốt nhất.
Example
import torch
import torch.nn.functional as F
from torch.nn import CrossEntropyLoss
y = [2]
scores = torch.tensor([[0.1, 6.0, -2.0, 3.2]])
# Create a one-hot encoded vector of the label y
one_hot_label = F.one_hot(torch.tensor(y), scores.shape[1])
# Create the cross entropy loss function
criterion = CrossEntropyLoss()
# Calculate the cross entropy loss
loss = criterion(scores.double(), one_hot_label.double())
print(loss)
4.3. Using derivatives to update model parameters
1. Tối thiểu hóa Loss
Như đã biết, loss function đo lường sự khác biệt giữa dự đoán của mô hình và giá trị thực tế. Mục tiêu của huấn luyện mạng nơ-ron là tìm ra bộ weight tối ưu để loss đạt giá trị nhỏ nhất. Quá trình này được gọi là tối thiểu hóa loss.
2. Mối liên hệ giữa đạo hàm và huấn luyện mô hình
Vậy làm sao để tìm ra bộ weight tối ưu? Đạo hàm chính là chìa khóa! Đạo hàm của loss function theo weight cho biết hướng và độ lớn cần điều chỉnh weight để giảm thiểu loss.
Ví dụ: Hãy tưởng tượng bạn đang leo núi và muốn tìm đường xuống chân núi nhanh nhất. Loss function giống như độ cao của bạn so với chân núi. Đạo hàm sẽ cho biết hướng dốc nhất để bạn đi xuống.
3. Khái niệm Lan truyền ngược (Backpropagation)
Backpropagation là một thuật toán sử dụng chuỗi quy tắc (chain rule) để tính toán đạo hàm của loss function theo các weight trong mạng nơ-ron. Nói cách khác, backpropagation lan truyền gradient từ output layer ngược về input layer.
4. Backpropagation trong PyTorch
PyTorch tự động thực hiện backpropagation cho bạn. Bạn chỉ cần gọi hàm loss.backward() sau khi tính toán loss.
# ... (tính toán loss) ...
loss.backward() # Tính toán gradient
5. Cập nhật tham số mô hình
Sau khi có gradient, ta sẽ cập nhật weight theo hướng ngược với gradient để giảm thiểu loss. Quá trình này thường được thực hiện bởi optimizer.
optimizer.step() # Cập nhật weight
6. Hàm lồi (Convex) và hàm không lồi (Non-convex)
Hàm lồi có dạng hình cái bát úp ngược, chỉ có một điểm cực tiểu toàn cục. Hàm không lồi có thể có nhiều điểm cực tiểu cục bộ. Loss function trong học sâu thường là hàm không lồi.
7. Hạ Gradient (Gradient Descent)
Gradient descent là một thuật toán tối ưu hóa lặp đi lặp lại để tìm điểm cực tiểu của hàm số. Nó bắt đầu từ một điểm ngẫu nhiên, sau đó di chuyển theo hướng ngược với gradient cho đến khi đạt đến điểm cực tiểu.
Ví dụ: Hãy tưởng tượng bạn đang đứng trên một ngọn đồi và muốn tìm đường xuống chân đồi. Bạn sẽ đi từng bước nhỏ theo hướng dốc nhất cho đến khi đến được chân đồi.
Tóm lại:
- Đạo hàm giúp xác định hướng và độ lớn cần điều chỉnh weight để giảm thiểu loss.
- Backpropagation tính toán đạo hàm của loss function theo các weight.
- Gradient descent là một thuật toán tối ưu hóa sử dụng gradient để tìm điểm cực tiểu của hàm số.
Bằng cách kết hợp các kỹ thuật này, bạn có thể huấn luyện mạng nơ-ron hiệu quả và đạt được kết quả tốt nhất.
Example
- Accessing the model parameters
model = nn.Sequential(nn.Linear(16, 8),
nn.Linear(8, 2)
)
# Access the weight of the first linear layer
weight_0 = model[0].weight
# Access the bias of the second linear layer
bias_1 = model[1].bias
- Updating the weights manually
weight0 = model[0].weight
weight1 = model[1].weight
weight2 = model[2].weight
# Access the gradients of the weight of each linear layer
grads0 = weight0.grad
grads1 = weight1.grad
grads2 = weight2.grad
# Update the weights using the learning rate and the gradients
weight0 = weight0 - lr*grads0
weight1 = weight1 - lr*grads1
weight2 = weight2 - lr*grads2
- Using the PyTorch optimizer
# Create the optimizer
optimizer = optim.SGD(model.parameters(), lr=0.001)
loss = criterion(pred, target)
loss.backward()
# Update the model's parameters using the optimizer
optimizer.step()
4.4. Writing our first training loop
1. Huấn luyện mạng nơ-ron trong PyTorch
Huấn luyện mạng nơ-ron là quá trình điều chỉnh các weight của mô hình để nó có thể đưa ra dự đoán chính xác. Quá trình này bao gồm nhiều bước lặp đi lặp lại, mỗi bước được gọi là một epoch. Trong mỗi epoch, ta sẽ thực hiện các bước sau:
- Forward pass: Cho dữ liệu vào mô hình và tính toán output.
- Tính toán loss: So sánh output với giá trị thực tế bằng loss function.
- Backpropagation: Tính toán gradient của loss theo các weight.
- Cập nhật weight: Điều chỉnh weight theo hướng ngược với gradient.
2. Giới thiệu hàm mất mát Mean Squared Error (MSE) trong PyTorch
Mean Squared Error (MSE) là một hàm mất mát phổ biến trong các bài toán hồi quy (Regression). Nó tính bình phương trung bình của hiệu số giữa giá trị dự đoán và giá trị thực tế.
PyTorch cung cấp hàm torch.nn.MSELoss() để tính toán MSE loss.
criterion = nn.MSELoss()
# ... (tính toán output của mô hình) ...
loss = criterion(output, target) # target là tensor chứa giá trị thực tế
3. Trước vòng lặp huấn luyện trong PyTorch
Trước khi bắt đầu vòng lặp huấn luyện, ta cần thực hiện một số bước chuẩn bị:
- Chuẩn bị dữ liệu: Tải dữ liệu huấn luyện và kiểm tra.
- Khởi tạo mô hình: Tạo một instance của mạng nơ-ron.
- Chọn optimizer: Chọn thuật toán tối ưu hóa để cập nhật weight (ví dụ: Stochastic Gradient Descent (SGD), Adam).
- Chọn loss function: Chọn hàm mất mát phù hợp với bài toán (ví dụ: MSE, Cross Entropy).
4. Vòng lặp huấn luyện trong PyTorch
for epoch in range(num_epochs):
# 1. Forward pass
output = model(input)
# 2. Tính toán loss
loss = criterion(output, target)
# 3. Backpropagation
optimizer.zero_grad() # Xóa gradient cũ
loss.backward() # Tính toán gradient mới
# 4. Cập nhật weight
optimizer.step()
# ... (in ra loss hoặc các thông tin khác) ...
Ví dụ: Huấn luyện một mô hình dự đoán giá nhà.
import torch
import torch.nn as nn
import torch.optim as optim
# ... (chuẩn bị dữ liệu, khởi tạo mô hình) ...
criterion = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
for epoch in range(num_epochs):
# ... (vòng lặp huấn luyện như trên) ...
Tóm lại:
- Vòng lặp huấn luyện là quá trình lặp đi lặp lại các bước forward pass, tính toán loss, backpropagation và cập nhật weight.
- MSE loss là một hàm mất mát phổ biến trong hồi quy.
- Trước khi huấn luyện, ta cần chuẩn bị dữ liệu, khởi tạo mô hình, chọn optimizer và loss function.
Example
- Using the MSELoss
y_pred = np.array(10)
y = np.array(1)
# Calculate the MSELoss using NumPy
mse_numpy = np.mean((y_pred - y)**2)
# Create the MSELoss function
criterion = nn.MSELoss()
# Calculate the MSELoss using the created loss function
mse_pytorch = criterion(torch.from_numpy(y_pred).double(), torch.from_numpy(y).double())
print(mse_pytorch)
- Writing a training loop
# Loop over the number of epochs and the dataloader
for i in range(num_epochs):
for data in dataloader:
# Set the gradients to zero
optimizer.zero_grad()
# Run a forward pass
feature, target = data
prediction = model(feature)
# Calculate the loss
loss = criterion(prediction, target)
# Compute the gradients
loss.backward()
# Update the model's parameters
optimizer.step()
show_results(model, dataloader)
5. Neural Network Architecture and Hyperparameters
5.1. Discovering activation functions
1. Hạn chế của hàm Sigmoid và Softmax
Mặc dù Sigmoid và Softmax là những hàm kích hoạt phổ biến, chúng cũng có những hạn chế nhất định:
- Vanishing Gradient: Khi đầu vào của Sigmoid hoặc Softmax rất lớn hoặc rất nhỏ, đạo hàm của chúng sẽ rất gần bằng 0. Điều này gây ra hiện tượng vanishing gradient, làm chậm quá trình huấn luyện, đặc biệt là với mạng nơ-ron sâu.
- Sigmoid không zero-centered: Đầu ra của Sigmoid luôn dương, dẫn đến gradient luôn dương hoặc luôn âm. Điều này có thể làm cho quá trình tối ưu hóa loss function trở nên khó khăn hơn.
2. Giới thiệu hàm ReLU (Rectified Linear Unit)
ReLU là một hàm kích hoạt đơn giản và hiệu quả, được định nghĩa như sau:
ReLU(x) = max(0, x)
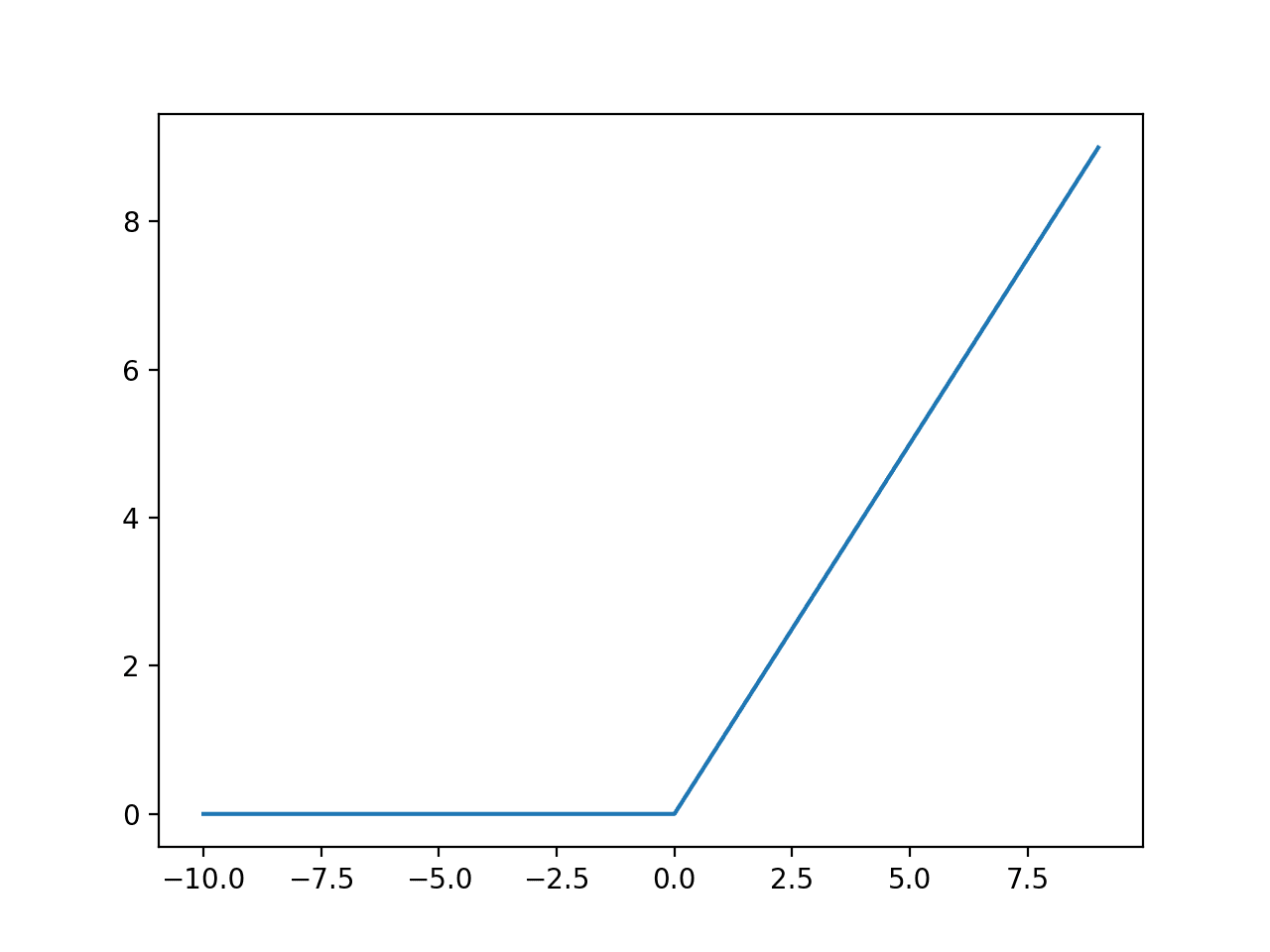
Nói cách khác, ReLU sẽ trả về giá trị x nếu x dương, ngược lại trả về 0.
Ưu điểm của ReLU:
- Khắc phục vanishing gradient: Đạo hàm của ReLU bằng 1 khi x > 0, giúp giảm thiểu hiện tượng vanishing gradient.
- Tính toán nhanh: ReLU rất đơn giản để tính toán, giúp tăng tốc quá trình huấn luyện.
- Thúc đẩy sparsity: ReLU trả về 0 khi x < 0, giúp tạo ra các mạng nơ-ron thưa (sparse), hiệu quả hơn về mặt tính toán.
Ví dụ:
import torch
x = torch.tensor([-1, 0, 1])
relu_x = torch.relu(x) # relu_x sẽ là tensor([0, 0, 1])
3. Giới thiệu hàm Leaky ReLU
Leaky ReLU là một biến thể của ReLU, được thiết kế để khắc phục nhược điểm “dying ReLU” (các neuron luôn trả về 0 khi x < 0).
Leaky ReLU được định nghĩa như sau:
LeakyReLU(x) = max(0.1x, x)
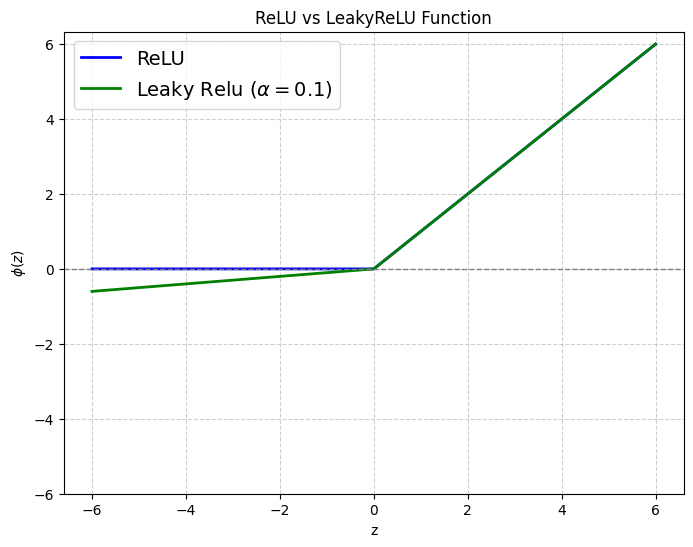
Nói cách khác, Leaky ReLU sẽ trả về giá trị x nếu x dương, ngược lại trả về 0.1x.
Ưu điểm của Leaky ReLU:
- Khắc phục dying ReLU: Leaky ReLU cho phép một lượng nhỏ gradient đi qua ngay cả khi x < 0, giúp ngăn chặn các neuron “chết”.
Ví dụ:
import torch
x = torch.tensor([-1, 0, 1])
leaky_relu_x = torch.nn.functional.leaky_relu(x, negative_slope=0.1)
# leaky_relu_x sẽ là tensor([-0.1, 0, 1])
Tóm lại:
- ReLU và Leaky ReLU là những hàm kích hoạt hiệu quả, khắc phục được một số hạn chế của Sigmoid và Softmax.
- ReLU đơn giản và nhanh chóng, trong khi Leaky ReLU giúp ngăn chặn “dying ReLU”.
Bằng cách lựa chọn hàm kích hoạt phù hợp, bạn có thể cải thiện hiệu suất của mạng nơ-ron.
Example
- Implementing ReLU
# Create a ReLU function with PyTorch
relu_pytorch = nn.ReLU()
# Apply your ReLU function on x, and calculate gradients
x = torch.tensor(-1.0, requires_grad=True)
y = relu_pytorch(x)
y.backward()
# Print the gradient of the ReLU function for x
gradient = x.grad
print(gradient)
- Implementing leaky ReLU
# Create a leaky relu function in PyTorch
leaky_relu_pytorch = nn.LeakyReLU(negative_slope=0.05)
x = torch.tensor(-2.0)
# Call the above function on the tensor x
output = leaky_relu_pytorch(x)
print(output)
5.2. A deeper dive into neural network architecture
1. Các tầng (Layers) được tạo thành từ các nơ-ron (Neurons)
Hãy tưởng tượng mỗi layer trong mạng nơ-ron như một nhóm các neuron. Mỗi neuron nhận đầu vào, thực hiện một phép tính, và tạo ra đầu ra.
Ví dụ: Trong một linear layer, mỗi neuron thực hiện phép tính y = wx + b, với w là weight, x là đầu vào, b là bias, và y là đầu ra.
2. Quy ước đặt tên Layer
Trong mạng nơ-ron, các layer thường được đặt tên theo chức năng của chúng. Ví dụ:
- Input layer: Tầng nhận dữ liệu đầu vào.
- Hidden layer: Các tầng nằm giữa input layer và output layer.
- Output layer: Tầng tạo ra kết quả dự đoán.
3. Điều chỉnh số lượng Hidden Layer
Số lượng hidden layer ảnh hưởng đến khả năng học của mạng nơ-ron.
- Mạng nơ-ron nông (Shallow network): Có ít hidden layer. Thường phù hợp với các bài toán đơn giản.
- Mạng nơ-ron sâu (Deep network): Có nhiều hidden layer. Có khả năng học các đặc trưng phức tạp hơn, nhưng cũng dễ bị overfitting (học thuộc lòng dữ liệu huấn luyện) nếu không được điều chỉnh cẩn thận.
4. Đếm số lượng tham số (Parameters)
Tham số của mạng nơ-ron là các weight và bias cần được học trong quá trình huấn luyện. Số lượng parameter ảnh hưởng đến khả năng biểu diễn của mô hình và thời gian huấn luyện.
Ví dụ: Một linear layer có 10 đầu vào và 5 đầu ra sẽ có (10 * 5) + 5 = 55 parameter (10 * 5 weight và 5 bias).
Tóm lại:
- Layer được tạo thành từ các neuron.
- Layer được đặt tên theo chức năng của chúng.
- Số lượng hidden layer ảnh hưởng đến khả năng học của mạng nơ-ron.
- Số lượng parameter ảnh hưởng đến khả năng biểu diễn và thời gian huấn luyện.
Hiểu rõ về kiến trúc mạng nơ-ron giúp bạn thiết kế và huấn luyện mô hình hiệu quả hơn.
Example
- Counting the number of parameters
model = nn.Sequential(nn.Linear(16, 4),
nn.Linear(4, 2),
nn.Linear(2, 1))
total = 0
# Calculate the number of parameters in the model
for param in model.parameters():
total += param.numel()
print(f"The number of parameters in the model is {total}")
- Manipulating the capacity of a network
def calculate_capacity(model):
total = 0
for p in model.parameters():
total += p.numel()
return total
5.3. Learning rate and momentum
1. Cập nhật trọng số (Weights) với SGD
Stochastic Gradient Descent (SGD) là một thuật toán tối ưu hóa phổ biến để cập nhật weight trong mạng nơ-ron. Trong mỗi bước, SGD tính toán gradient của loss function và cập nhật weight theo hướng ngược với gradient.
2. Ảnh hưởng của Learning Rate: Tốc độ học tối ưu (Optimal Learning Rate)
Learning rate quyết định “bước nhảy” khi cập nhật weight. Một learning rate tối ưu sẽ giúp mô hình hội tụ nhanh chóng đến điểm tối ưu của loss function.
Ví dụ: Hãy tưởng tượng bạn đang đi xuống dốc. Learning rate giống như độ dài bước chân của bạn. Nếu bước chân vừa phải, bạn sẽ đi xuống dốc một cách nhanh chóng và an toàn.
3. Ảnh hưởng của Learning Rate: Tốc độ học nhỏ (Small Learning Rate)
Nếu learning rate quá nhỏ, mô hình sẽ cập nhật weight rất chậm, dẫn đến thời gian huấn luyện lâu và có thể bị mắc kẹt tại điểm cực tiểu cục bộ.
Ví dụ: Nếu bước chân quá nhỏ, bạn sẽ mất rất nhiều thời gian để đi xuống dốc và có thể bị kẹt lại ở một chỗ lõm.
4. Ảnh hưởng của Learning Rate: Tốc độ học lớn (High Learning Rate)
Nếu learning rate quá lớn, mô hình sẽ cập nhật weight quá nhanh, dẫn đến việc “nhảy” qua điểm tối ưu và không thể hội tụ.
Ví dụ: Nếu bước chân quá lớn, bạn có thể bước hụt và ngã xuống dốc.
5. Không có Momentum
Khi không sử dụng momentum, SGD chỉ dựa trên gradient hiện tại để cập nhật weight. Điều này có thể khiến mô hình dao động xung quanh điểm tối ưu và khó hội tụ.
6. Có Momentum
Momentum giúp SGD “nhớ” các gradient trước đó và sử dụng thông tin này để cập nhật weight. Điều này giúp mô hình di chuyển mượt mà hơn và nhanh chóng hội tụ đến điểm tối ưu.
Ví dụ: Hãy tưởng tượng bạn đang lăn một quả bóng xuống dốc. Momentum giống như quán tính của quả bóng, giúp nó lăn nhanh hơn và vượt qua các chỗ lõm nhỏ.
7. Tóm tắt về Learning Rate và Momentum
- Learning rate quyết định “bước nhảy” khi cập nhật weight.
- Learning rate tối ưu giúp mô hình hội tụ nhanh chóng.
- Learning rate quá nhỏ hoặc quá lớn đều có thể gây ra vấn đề.
- Momentum giúp SGD di chuyển mượt mà hơn và nhanh chóng hội tụ.
Lựa chọn learning rate và momentum phù hợp là rất quan trọng để huấn luyện mạng nơ-ron hiệu quả.
5.4. Layers initialization, transfer learning and fine tuning
1. Khởi tạo Layer (Layer Initialization)
Khi khởi tạo mạng nơ-ron, các weight và bias thường được gán giá trị ngẫu nhiên. Tuy nhiên, việc khởi tạo weight không đúng cách có thể dẫn đến các vấn đề như vanishing gradient hoặc exploding gradient, làm chậm hoặc ngăn cản quá trình huấn luyện.
Layer initialization là kỹ thuật khởi tạo weight một cách thông minh để giúp mô hình học hiệu quả hơn. Một số phương pháp khởi tạo phổ biến bao gồm:
- Xavier/Glorot initialization: Khởi tạo weight sao cho phương sai của activation được giữ nguyên qua các layer.
- He initialization: Tương tự Xavier initialization, nhưng được thiết kế cho các hàm kích hoạt như ReLU.
Ví dụ:
import torch.nn as nn
linear = nn.Linear(10, 5)
nn.init.xavier_uniform_(linear.weight) # Khởi tạo weight bằng Xavier initialization
2. Transfer Learning và Fine-tuning
Transfer learning là kỹ thuật tận dụng kiến thức đã học từ một bài toán (source task) để giải quyết một bài toán khác (target task).
Ví dụ: Bạn đã huấn luyện một mô hình nhận dạng các loại hoa. Bây giờ bạn muốn xây dựng một mô hình nhận dạng các loại cây. Thay vì huấn luyện từ đầu, bạn có thể sử dụng lại các layer đầu của mô hình nhận dạng hoa (đã học được các đặc trưng chung về hình dạng, màu sắc) và chỉ huấn luyện lại các layer cuối cho bài toán nhận dạng cây.
Fine-tuning là một kỹ thuật trong transfer learning, trong đó ta “tinh chỉnh” lại toàn bộ hoặc một phần weight của mô hình đã được huấn luyện trước trên target task.
Các bước thực hiện transfer learning và fine-tuning:
- Lấy một mô hình đã được huấn luyện trước (pre-trained model) trên source task.
- Loại bỏ các layer cuối của pre-trained model (thường là các layer liên quan đến phân loại).
- Thêm các layer mới phù hợp với target task.
- Fine-tune toàn bộ hoặc một phần weight của mô hình trên target task.
Lợi ích của transfer learning và fine-tuning:
- Tăng tốc quá trình huấn luyện: Tận dụng kiến thức đã học, giúp mô hình hội tụ nhanh hơn.
- Cải thiện hiệu suất: Đặc biệt hữu ích khi target task có ít dữ liệu huấn luyện.
- Giảm thiểu overfitting: Mô hình đã được huấn luyện trước trên một tập dữ liệu lớn, giúp giảm overfitting trên target task.
Tóm lại:
- Layer initialization giúp khởi tạo weight một cách hiệu quả.
- Transfer learning và fine-tuning tận dụng kiến thức đã học để giải quyết bài toán mới.
Bằng cách sử dụng các kỹ thuật này, bạn có thể huấn luyện mạng nơ-ron hiệu quả hơn và đạt được kết quả tốt hơn.
Example
- Freeze layers of a model
for name, param in model.named_parameters():
# Check if the parameters belong to the first layer
if name == '0.weight' or name == '0.bias':
# Freeze the parameters
param.requires_grad = False
# Check if the parameters belong to the second layer
if name == '1.weight' or name == '1.bias':
# Freeze the parameters
param.requires_grad = False
- Layer initialization
layer0 = nn.Linear(16, 32)
layer1 = nn.Linear(32, 64)
# Use uniform initialization for layer0 and layer1 weights
nn.init.uniform_(layer0.weight)
nn.init.uniform_(layer1.weight)
model = nn.Sequential(layer0, layer1)
6. Evaluating and Improving Models
6.1. A deeper dive into loading data
Khi huấn luyện mô hình học máy, việc nạp dữ liệu hiệu quả là vô cùng quan trọng. PyTorch cung cấp hai công cụ mạnh mẽ để giúp bạn làm điều này: TensorDataset và DataLoader. Hãy cùng tìm hiểu chi tiết hơn về chúng nhé!
1. TensorDataset
Tưởng tượng bạn có một tập dữ liệu gồm các hình ảnh về mèo và chó. Mỗi hình ảnh được biểu diễn dưới dạng một ma trận pixel (tensor) và có một nhãn tương ứng (“mèo” hoặc “chó”). TensorDataset giúp bạn gói gọn các tensor hình ảnh và nhãn tương ứng thành từng cặp, giống như việc bạn ghép nối mỗi hình ảnh với nhãn của nó vậy.
Ví dụ:
import torch
from torch.utils.data import TensorDataset
# Giả sử bạn có 2 tensor:
# - image_tensors chứa các tensor hình ảnh
# - labels chứa các nhãn tương ứng (0 cho "mèo", 1 cho "chó")
dataset = TensorDataset(image_tensors, labels)
# Bây giờ bạn có thể truy cập từng cặp dữ liệu (hình ảnh, nhãn) thông qua chỉ số:
image, label = dataset[0] # Lấy hình ảnh và nhãn đầu tiên
2. DataLoader
DataLoader giống như một “người phục vụ” thông minh, giúp bạn nạp dữ liệu theo từng batch (nhóm) để huấn luyện mô hình. Nó có khả năng xáo trộn dữ liệu, chia dữ liệu thành các batch với kích thước bạn mong muốn, và thậm chí tải dữ liệu song song để tăng tốc quá trình huấn luyện.
Ví dụ:
from torch.utils.data import DataLoader
# Tạo DataLoader từ dataset đã tạo ở trên
dataloader = DataLoader(dataset, batch_size=32, shuffle=True)
# Duyệt qua từng batch dữ liệu:
for batch_idx, (images, labels) in enumerate(dataloader):
# images là một batch gồm 32 hình ảnh
# labels là một batch gồm 32 nhãn tương ứng
# ... (tiến hành huấn luyện mô hình với batch này)
Tóm lại:
TensorDataset: Gói gọn dữ liệu thành các cặp (features, labels).DataLoader: Nạp dữ liệu theo batch, xáo trộn, và tối ưu hóa quá trình huấn luyện.
Sử dụng kết hợp TensorDataset và DataLoader sẽ giúp bạn quản lý và nạp dữ liệu một cách hiệu quả trong PyTorch, từ đó cải thiện tốc độ và hiệu suất huấn luyện mô hình.
Example
- Using the TensorDataset class
import numpy as np
import torch
from torch.utils.data import TensorDataset
np_features = np.array(np.random.rand(12, 8))
np_target = np.array(np.random.rand(12, 1))
torch_features = torch.tensor(np_features)
torch_target = torch.tensor(np_target)
# Create a TensorDataset from two tensors
dataset = TensorDataset(torch_features, torch_target)
# Return the last element of this dataset
print(dataset[-1])
- From data loading to running a forward pass
# Load the different columns into two PyTorch tensors
features = torch.tensor(dataframe[['ph', 'Sulfate', 'Conductivity', 'Organic_carbon']].to_numpy()).float()
target = torch.tensor(dataframe['Potability'].to_numpy()).float()
# Create a dataset from the two generated tensors
dataset = TensorDataset(features, target)
# Create a dataloader using the above dataset
dataloader = DataLoader(dataset, shuffle=True, batch_size=2)
x, y = next(iter(dataloader))
# Create a model using the nn.Sequential API
model = nn.Sequential(
nn.Linear(4, 8),
nn.Linear(8, 1)
)
output = model(features)
print(output)
6.2. Evaluating model performance
Để hiểu cách đánh giá hiệu suất của một mô hình học máy (machine learning model), hãy tưởng tượng bạn đang dạy một chú chó (model) cách bắt bóng (task).
1. Training, Validation và Testing
- Training: Bạn cho chú chó xem bạn ném bóng và ra lệnh “bắt” nhiều lần (training data). Chú chó sẽ học cách nhận biết bóng và chạy theo nó.
- Validation: Thỉnh thoảng, bạn ném bóng nhưng không ra lệnh, xem chú chó có tự động chạy đi bắt không (validation data). Qua đó, bạn biết được chú chó đã học tốt đến đâu và có cần điều chỉnh cách dạy không.
- Testing: Cuối cùng, bạn đưa chú chó đến công viên (test data), nơi có nhiều người và vật khác, để kiểm tra xem chú chó có thực sự bắt bóng tốt trong môi trường mới không.
Tương tự, với mô hình học máy:
- Tập training (training set): Dùng để huấn luyện mô hình.
- Tập validation (validation set): Dùng để đánh giá mô hình trong quá trình huấn luyện và điều chỉnh các tham số (parameters) để cải thiện hiệu suất.
- Tập testing (test set): Dùng để đánh giá hiệu suất cuối cùng của mô hình trên dữ liệu mới, chưa từng thấy trước đó.
2. Model evaluation metrics (Các chỉ số đánh giá mô hình)
Để đánh giá chú chó bắt bóng tốt ra sao, bạn có thể dựa vào các chỉ số như:
- Số lần bắt được bóng / tổng số lần ném: Tỷ lệ này càng cao, chú chó càng bắt bóng tốt.
- Thời gian trung bình để bắt được bóng: Thời gian càng ngắn, chú chó càng nhanh nhẹn.
Tương tự, với mô hình học máy, có nhiều chỉ số đánh giá khác nhau, tùy thuộc vào bài toán cụ thể. Một số chỉ số phổ biến bao gồm:
- Accuracy (Độ chính xác): Tỷ lệ dự đoán đúng trên tổng số dự đoán.
- Precision (Độ chính xác): Trong số những lần dự đoán là “có”, có bao nhiêu lần dự đoán đúng.
- Recall (Độ nhạy): Trong số những trường hợp thực tế là “có”, mô hình dự đoán đúng được bao nhiêu lần.
- F1-score: Trung bình điều hòa giữa Precision và Recall.
3. Calculating training loss (Tính toán độ lỗi huấn luyện)
Trong quá trình dạy chú chó, bạn có thể la mắng khi nó bắt hụt bóng hoặc thưởng cho nó khi bắt được. “La mắng” và “thưởng” tương ứng với việc điều chỉnh mô hình dựa trên độ lỗi (loss). Độ lỗi cho biết mô hình đang dự đoán sai lệch so với kết quả thực tế bao nhiêu.
Calculating training loss: Tính toán độ lỗi trung bình của mô hình trên tập training data.
4. Calculating validation loss (Tính toán độ lỗi kiểm định)
Thỉnh thoảng, bạn cần kiểm tra xem chú chó có đang học đúng cách không bằng cách ném bóng mà không ra lệnh. Nếu chú chó không chạy đi bắt, bạn biết rằng cần phải điều chỉnh cách dạy.
Calculating validation loss: Tính toán độ lỗi trung bình của mô hình trên tập validation data. Giúp bạn theo dõi quá trình học của mô hình và phát hiện các vấn đề như overfitting (học thuộc lòng dữ liệu).
5. Calculating accuracy with torchmetrics (Tính toán độ chính xác với torchmetrics)
torchmetrics là một thư viện trong PyTorch cung cấp các hàm để tính toán các chỉ số đánh giá mô hình, bao gồm accuracy.
Ví dụ, để tính accuracy, bạn có thể sử dụng hàm torchmetrics.Accuracy().
import torchmetrics
# Khởi tạo metric
accuracy = torchmetrics.Accuracy()
# Tính toán accuracy cho mỗi batch dữ liệu
for batch in data_loader:
preds = model(batch)
accuracy.update(preds, targets)
# Tính toán và in ra accuracy cuối cùng
print(accuracy.compute())
Tóm lại, việc đánh giá hiệu suất mô hình là một bước quan trọng để đảm bảo mô hình hoạt động tốt và đáng tin cậy trên dữ liệu thực tế.
Example
- Writing the evaluation loop
# Set the model to evaluation mode
model.eval()
validation_loss = 0.0
with torch.no_grad():
for data in validationloader:
outputs = model(data[0])
loss = criterion(outputs, data[1])
# Sum the current loss to the validation_loss variable
validation_loss += loss.item()
# Calculate the mean loss value
validation_loss_epoch = validation_loss/len(validationloader)
print(validation_loss_epoch)
# Set the model back to training mode
model.train()
- Calculating accuracy using torchmetrics
# Create accuracy metric using torch metrics
metric = torchmetrics.Accuracy(task="multiclass", num_classes=3)
for data in dataloader:
features, labels = data
outputs = model(features)
# Calculate accuracy over the batch
acc = metric(outputs, labels.argmax(dim=-1))
# Calculate accuracy over the whole epoch
acc = metric.compute()
# Reset the metric for the next epoch
metric.reset()
plot_errors(model, dataloader)
6.3. Fighting overfitting
Hãy tưởng tượng bạn đang dạy một chú chó (model) nhận biết mèo (task). Bạn chỉ cho chú chó xem ảnh của những con mèo lông ngắn màu trắng (training data).
1. Reasons for Overfitting (Nguyên nhân gây ra Overfitting)
Chú chó học rất tốt, nhận ra tất cả những con mèo lông ngắn màu trắng bạn đưa ra. Tuy nhiên, khi bạn đưa ra ảnh một con mèo lông dài màu đen, chú chó lại không nhận ra đó là mèo. Đây chính là overfitting: mô hình học “quá khớp” với dữ liệu huấn luyện, dẫn đến không thể tổng quát hóa cho dữ liệu mới.
Nguyên nhân gây ra overfitting:
- Quá ít dữ liệu huấn luyện: Chú chó chỉ được xem một số lượng hạn chế các con mèo.
- Mô hình quá phức tạp: Chú chó cố gắng ghi nhớ từng chi tiết nhỏ của những con mèo lông ngắn màu trắng thay vì học những đặc điểm chung của loài mèo.
- Noise trong dữ liệu: Trong số ảnh bạn đưa ra, có thể có những ảnh không rõ ràng hoặc bị nhiễu, khiến chú chó học sai.
2. Fighting Overfitting (Chống lại Overfitting)
Để chú chó nhận biết được tất cả các loại mèo, bạn cần:
- Cho chú chó xem nhiều ảnh mèo đa dạng hơn: Mèo lông dài, mèo lông ngắn, mèo đen, mèo trắng, mèo tam thể… (Data augmentation)
- Không nên quá khắt khe trong việc bắt chú chó phải nhớ chính xác từng chi tiết: Chỉ cần chú chó nhận ra những đặc điểm chung của loài mèo là được. (Regularization)
- Loại bỏ những ảnh mèo không rõ ràng: Đảm bảo dữ liệu huấn luyện chất lượng cao.
3. “Regularization” using a Dropout layer (Chính quy hóa với Dropout layer)
Tưởng tượng bạn bịt mắt chú chó ngẫu nhiên trong quá trình huấn luyện. Điều này buộc chú chó phải học cách nhận biết mèo bằng nhiều giác quan khác nhau, thay vì chỉ dựa vào thị giác.
Dropout layer hoạt động tương tự: nó ngẫu nhiên “tắt” một số neuron trong mạng neural trong quá trình huấn luyện, buộc mô hình phải học cách sử dụng các neuron khác nhau và tránh phụ thuộc quá nhiều vào một số neuron cụ thể.
4. Regularization with Weight decay (Chính quy hóa với Weight decay)
Bạn có thể phạt chú chó nếu nó quá tập trung vào một đặc điểm nào đó của mèo, ví dụ như chỉ chú ý đến màu lông.
Weight decay thêm một “hình phạt” vào các trọng số (weights) của mô hình, ngăn chúng trở nên quá lớn. Điều này giúp mô hình đơn giản hơn và giảm overfitting.
5. Data augmentation (Tăng cường dữ liệu)
Bạn có thể “tạo” thêm nhiều ảnh mèo từ những ảnh ban đầu bằng cách xoay, lật, phóng to, thu nhỏ…
Data augmentation tạo ra các biến thể của dữ liệu huấn luyện, giúp tăng kích thước và sự đa dạng của dữ liệu, từ đó giảm overfitting.
Tóm lại, overfitting là một vấn đề phổ biến trong Machine Learning. Bằng cách áp dụng các kỹ thuật chống overfitting, chúng ta có thể xây dựng các mô hình tổng quát hóa tốt hơn và hoạt động hiệu quả trên dữ liệu thực tế.
6.4. Improving model performance
Hãy tưởng tượng bạn đang huấn luyện một vận động viên (model) chạy marathon (task). Mục tiêu là giúp vận động viên đạt thành tích tốt nhất trong cuộc thi.
Các bước để tối đa hóa hiệu suất (Steps to maximize performance)
Để đạt được điều này, bạn có thể áp dụng 3 bước sau:
Step 1: Overfit the training set (Làm cho mô hình overfit với tập huấn luyện)
Trước tiên, bạn cho vận động viên tập luyện rất chăm chỉ trên một đường chạy quen thuộc (training set). Vận động viên sẽ ghi nhớ từng khúc cua, từng đoạn dốc, từng điểm tiếp nước trên đường chạy này. Kết quả là, vận động viên đạt thành tích cực kỳ tốt trên đường chạy quen thuộc này.
Tương tự, với mô hình học máy, bước đầu tiên là cố gắng đạt được hiệu suất cao nhất có thể trên tập training data, kể cả khi điều đó dẫn đến overfitting.
features, labels = next(iter(trainloader))
for i in range(1e3):
outputs = model(features)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
Step 2: Reduce overfitting (Giảm overfitting)
Tuy nhiên, nếu chỉ chạy trên đường chạy quen thuộc, vận động viên sẽ gặp khó khăn khi thi đấu trên đường chạy marathon thực tế với địa hình và điều kiện khác biệt. Vì vậy, bạn cần cho vận động viên tập luyện trên nhiều đường chạy khác nhau, với độ dài, độ dốc, thời tiết… đa dạng.
Tương tự, với mô hình học máy, sau khi đạt được hiệu suất cao trên tập training, bạn cần áp dụng các kỹ thuật chống overfitting (như đã giải thích ở câu hỏi trước) để mô hình có thể tổng quát hóa tốt cho dữ liệu mới.
Step 3: Fine-tune hyperparameters (Tinh chỉnh siêu tham số)
Cuối cùng, bạn cần tinh chỉnh các yếu tố như chế độ dinh dưỡng, lịch trình tập luyện, loại giày chạy… để vận động viên đạt được hiệu suất tối ưu.
Tương tự, với mô hình học máy, bạn cần tinh chỉnh các hyperparameters (siêu tham số) như learning rate, số lượng layers, số lượng neurons… Các hyperparameters này không được học từ dữ liệu mà được thiết lập trước khi huấn luyện mô hình. Việc tinh chỉnh hyperparameters giúp “điều chỉnh” mô hình để đạt hiệu suất tốt nhất có thể.
Tóm lại, việc cải thiện hiệu suất mô hình là một quá trình lặp đi lặp lại, bao gồm việc overfit tập training, giảm overfitting và tinh chỉnh hyperparameters. Bằng cách áp dụng đúng các bước này, bạn có thể xây dựng được các mô hình học máy mạnh mẽ và hiệu quả.
Example
- Experimenting with dropout
model = nn.Sequential(nn.Linear(8, 4),
nn.ReLU(),
nn.Dropout(p=0.5))
- Implementing random search
values = []
for idx in range(10):
# Randomly sample a learning rate factor between 2 and 4
factor = np.random.uniform(2, 4)
lr = 10 ** -factor
# Randomly select a momentum between 0.85 and 0.99
momentum = np.random.uniform(0.85, 0.99)
values.append((lr, momentum))